1.本发明属于数据库技术领域,具体涉及一种数据缓存方法、装置、计算机设备和可读介质。
背景技术:
2.随着springboot框架,mybatis框架,redis(remote dictionary server,远程字典)等技术的成熟,互联网项目越来越多的从spring struct2 hibernate架构,向spring springmvc mybatis的架构迁移,或者直接使用ssm (spring springmvc mybatis)框架集作为项目架构。另一方面,在大数据、高并发、分布式的环境下,原有的本地缓存技术也逐渐被分布式缓存所取代。分布式缓存解决了原来各个服务器之间缓存不一致的弊端,提高了缓存的整体利用效率,节省了缓存的总空间量,这就对程序开发人员提出了更高的要求。
3.目前,在进行数据库查询操作时,程序开发人员需手动将查询到的数据缓存在分布式缓存中,以便下次查询时直接从分布式缓存中获取数据。在数据库变更时,程序开发人员需根据存储时的key在分布式缓存中手动删除相应的数据。这样的缓存维护,在包括上百张表的项目中,经常会出现数据在分布式缓存中已添加,但忘记删除的情况。或者,由于程序开发人员技术参差不齐产生代码漏洞,导致分布式缓存查询失败时,直接返回异常数据的情况。这种手动维护缓存的方式,在项目交接给下一个维护的团队,或者程序开发人员技术较为薄弱时,弊端尤为明显。
技术实现要素:
4.本发明旨在至少解决现有技术中存在的技术问题之一,提供一种可靠性高、效率高、灵活性强的数据缓存方法、装置、计算机设备和可读介质。
5.第一方面,本发明实施例提供一种数据缓存方法,所述方法包括:
6.接收针对数据库的数据操作指令,获取所述数据操作指令所调用方法的全限定名;
7.根据所述全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀;
8.响应于在本地缓存中查询到所述全限定名对应的rediskey变量名和 rediskey变量的前缀,确定所述rediskey变量名对应的变量值,并根据所述前缀和所述变量值得到rediskey变量;
9.在分布式缓存中对所述rediskey变量对应的数据执行与所述数据操作指令相对应的操作。
10.第二方面,本发明实施例还提供一种数据缓存装置,包括接收模块、获取模块、第一处理模块和第二处理模块,所述接收模块用于,接收针对数据库的数据操作指令,获取所述数据操作指令所调用方法的全限定名;
11.所述获取模块用于,根据所述全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀;
12.所述第一处理模块用于,响应于在本地缓存中查询到所述全限定名对应的 rediskey变量名和rediskey变量的前缀,确定所述rediskey变量名对应的变量值,并根据所述前缀和所述变量值得到rediskey变量;
13.所述第二处理模块用于,在分布式缓存中对所述rediskey变量对应的数据执行与所述数据操作指令相对应的操作。
14.第三方面,本发明实施例还提供一种计算机设备,包括:
15.一个或多个处理器;
16.存储装置,其上存储有一个或多个程序;
17.当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如前所述的数据缓存方法。
18.第四方面,本发明实施例还提供一种计算机可读介质,其上存储有计算机程序,其中,所述程序被执行时实现如前所述的数据缓存方法。
附图说明
19.图1为本发明实施例的数据缓存方法流程示意图一;
20.图2为本发明实施例的数据缓存方法流程示意图二;
21.图3为本发明实施例的基于数据查询指令在分布式缓存中对数据进行操作的流程示意图;
22.图4为本发明实施例的基于数据修改指令在分布式缓存中对数据进行操作的流程示意图;
23.图5为本发明实施例的数据修改指令下在分布式缓存中实现双删机制的流程示意图;
24.图6为本发明实施例的数据修改指令下确定rediskey变量的前缀的流程示意图;
25.图7为本发明实施例的数据缓存装置的结构示意图一;
26.图8为本发明实施例的数据缓存装置的结构示意图二。
具体实施方式
27.为使本领域技术人员更好地理解本发明的技术方案,下面结合附图和具体实施方式对本发明作进一步详细描述。
28.除非另外定义,本公开使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本公开中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,“一个”、“一”或者“该”等类似词语也不表示数量限制,而是表示存在至少一个。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
