一种AIGC多模态视听内容创作方法及系统
- 国知局
- 2025-01-17 13:01:41
本发明涉及多模态视听内容生成与自动化创作的,尤其是涉及一种aigc多模态视听内容创作方法及系统。
背景技术:
1、随着生成式人工智能(aigc,ai-generated content)技术的快速发展,基于深度学习的内容生成技术已经在多个领域取得了显著进展。现有的aigc技术,如文本生成图像、视频生成、音乐生成和语音合成,已经分别得到广泛应用。例如,文本生成图像技术通过生成对抗网络(gan)和扩散模型,可以将自然语言文本转换为高质量的图像;视频生成技术则利用深度学习模型生成短视频片段;音乐生成技术能够根据指定的情感或节奏自动生成音乐;语音合成技术(tts)也广泛用于虚拟助手和视频配音等场景。
2、尽管这些单一模态的生成技术取得了重大进展,但在多模态视听内容创作方面,现有技术仍存在诸多不足。首先,现有系统大多只能处理单一模态(如图像、视频或音频)的生成,缺乏跨模态协同工作的能力,不同模态的创作工具往往是独立的,导致在创作过程中需要人工干预来整合和对齐多模态信息,增加了创作成本和时间。
3、现有技术在处理多模态信息的融合和对齐时,也存在很大的技术挑战。视听内容创作通常需要融合文本、图像、音频和视频等多种模态信息,但由于不同模态在语义和时序上的差异,现有系统难以实现自动化的多模态对齐,容易导致生成的内容在节奏、语义或情感上不一致,影响了整体创作效果。
4、同时,视频内容的生成不仅涉及素材的制作,还需要进行复杂的编辑操作,如镜头拼接、镜头切换、转场效果等。目前的aigc技术大多集中于素材生成,缺乏对后期编辑过程的支持,用户需要手动完成这些操作,极大地降低了创作的自动化程度和效率最后,现有生成系统在生成复杂叙事性内容时,往往难以保证内容的连贯性和一致性。特别是在视频生成领域,现有技术生成的片段通常缺乏清晰的叙事结构,镜头之间的转场和衔接不够自然,影响了最终作品的流畅性和观感。
5、因此,现有技术在多模态内容生成、融合与编辑方面存在明显不足,迫切需要一种能够集成多模态生成技术、自动实现信息对齐与融合,并且支持智能化编辑和拼接操作的系统,以提升多模态视听内容创作的效率和质量。
技术实现思路
1、本发明的目的是提供一种aigc多模态视听内容创作方法及系统,解决现有技术中多模态视听内容创作存在的缺乏跨模态协同工作的能力,多模态信息融合和对齐时生成的内容在节奏、语义和情感上不一致,缺乏后期编辑过程的支持,内容衔接时不够自然,创作速度慢的问题。
2、为实现上述目的,本发明提供了一种aigc多模态视听内容的创作方法,包括以下步骤:
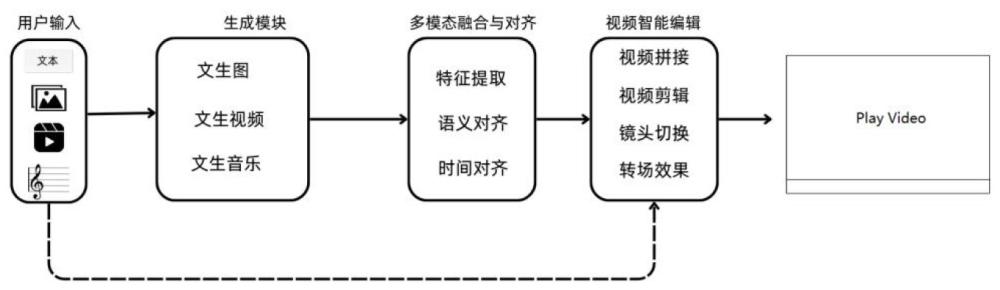
3、s1,用户输入文本描述和素材,素材包括图像、视频片段及音乐;
4、s2,使用gpt-4对文本描述进行分析和优化,再通过稳定扩散xl模型将优化和分析后的文本描述转化为若干个图像;
5、s3,使用稳定视频扩散模型将s2中得到的图像与素材中包含的图像扩展为若干个视频序列;
6、s4,使用自然语言处理技术对文本描述中的关键词和重要信息进行分析,再将关键词和重要信息输入suno,suno将关键词和重要信息解析,而后生成音乐片段;
7、s5,将文本描述、视频序列和音乐片段进行分析和同步,使其在内容和时间上保持一致,得到若干个音视频;
8、s6,使用短到长视频扩散模型将若干个音视频衔接到一起,得到一个长音视频;
9、s7,将生成的长音视频输出为用户想要的媒体格式。
10、优选的,s1中,用户输入的信息中必须输入文本描述,选择性输入素材。
