一种基于ID分区的城市道路轨迹汇聚模式检测方法
- 国知局
- 2025-01-10 13:11:27
本发明属于计算机大数据,特别是涉及一种基于id分区的城市道路轨迹汇聚模式检测方法。
背景技术:
1、随着定位设备和全球卫星导航系统的高速发展,城市网络中的时空轨迹数据呈爆炸式增长。时空轨迹数据的分析和挖掘是轨迹数据挖掘领域的代表性工作。通过对时空轨迹数据的挖掘可以检测移动对象的行为特征,用于发现群体运动规律、群体运动趋势。其所揭示的群体运动行为在城市规划、交通运输等多个领域具有广阔的应用前景。
2、id分区技术是一种常用的数据处理技术,其通过识别和分析现有数据的特征,按照既定的标准对数据进行分区。这种分区方式使得后续的数据挖掘任务可以在每个分区中单独进行,从而提高挖掘效率。
3、在时空轨迹数据分析领域中,群体运动模式检测是一个关键的研究方向,现有的群体运动模式检测的工作主要基于欧式(平面)距离,这在有道路网络约束的城市空间中并不适用。汇聚模式是群体运动模式检测中的一个重要类别,用于发现群体运动对象的汇聚行为,例如庆祝活动、集会等。目前,针对移动对象轨迹数据的汇聚行为检测主要采用树结构来组织轨迹数据,通过遍历这些轨迹数据来构建和更新树结构,可以有效检测出汇聚行为。然而,随着轨迹数据规模的增大,树结构的构建和更新将成为算法效率的瓶颈。
4、因此,亟需一种有效的城市道路轨迹汇聚模式检测方法,以实现针对城市道路轨迹数据的汇聚模式进行高效检测。
技术实现思路
1、本发明实施例的目的在于提供基于id分区的城市道路轨迹汇聚模式检测方法,以解决现有的运动模式检测方法在有道路网络约束的城市空间中难以适用的问题。
2、为解决上述技术问题,本发明所采用的技术方案是,基于id分区的城市道路轨迹汇聚模式检测方法,包括以下步骤:
3、s1:对移动对象进行位置采样,收集轨迹样本数据;
4、s2:获取道路网络数据并进行预处理;
5、s3:对s1的轨迹样本数据进行离散化处理,生成时间快照;
6、s4:利用s2预处理后的道路网络数据和距离阈值d构建道路节点的vnindex索引结构;
7、s5:将s3中时间快照中的移动对象映射到s2预处理完成的道路网络数据中,并更新vnindex索引结构;并对时间快照中的移动对象进行聚类,并生成各分区;
8、s6:根据s5的分区生成候选汇聚模式,并识别出符合约束条件的汇聚模式。
9、进一步的,所述s1中每条轨迹样本数据包括:移动对象的唯一标识、位置坐标、采样时间。
10、进一步的,所述s2包括:
11、s2.1:使用qgis获取道路网络数据;
12、s2.2:在道路网络数据中,筛选道路边数据与道路节点数据;其中,每条道路边数据包括:该边的唯一标识、构成该边的两个道路节点的标识、道路长度;每个道路节点数据包括:该节点的唯一标识、经纬度、与该节点相连的边的集合。
13、进一步的,所述s3包括:
14、s3.1:统计轨迹样本数据中的采样时间间隔以及采样起止时间;
15、s3.2:将s3.1采样时间间隔中出现频率最高的采样时间间隔作为时间片长度,以采样起始时间为基点进行时间片划分;将位于同一时间片的移动对象构成一个快照,在一个快照中,每个移动对象只有一个位置坐标;不断根据时间片的长度划分下一个时间片,直到到达采样结束时刻,得到所有时间片快照,每个快照内移动对象的时间戳相同。
16、进一步的,所述s4包括:
17、s4.1:根据s2.2预处理获得的数据和距离阈值d,对每个道路节点连接的边集进行扩展,构建每个节点的道路网络索引即vnindex索引;每个节点的道路网络索引结构包括:此节点的安全边集、非安全边集、此节点到每个安全边、每个非安全边的距离;具体步骤介绍如下:
18、对于任意一个节点node1,其安全边集、非安全边集的构建过程具体为:
19、安全边集:对于节点node1连接的边edge1,如果edge1的长度不大于d,那么edge1是node1的安全边,节点node1至edge1的距离为edge1的长度;对于edge1另一个节点node2连接的边edge2,如果edge2的长度加上edge1的长度不大于d,那么edge2也是node1的安全边,节点node1至edge2的距离为edge1长度加上edge2的长度;继续扩展过程,直到扩展得到的所有边的长度之和超过d为止,在此过程中,边长度之和不超过d的所有边都为安全边,这些安全边构成节点node1的安全边集;因此,节点node1至安全边的距离为节点node1至此安全边的过程中所有安全边长度之和;
20、非安全边集:对于节点node1连接的边edge1,如果edge1的长度大于d,那么edge1为非安全边,节点node1至edge1的距离为edge1的长度;若在扩展过程中,edge1的长度不大于d,对于edge1另一个节点node2连接的边edge2,edge1加上edge2后,边长度之和超过d,那么edge2为非安全边,节点node1至edge2的距离为edge1长度加上edge2的长度;因此,对于edge2另一个节点node3连接的边edge3也为非安全边,后续那些加上其长度后所有边长度之和大于d的边都为非安全边,这些非安全边构成node1的非安全边集,节点node1到非安全边的距离为节点node1至此非安全边的过程中所有边长度之和;
21、同时,在扩展过程中要遵循以下原则:
22、(1)以节点node1、节点node2为两节点的边edge1,不论是从节点node1扩展到节点node2,还是以节点node2扩展到节点node1,此边为同一条边edge1;
23、(2)对于节点node1扩展得到的非安全边edge1,若在其他扩展过程中发现edge1是安全边,那么更新边edge1为安全边并更新节点node1到边edge1的距离,并在非安全边集中删除边edge1,同时删除节点node1到非安全边edge1的距离;
24、(3)对于节点node1的边edge1,在不同的扩展过程中节点node1至边edge1的距离以最小距离为准。
25、进一步的,所述s5包括:
26、s5.1:根据s2.2的道路边数据、道路节点数据及s3.2的时间片快照,对于快照中的每个移动对象,首先采用点到直线的距离计算公式,计算移动对象与所有道路边的距离,移动对象的坐标由s1移动对象的位置坐标获得,道路边的坐标由s2.2道路节点的经纬度坐标获得;接着选取距离最小的道路边,将移动对象映射到与其距离最近的边,即将移动对象的唯一标识、移动对象到最近的边的节点的距离加入s2.2的道路边数据中;
27、s5.2:根据s5.1的结果更新每个节点的vnindex索引,并计算每个移动对象o的邻居集,包括:
28、s5.2.1:对于s5.1的映射结果,每条边包含了映射到该边的对象集以及每个对象到该边的节点的距离;每个道路节点vnindex索引的更新方式为:对于每个道路节点,获取其每个安全边上的所有移动对象,对于非安全边上的移动对象仅获取与此道路节点距离不大于d的移动对象;
29、s5.2.2:筛选与o邻近的移动对象,构成o的邻居集;采取以下方法进行筛选:
30、对于移动对象o,在对应的道路节点的对象集中,
31、对于不在edge上的任一移动对象,计算此移动对象到道路节点的距离加上o到道路节点的距离,即得到此移动对象与o的距离,若不大于d则该对象与o邻近,否则不邻近;
32、对于在edge上的任一移动对象,计算此移动对象到道路节点的距离减去o到道路节点的距离的绝对值,若不大于d则该移动对象与o邻近,否则不邻近;
33、将这些与o邻近的对象组成o的邻居集;
34、s5.3:根据s5.2中得到的移动对象o的邻居集构建邻近关系图;