29.本发明实施例提供一种数据缓存方法,所述方法通过插件方式实现,为实现本发
明实施例,做以下定义:
30.1、在springboot项目的pom.xml文件中引入maven(项目构建管理)依赖,具体代码如下:
31.《dependency》
32.《groupid》com.boe.middleware《/groupid》
33.《artifactid》mybatisredisplugin《/artifactid》
34.《version》0.0.1-snapshot《/version》
35.《/dependency》
36.2、springboot项目中所有的selectbyprimarykey调用方法或具有@ redisadd注解的调用方法会自动添加到分布式缓存(redis缓存)。
37.rediskey变量由2部分组成,rediskey前缀和rediskey变量值(该变量值默认为数据库id),中间用“:”分隔,例如,user:1。
38.3、springboot项目中所有包含deletebyprimarykey或updatebyprimarykey 的调用方法,或者有@redisdelete注解的调用方法,会自动删除分布式缓存。
39.4、如果希望某个默认的调用方法不对分布式缓存进行操作,可以关闭这个功能(插件)。
40.selectbyprimarykey调用方法可以添加@redisadd(ignore=true)。
41.updatebyprimarykey/deletebyprimarykey调用方法可以添加 @redisdelete(ignore=true)。
42.5、如果希望全局关闭分布式缓存操作功能,有以下两种方法:
43.方法一:在可以成为bean的类上添加@enablemybatisredis(false)注解来关闭自动增删分布式缓存的功能。
44.方法二:在配置文件中配置mybatis.redis.enable=false。
45.这两种其中任意一种配置false,则插件不生效。
46.6、可以通过设置注解中的rediskeyprefix属性来定义分布式缓存的前缀。可以设置rediskeyindex属性来定义rediskey变量所对应的编号。通过设置 redisdelete中的redisaddmethod值,还可以自己指定添加分布式缓存的函数,以便直接解析出rediskey。具体注解定义如下:
47.@redisadd(rediskeyprefix="redis前缀",rediskeyindex="redis key的编号所对应的变量名,默认为id")
48.@redisdelete(rediskeyprefix="redis前缀",rediskeyindex="redis key的编号所对应的变量名,默认为id",
49.redisaddmethod="添加redis的函数名,默认为selectbyprimarykey")
50.本发明实施例进行以下配置:
51.1、利用spring spi机制,在插件项目的resource/meta-inf目录下添加 spring.factories文件,并指定插件要加载的自动配置类。其中, mybatisredisautoconfiguration为自动配置类,redisctrl类是对redission客户端使用的一个封装。
52.2、定义mybatisredisautoconfiguration类,该类为自动配置的标志类。
53.在类上添加@conditional(mybatisrediscondition.class)注解,通过读取配置文件和@enablemybatisredis的配置,决定是否加载本插件。
54.在类上添加@import({mybatisredispluginconfigmanager.class, mybatisredisaddinterceptor.class,mybatisredisdelinterceptor.class})。在spring 容器中,引入这3个类。
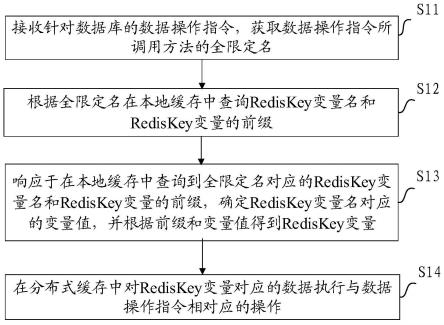
55.3、定义mybatisredisaddinterceptor类,该类为添加分布式缓存的核心类。
56.该类实现了interceptor接口。并添加了@intercepts和@signature注解指定了只有当用户调用数据库的查询方法时候,才会执行这个拦截器的intercept方法。
57.4、定义mybatisredisdelinterceptor类,该类为删除分布式缓存的核心类。
