一种基于深度强化学习的多交叉口信号协同控制方法
- 国知局
- 2025-01-10 13:19:44
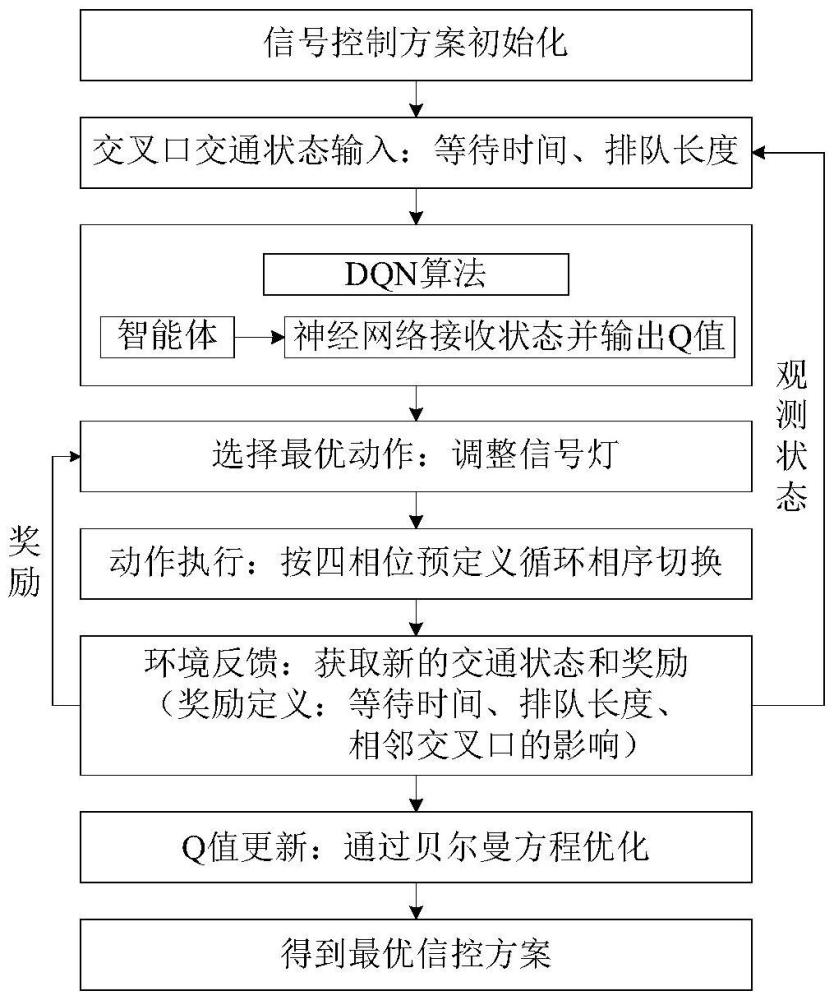
本发明属于交通工程和交通信息及控制系统领域,涉及多交叉口信号协同控制,更具体地说,涉及一种基于深度强化学习的多交叉口信号协同控制方法。
背景技术:
1、交通信号配时优化的研究大多基于优化模型的算法。随着智能交通技术的发展,基于多智能体的深度强化学习(deep reinforcement learning,drl)方法在交通信号控制领域引起了广泛关注。通过将每个交叉口视为独立的智能体,利用反馈学习和信息共享,实现信号联动控制,增强了交通系统的整体运行效率。
2、在基于深度强化学习的多交叉口信号协调控制框架中,智能体通常代表交通信号灯,环境则对应设有信号灯的交叉口。每个智能体根据交通状态(如车辆位置、速度、队列长度等)做出决策,旨在通过最大化整体奖励(如减少车辆等待时间)来优化信号控制。多项国内外研究表明,采用深度强化学习技术可以有效提升交通信号控制的协调性和适应性。例如,nishi等人通过图卷积神经网络提取路网几何特征,并结合神经拟合q迭代算法实现了分布式信号控制(ieee,2018:877-883);chu等人提出了多智能体a2c算法,通过混合奖励函数优化相邻交叉口的信号控制(ieee transactions on intelligent transportationsystems,2019,21(3):1086-1095);huo等人在v2x环境下采用了端到端学习模型,实现了高效的交叉口协同控制。
3、尽管这些方法取得了一定成效,但大多针对单个或相邻交叉口,多交叉口的信号控制仍然面临着模型复杂性高、控制策略不稳定等问题。为此,本发明提出了一种基于深度强化学习的多交叉口信号协同控制方法,通过显式策略调节函数和参数共享机制,提升了策略选择的可解释性,并降低了算法的复杂性和噪声影响。该算法采用排队长度和等待时间作为状态变量,信号相位作为动作空间,并将相邻交叉口的影响纳入奖励函数中。该技术的提出为交通信号配时优化提供了一种新的解决方案,特别适用于高峰时段交通流量复杂的多交叉口协同控制场景。
技术实现思路
1、技术问题:针对现有基于深度强化学习的多交叉口信号控制存在着模型复杂性高,策略选择的可解释性不强等不足,本发明的目的是提供一种基于深度强化学习的多交叉口信号协同控制方法,通过引入显式策略调节函数和参数共享机制,提高算法策略选择的可解释性并减少其复杂性和噪声影响,实现多交叉口信号协同控制,降低平均排队长度和平均等待时间,提高交通效率。
2、技术方案:为解决上述技术问题,本发明的基于深度强化学习的多交叉口信号协同控制方法,包括如下步骤:
3、步骤1:构建包含等待时间、排队长度、相邻交叉口影响的综合奖励函数,以多交叉口信号控制系统的综合奖励函数最大化为目标构建数学模型;