35、s5.4:将s5.3中构建的邻近关系图作为scan算法的输入进行聚类,得到聚类后的簇,每个簇包含多个移动对象,表示为:簇c={oi,oj…},其中oi,oj代表了群体中的各个移动对象,i,j表示移动对象的唯一标识;并对聚类得到的簇中的对象进行排序,排序标准为:按照移动对象的唯一标识从小到大排序,选取簇中第一个对象作为id分区标准进行分区,并将此簇添加到对应的分区中,依次将所有快照中的所有簇执行此操作。
36、进一步的,所述s6包括:
37、s6.1:对于s5.4得到的分区中的每个簇c,查询与c具有非id簇包含关系且符合时间间隔i约束的簇c′,并将c′补全到簇c所在的分区中;
38、簇包含关系ccr描述两个移动对象群体的汇聚行为,对于两个簇c1和c2,若c1中的全部移动对象都在c2中存在,则表明c2包含c1,即二者存在簇包含关系,记作表示为ccr(c1,c2);给定id为o的簇c1,c2,以及id为o'的簇c3,如果则c2和c1之间是id ccr,c3和c1是non-id ccr;
39、对于分区中的每个簇,将与簇c具有non-id ccr且符合时间间隔i约束的簇查询出来,查询公式如下:
40、non-id ccr-i(c,tc)={c′∈pc[o]|o=c[i](for i=2to|c|-μ+1),ccr(c,c′),tc′∈[t-i,tc-1]}
41、其中,non-id ccr-i(c,tc)表示与c具有non-id ccr且符合时间间隔i约束的簇的集合,即c′;tc表示c的时间戳;在查询过程中,t是一个表示时间的变量,初始时t为tc,tc′表示为c′的时间戳,t-i表示为c′的时间戳上限,tc-1表示c′的时间戳下限,[t-i,tc-1]表示为c′的时间约束,每查询到一次c′时,将t更新为tc′;pc[o]表示为id为o的分区即c的非id分区中的簇集,其中o为移动对象;c[i]表示为c中的第i个移动对象;|c|表示c中移动对象的个数,即簇c的规模;μ表示簇的规模阈值;ccr(c,c′)表示c与c′之间有簇包含关系;
42、s6.2:将s6.1得到的所有补全后的分区的时间序列进行sci约束的过滤操作,只保留同时符合sci约束的时间序列对应的簇;
43、对于一个簇列表cs={c1,...,cn},对应的时间序列t=[t1,…,tn],用sci=[s,c,i]来表示s,c,i的值;sci约束包括以下原则:
44、(1)持续原则:t的长度即t中元素的个数大于等于阈值s,即|t|≥s;
45、(2)连续原则:t中连续时间序列的长度大于等于阈值c,即t中存在一个子序列ts,满足ts[i+1]-ts[i]=1,且|ts|≥c,其中1≤i≤|ts|-1,i表示子序列ts中元素的序号,ts[i+1]表示ts中第i+1个元素,ts[i]表示ts中第i个元素,ts[i+1]-ts[i]=1表示ts中第i+1个元素所表示的时间戳与第i个元素所表示的时间戳的差值;|ts|表示为ts中时间戳的个数,即时间序列ts的长度;
46、(3)间隔原则:t中相邻时间戳的间隔小于等于阈值i,即t[i+1]-t[i]≤i,其中1≤i≤|t|-1,i表示t中元素的序号,t[i+1]表示t中的第i+1个元素,t[i]表示t中的第i个元素,|t|表示时间序列t的长度;
47、s6.3:对s6.2中过滤后的分区生成簇包含关系表,记录簇集中符合时间约束的簇之间的包含关系,时间约束为:时间戳在[t+1,t+i]之间;
48、s6.4:利用s6.3生成的簇包含关系表,采用正向递归、回溯递归两种搜索方法得到所有分区中所有的候选汇聚模式,筛选出符合约束条件的汇聚模式;包括:
49、s6.4.1:初始化标记簇列表markcs、簇列表cs、时间序列t、标记路径markpath、下一标记路径nextmarkpath;markcs用于记录正向递归、回溯递归中已访问的簇,递归结束后根据markpath更新markcs;簇列表cs用于记录候选汇聚模式中的簇;时间序列t用于记录簇列表cs中每个簇对应的时间戳,表示候选汇聚模式的时间序列;标记路径markpath用于记录正向递归、回溯递归过程中访问过的簇,在递归结束后将markpath中的元素合并到标记簇列表markcs中;下一标记路径nextmarkpath用来记录正向递归中新加入的簇也存在于另一簇包含关系时、回溯递归时访问过的簇,结束递归搜索时将nextmarkpath中的元素合并到标记路径markpath中;
50、s6.4.2:正向递归搜索:对于每个分区,遍历簇包含关系表中的簇,对于未访问过的簇,将其加入cs和标记路径markpath,其时间序列加入t;
51、根据簇包含关系表,获取与当前簇存在簇包含关系的第一个簇,检查此簇是否已被访问;若未被访问,则将它加入cs和markpath,其时间戳加入t;
52、若新加入的簇不存在另一簇包含关系中,结束正向递归搜索,得到候选汇聚模式mp=(cs,t);
53、若新加入的簇也存在于另一簇包含关系中,初始化下一标记路径nextmarkpath,继续进行正向递归搜索,将另一簇包含关系中的第一个簇加入到cs和nextmarkpath,其时间戳加入t,不断进行正向递归搜索,直至新加入的簇不在另一簇包含关系中,结束正向递归搜索,得到候选汇聚模式mp=(cs,t);
54、结束正向递归搜索后,将nextmarkpath中的元素合并到标记路径markpath中,来更新标记路径markpath;
55、s6.4.3:检查候选汇聚模式是否满足簇规模阈值m和sci约束的原则,并输出符合条件的模式;
56、若候选汇聚模式mp=(cs,t)同时满足以下条件:
57、(1)ci表示cs中第i个簇,ci+1表示cs中第i+1个簇;表示簇列表cs中的每个簇ci与其后面相邻簇ci+1之间存在包含关系;
58、(2)|cn|≥m;|cn|表示cs中第n个簇中移动对象的个数,即簇cn的规模;
59、(3)t满足sci约束;
60、则mp是汇聚模式,进行输出;
61、s6.4.4:回溯递归:根据s6.4.2得到的每个候选汇聚模式mp=(cs,t),选择候选汇聚模式的簇列表cs中最后一个簇cn,回溯到与其存在簇包含关系的上一个簇cn-1,检查与cn-1存在包含关系的簇是否被访问过,即在s6.4.2的markcs中检查与cn-1存在包含关系的簇是否被访问过,若未被访问过,重复s6.4.2-s6.4.3,搜索每个分区剩余所有候选汇聚模式,判断并输出每个分区内符合簇规模阈值m和sci约束的汇聚模式;
62、若直至回溯递归到候选汇聚模式cs的第一个簇c1都未出现未被访问过的簇,结束回溯递归搜索;将此过程访问过的簇加入下一标记路径nextmarkpath,并根据nextmarkpath更新markpath,将markpath中的元素合并到markcs中,更新markcs。
63、本发明的有益效果是
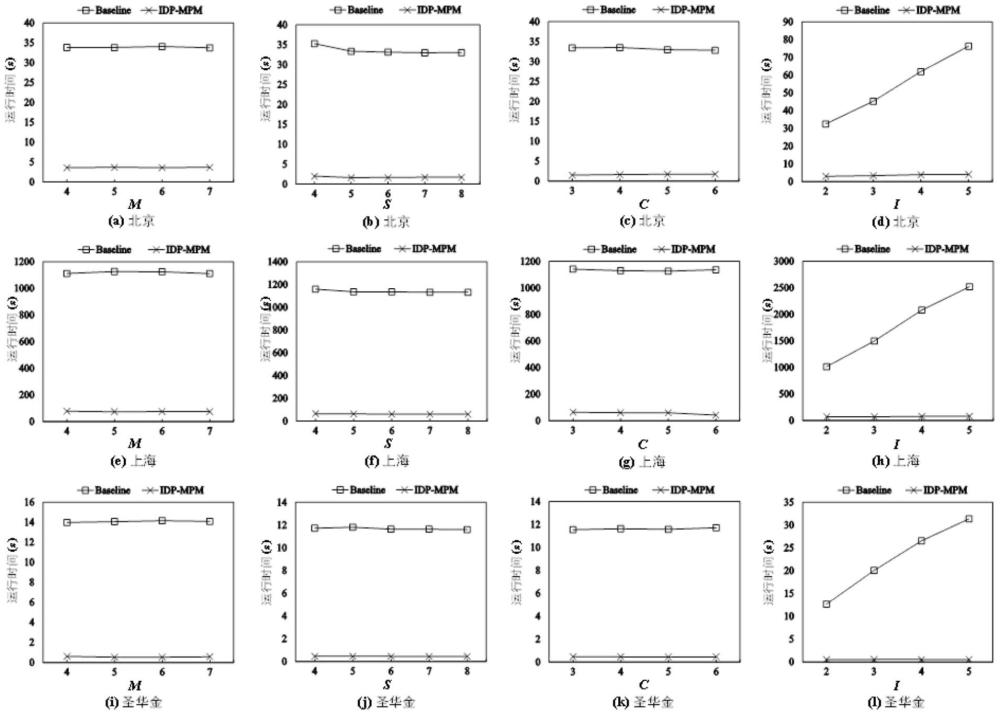
64、1,本发明在汇聚模式检测时以id分区为单位进行处理,通过将大规模数据划分为多个较小的分区,可以在每个分区内独立进行检测,从而加快整体检测的速度。
65、2,本发明引入了sci过滤操作,对各分区进行预处理,提前过滤掉不符合约束条件的分区,这样可以显著减少需要处理的数据量,提升检测效率。
66、3,本发明结合id分区技术、vnindex索引结构、簇包含关系、sci约束、正向递归、回溯递归搜索法,极大地提高了针对城市道路轨迹数据的汇聚模式的检测效率。
本文地址:https://www.jishuxx.com/zhuanli/20250110/351526.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表