58.本发明实施例涉及两个缓存:本地缓存和分布式缓存(redis缓存),本地缓存和分布式缓存均是以key-value格式存储数据,本地缓存中记录调用方法的全限定名、rediskey变量名、rediskey变量的前缀之间的对应关系,key为正在执行的调用方法的全限定名,value为rediskey变量的前缀和rediskey变量的变量名。分布式缓存记录rediskey变量的变量值与数据的对应关系,key为: rediskey变量的变量值,value为数据(即对数据库操作的执行结果)。
59.本发明实施例提供的数据缓存方法,如图1所示,所述方法包括以下步骤:
60.步骤11,接收针对数据库的数据操作指令,获取数据操作指令所调用方法的全限定名。
61.在一些实施例中,针对数据库的数据操作指令可以包括数据查询指令和数据修改指令,数据修改指令可以包括数据更新指令和数据删除指令,不同的数据操作指令对应不同的调用方法,
62.在本步骤中,确定数据操作指令对应的调用方法,并在数据库的入参中获取这些调用方法的全限定名(fullname)。
63.步骤12,根据全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀。
64.在本公开实施例中,利用本地缓存存储rediskey变量的变量名和前缀,这样可以省略对调用方法的再次解析,提高处理效率。
65.步骤13,响应于在本地缓存中查询到全限定名对应的rediskey变量名和 rediskey变量的前缀,确定rediskey变量名对应的变量值,并根据前缀和变量值得到rediskey变量。
66.若在本地缓存中查询到全限定名对应的rediskey变量名和前缀,说明在之前的数据库操作中曾经调用过相同的调用方法,本次调用就无需再解析调用方法,而是可以直接查询得到对应的rediskey变量名和前缀。
67.在一些实施例中,所述确定rediskey变量名对应的变量值包括:采用java 发射机制,在数据库的入参中确定rediskey变量名对应的变量值。
68.步骤14,在分布式缓存中对rediskey变量对应的数据执行与数据操作指令相对应的操作。
69.在本步骤中,若数据操作指令为数据查询操作,则在分布式缓存中对 rediskey变量对应的数据执行查询操作;若数据操作指令为数据修改操作,则在分布式缓存中对
rediskey变量对应的数据执行删除操作。
70.本发明实施例提供的数据缓存方法,利用本地缓存存储调用方法对应的 rediskey变量名和前缀,在进行针对数据库的数据处理过程中,可以省略对调用方法的再次解析,提高处理效率。在进行针对数据库的数据处理过程中,确定rediskey变量名对应的变量值,以得到rediskey变量,并根据rediskey变量存储从数据库中获取到的数据,在处理数据库数据的同时,自动对分布式缓存中的数据进行维护,提高系统可靠性和数据处理效率,降低对程序开发人员的依赖。本发明实施例只需要开发人员引入相关依赖,无需改动任何代码和配置即可使用,代码入侵性为零;而且可以根据需求开启或关闭对分布式缓存的维护功能,或只单独关闭某个调用方法的查询功能,使用灵活、方便。
71.在一些实施例中,在获取数据操作指令所调用方法的全限定名(即步骤11) 之后,根据全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀 (即步骤12)之前,还包括以下步骤:步骤11’,判断全限定名是否在忽略列表中。相应的,所述根据全限定名在本地缓存中查询rediskey变量名和rediskey 变量的前缀(即步骤12),包括:响应于全限定名不在忽略列表中,根据全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀。
72.在一些实施例中,在判断全限定名是否在忽略列表中(即步骤11’)之后,所述数据缓存方法还包括以下步骤:步骤12’,响应于全限定名在忽略列表中,在数据库中执行数据操作指令对应的操作。
73.也就是说,在获取数据操作指令所调用方法的全限定名之后,先不查询本地缓存,而是先查询忽略列表,如果本次数据操作所调用的调用方法在忽略列表中,就不再对分布式缓存进行操作,而是直接利用执行器进行数据库的操作。如果本次数据操作所调用的调用方法不在忽略列表中,就对分布式缓存和数据库均进行操作。通过设置忽略列表,可以进一步提高数据处理效率,忽略列表中的调用方法(即调用方法对应的全限定名)可以由用户自行添加、修改,使用更为灵活、方便。
74.在一些实施例中,如图2所示,在根据全限定名在本地缓存中查询rediskey 变量名和rediskey变量的前缀(即步骤12)之后,所述数据缓存方法还可以包括以下步骤:
75.步骤21,响应于在本地缓存中未查询到全限定名对应的rediskey变量名和 rediskey变量的前缀,获取全限定名对应的rediskey变量名和rediskey变量的前缀。
76.在本步骤中,在本地缓存中未查询到全限定名对应的rediskey变量名和 rediskey变量的前缀,说明在之前的数据库操作中没有调用过相同的调用方法,本次调用就需要解析该调用方法得到相应的rediskey变量名和rediskey变量的前缀。后续分别针对数据查询指令和数据修改指令对获取rediskey变量名和 rediskey变量的前缀的过程进行详细说明。
77.步骤22,响应于确定出需要在分布式缓存中对rediskey变量对应的数据进行操作,将rediskey变量名和rediskey变量的前缀存储在本地缓存中。
78.在本步骤中,当数据操作指令为数据查询指令时,解析@redisadd注解(即第一注解)获取rediskey前缀、redis变量名和ignore属性。若ignore属性的值=false,或者,获取到@redisadd注解对应的调用方法,或者,未获取到@redisadd注解对应的调用方法但定义了预设调用方法(selectbyprimarykey 方法),则需要在分布式缓存中对rediskey变量对
应的数据进行操作。
79.当数据操作指令为数据修改指令时,解析@redisdelete注解(即第二注解) 获取rediskey前缀、redis变量名、ignore属性和调用方法属性(redisaddmethod 属性)。若ignore属性的值=false,或者,获取到@redisdelete注解对应的方法,或者,未获取到@redisdelete注解对应的方法但定义了预设调用方法 (deletebyprimarykey方法或updatebyprimarykey方法),则需要在分布式缓存中对rediskey变量对应的数据进行操作。
80.步骤23,确定rediskey变量名对应的变量值,并根据所述前缀和所述变量值得到rediskey变量。
81.在本步骤中,可以在数据库的入参中确定rediskey变量名对应的变量值。
82.步骤24,在分布式缓存中对rediskey变量对应的数据执行与数据操作指令相对应的操作。
83.在一些实施例中,如图2所示,在响应于在本地缓存中未查询到全限定名对应的rediskey变量名和rediskey变量的前缀,获取全限定名对应的rediskey 变量名和rediskey变量的前缀(步骤21)之后,所述方法还包括以下步骤:
84.步骤22’,响应于确定出不需要在分布式缓存中对rediskey变量对应的数据进行操作,将全限定名添加到忽略列表中。需要说明的是,在本步骤中,还需要在数据库中执行与数据操作指令对应的操作,并返回操作结果。
85.以下分别结合图3和图4,对基于数据查询指令在分布式缓存中对数据进行操作的流程,和基于数据修改指令在分布式缓存中对数据进行操作的流程,进行详细说明。
86.当数据操作指令为数据查询指令时,如图3所示,所述在分布式缓存中对rediskey变量对应的数据执行与数据操作指令相对应的操作(即步骤14),包括以下步骤:
87.步骤31,在分布式缓存中查询rediskey变量对应的数据。
88.步骤32,若在分布式缓存中未查询到rediskey变量对应的数据,则执行步骤33;若在分布式缓存中查询到rediskey变量对应的数据,则执行步骤34。
89.步骤33,从数据库中查询相应的数据,并在分布式缓存中存储所述数据。
90.在本步骤中,在分布式缓存中没有查询到rediskey变量对应的数据的情况下,直接调用执行器从数据库中获取查询结果,将查询结果缓存到分布式缓存中,并返回查询结果(即查询到的数据)。在数据库中查询到相应数据之后,在分布式缓存中根据rediskey变量存储该数据,以便后续查询时可以直接从分布式缓存中调用该数据,无需再去数据库中查询,提高数据处理效率。
91.步骤34,返回查询到的数据。
92.在本步骤中,在分布式缓存中查询到rediskey变量对应的数据的情况下,直接返回查询结果(即查询到的数据),节省了去数据库中再次查询的步骤,提高数据处理效率。
93.当数据操作指令为数据修改指令时,如图4所示,所述在分布式缓存中对 rediskey变量对应的数据执行与数据操作指令相对应的操作(即步骤14),包括以下步骤:
94.步骤41,在分布式缓存中查询rediskey变量对应的数据。
95.步骤42,若在分布式缓存中查询到rediskey变量对应的数据,则执行步骤 43;若在分布式缓存中未查询到rediskey变量对应的数据,则执行步骤44。