4、步骤2:通过引入显式策略调节函数,设计显式策略调节深度q网络协同控制算法;
5、步骤3:采用随机梯度下降方法调整可调策略函数的参数;
6、步骤4:通过设计参数共享机制,动态调整路网中各交叉口的信号控制策略,实现多交叉口协同优化控制。
7、步骤1中的综合奖励函数计算方法包括如下步骤:
8、步骤11:以多交叉口交通信号控制系统的奖励函数总和最大化为目标,如公式(1)所示:
9、
10、式中:表示每个信号灯的综合奖励函数,s表示信号灯集合,其中每个信号灯s∈s;
11、每个信号灯的综合奖励函数由等待时间的负奖励rs、排队长度的负奖励以及相邻交叉口的影响三部分之和,如公式(2)所示:
12、
13、其中,等待时间的负奖励rs由公式(3)计算:
14、
15、式中:li表示交叉口i的车道集合,w(l)表示每条车道l的等待时间;
16、排队长度的负奖励由公式(4)计算:
17、
18、式中:交通运动(l,m)表示从进口道的车道l到出口道的车道m的过程,p(l,m)表示车道级交通运动的压力,p(l,m)由公式(5)计算:
19、
20、式中,表示一条车道的车辆密度,其中n(l)为车道l上的车辆数量,c(l)为车道l的最大容量;
21、相邻交叉口的影响由公式(6)计算:
22、
23、式中,qwi表示交叉口i的排队长度和等待时间的加权和,由公式(7)计算:
24、
25、式中,q(l)为每个车道l的排队长度,w(l)为车道l的等待时间,li表示每个交叉口i的车道集合。
26、步骤2中的设计显式策略调节深度q网络协同控制算法,包括如下步骤:
27、步骤21:引入显式的可调节策略函数g(s,a;θ),在函数中,s表示当前状态,包括交通流量、当前信号灯状态;a表示改变信号灯状态的可选动作,θ是可调节函数的参数;通过优化策略函数g的参数θ,决定在给定状态下基于q函数的最优动作选择;对于一个给定状态s和动作a,当该动作是q函数的最优选择,目标值为1;否则,目标值为0。
28、步骤3中的采用随机梯度下降方法调整可调策略函数的参数θ,包括如下步骤:
29、步骤31:使用softmax函数将策略函数g(s,a;θ)的输出转化为概率分布,使得每个可能动作的选择概率与对应的q值成正比,如公式(8)所示:
30、
31、式中:π(a|s;θ)表示状态s下选择动作a的概率;
32、步骤32:损失函数用来度量策略函数g输出的q值和目标q值之间的差距,huber损失函数l(θ)如公式(9)所示:
33、
34、式中:q(si,ai;θ)是预测的q值;n表示样本数量,用于计算损失的数据批次的大小;yi是目标q值,通常通过贝尔曼方程(10)计算:
35、yi=ri+γmaxa′q(si+1,a′;θ-) (10)