11、优选的,s4中,suno生成音乐片段后,将suno生成的音乐片段反馈给用户,用户根据实际需求,通过更改文本描述对音乐片段进行修改。
12、优选的,s5的过程为先进行多模态特征对齐,再进行时间对齐,s5的具体步骤为:
13、s51,将文本描述输入预训练的语言模型,提取文本描述中的语义特征,捕捉文本中关于情感、主题以及风格的信息;
14、s52,使用残差卷积神经网络模型对s3中生成的视频序列和素材中的视频分成若干个视频帧,进行帧提取和视觉特征提取;
15、s53,使用3d卷积神经网络模型和长短时记忆模型提取s3中生成的视频序列和素材中的视频的动态特征,并将动态特征作为视频的时序信息;
16、s54,将素材中的音乐和s4中生成的音乐片段分割为与视频帧同步的短片段,再使用梅尔频谱图和梅尔频率倒谱系数提取模型提取素材中的音乐和s4中生成的音乐片段的频率、节奏和音调特征;
17、s55,使用共享嵌入空间的方法对齐文本描述、视频和音乐的特征进行特征对齐;
18、s56,使用音视频转换器模型对文本描述、视频和音乐的特征进行时间对齐得到若干音视频。
19、优选的,s55中,在共享嵌入空间中使用对比学习优化模型对文本描述、视频和音乐的特征进行处理,使相似的特征距离更近,不相似的特征距离更远。
20、优选的,s6中,使用自然语言处理模型解析文本描述,提取文本描述中与过渡相关的关键信息,将关键信息输入短到长视频扩散模型,生成满足客户需求的过渡帧。
21、本发明还提供了一种aigc多模态视听内容创作系统,使用上述aigc多模态视听内容的创作方法,包括
22、输入模块,用于用户输入创作所需要的文本描述和素材,素材包括图像、视频片段及音乐;
23、aigc生成模块,用于将用户输入的文本描述和素材转换为符合需求的视频序列以及音乐片段;
24、多模态融合与对齐模块,用于融合和对齐生成的视频序列和音乐片段,使视频序列和音乐片段之间的语义和时序具有一致性,得到音视频;
25、视频智能编辑模块,用于拼接音视频的片段,调整若干个音视频之间的过渡帧,保持视觉上的连贯性和两个音视频之间的连接;
26、输出模块,用于将生成的音视频输出为用户需要的媒体格式。
27、因此,本发明采用上述结构的一种aigc多模态视听内容创作方法及系统,具有以下有益效果:
28、(1)本发明系统集成了文本生成图像、视频生成、音乐生成等多种生成式人工智能技术,能够从单一输入生成多种模态的视听内容,大幅简化了创作流程,减少了人工干预,实现了视听内容的自动化生成;
29、(2)本发明系统通过多模态信息的融合与对齐技术,确保不同模态内容在语义和时间上的一致性和连贯性,解决了现有技术中多模态信息难以自然整合的问题,使生成的视听内容更加流畅和协调;
30、(3)本发明提供了智能化的视频编辑功能,自动完成视频拼接、镜头切换和转场效果生成,提高了内容创作的效率和质量;系统根据视频情节自动调整镜头过渡和特效生成,使得视频更加自然流畅,减少了用户在后期编辑中的工作量;系统通过智能化的编辑流程,系统能够在极短的时间内完成高质量的内容创作;
31、(3)本发明系统还具备强大的灵活性和定制化能力,用户可以根据具体需求调整生成内容的风格、格式和时长,满足不同创作场景的需求,适用于多个领域,提升了多模态视听内容的创作效率与质量,降低了创作门槛,实现了高效、低成本且高度个性化的视听内容创作。
32、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本文地址:https://www.jishuxx.com/zhuanli/20250117/355957.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表