36、式中:ri是即时奖励,γ折扣因子,介于0和1之间,用于衡量未来奖励的权重,越接近1,未来奖励的重要性越高表示未来奖励的;maxa′q(si+1,a′;θ-)表示在下一个状态si+1下选择动作a′所能获得的最大q值,代表最优策略下的最大期望累计奖励,θ-是目标网络的参数,si+1是执行动作后转移到的新状态;
37、步骤33:使用损失函数的梯度更新参数,以最小化损失函数的值,通过计算损失函数的梯度,逐步调整网络的权重,使得损失函数的值逐渐减小,最终使得网络输出的预测值更接近目标值,如公式(11)所示:
38、
39、其中,η是学习率,是损失函数对参数θ的梯度;softmax函数将神经网络的输出转化为概率分布,用于选择动作;损失函数衡量softmax输出的预测结果与目标q值之间的差距;随机梯度下降利用损失函数计算的误差,通过梯度下降法更新神经网络softmax层的参数。
40、步骤4中的参数共享机制设计方法,包括如下步骤:
41、步骤41:首先,每个交叉口的智能体基于车流量、排队长度、相位时长的本地状态独立学习和决策,快速适应其所处的局部交通环境;其次,通过评估相邻交叉口之间上下游排队长度的差异,动态调整信号配时参数,确保交叉口之间的交通流量平衡,减少交叉口间的车辆排队和拥堵现象;通过设计共享策略网络和全局超参数,减少个体智能体的模型复杂度,避免重复计算缩短训练时间;最后,各个交叉口的智能体通过共享经验回放缓冲区,在训练过程中相互学习不同交叉口的信号相位选择经验,利用其他交叉口的决策经验来改进自身策略,提升策略的全局最优性,实现更高效的交通信号控制策略。
42、有益效果:本发明与现有技术相比,具有以下优点:
43、区别于现有的基于深度强化学习的交叉口信号协同控制技术在奖励函数设计主要关注车辆延误、队列长度、行程时间、以及绿波协调等因素,忽视了多交叉口系统中相邻交叉口间的相互影响。本发明在构建综合奖励函数时,创新性地引入了相邻交叉口间的相互影响因素,同时结合车辆等待时间和排队长度的动态变化,对复杂交通流进行更为精细化的控制。
44、其次,针对现有研究中策略调节函数通常仅采用如动态调整探索率(如ε-贪婪策略)等调节方法,本发明提出了一种显式策略调节机制,通过设计显式策略调节的深度q网络(deep q-network,dqn)协同控制算法,提升了策略优化的可解释性和稳定性。
45、此外,本发明针对多交叉口的协同优化控制,设计了一种参数共享机制,使得各交叉口能够在复杂多变的交通环境中共享关键信息,进行信号控制策略的动态调整。这一机制有效降低了多交叉口系统中的计算复杂度,增强整个路网系统的协同性与鲁棒性,显著减少交通延误,提升路网的整体通行能力。
本文地址:https://www.jishuxx.com/zhuanli/20250110/352433.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表