96.步骤43,在分布式缓存中对数据执行删除操作,并在数据库中执行数据修改指令
对应的操作。
97.数据修改指令包括数据更新指令和数据删除指令,无论是数据更新指令还是数据删除指令,在本步骤中,在分布式缓存中查询到rediskey变量对应的数据的情况下,针对分布式缓存中存储的数据,均进行数据删除操作,而在数据库中则区别对待,即若为数据更新指令,则在数据库中对相应数据进行数据更新,若为数据删除指令,则在数据库中对相应数据进行删除。
98.步骤44,在数据库中对所述数据执行数据修改指令对应的操作。
99.在本步骤中,在分布式缓存中未查询到rediskey变量对应的数据的情况下,直接去数据库中执行数据修改指令,即若为数据更新指令,则在数据库中对相应数据进行数据更新,若为数据删除指令,则在数据库中对相应数据进行删除。
100.如果在删除分布式缓存中数据到删除数据库中数据之间,有并发的针对该数据的查询操作,这样就会在分布式缓存中重新产生新的缓存,即已经删除的数据又重新缓存在分布式缓存中,但是此时数据库中该数据已被删除,这样就会造成数据返回错误。为了避免上述问题,在一些实施例中,针对数据修改指令,如图5所示,响应于在分布式缓存中查询到所述rediskey变量对应的数据,在数据库中对数据执行数据修改指令对应的操作(即步骤43)之后,或者,响应于在分布式缓存中未查询到rediskey变量对应的数据,在数据库中对数据执行数据修改指令对应的操作(即步骤44)之后,所述数据缓存方法还可以包括以下步骤:
101.步骤45,在分布式缓存中查询rediskey变量对应的数据。
102.步骤46,若在分布式缓存中查询到rediskey变量对应的数据,则执行步骤47,否则,结束本流程。
103.步骤47,在分布式缓存中删除所述数据。
104.在数据库中对数据执行数据修改指令对应的操作之后,再次在分布式缓存中查询相应数据,如果已经删除的数据仍存在,则再次在分布式缓存中删除该数据,以实现双删机制,确保缓存在分布式缓存中数据的正确性。由于分布式缓存中可能删除数据失败,但是数据库中删除数据后无法回退,所以在本发明实施例中采用双删机制,先对分布式缓存中的数据进行一次删除操作,保证老数据已经删除。再在完成数据库中数据删除之后对分布式缓存中的数据进行第二次删除操作,确保分布式缓存与数据库对于同一数据的一致性。
105.以下分别针对数据查询指令和数据修改指令,在本地缓存中未查询到全限定名对应的rediskey变量名和前缀的情况下,获取全限定名对应的rediskey 变量名和rediskey变量的前缀的过程进行详细说明。
106.当数据操作指令为数据查询指令时,所述获取全限定名对应的rediskey变量名和rediskey变量的前缀(即步骤21),包括:根据第一注解获取rediskey 变量名和rediskey变量的前缀,具有第一注解的调用方法能够在分布式缓存中存储返回的数据;其中,若rediskey变量名为空,则将预设字符(例如数据库 id)作为rediskey变量名;若rediskey变量的前缀为空,则确定全限定名对应的调用方法,并确定调用方法的返回值对象的类名,将所述类名作为rediskey 变量的前缀。需要说明的是,若rediskey变量名不为空,则rediskey变量名即为获取到的与全限定名对应的rediskey变量名。若rediskey变量的前缀不为空, rediskey变量的前缀即为获取到的与全限定名对应的rediskey的前缀。
107.当数据操作指令为数据修改指令时,所述获取全限定名对应的rediskey变量名和rediskey变量的前缀(即步骤21),包括:根据第二注解获取rediskey 变量名、rediskey变量的前缀和调用方法属性(即redisaddmethod属性),具有第二注解的调用方法能够在分布式缓存中删除返回的数据;其中,若rediskey 变量名为空,则将预设字符作为rediskey变量的变量名;若rediskey变量的前缀为空,则根据调用方法属性、第一注解或预设调用方法(即selectbyprimarykey 方法)确定rediskey变量的前缀。需要说明的是,若rediskey变量名不为空,则rediskey变量名即为获取到的与全限定名对应的rediskey变量名。若 rediskey变量的前缀不为空,rediskey变量的前缀即为获取到的与全限定名对应的rediskey变量的前缀。
108.也就是说,数据修改指令相对于数据查询指令而言,获取rediskey变量的前缀,还需要调用方法属性(redisaddmethod属性),利用redisaddmethod属性,可以自定义添加分布式缓存的函数(即调用方法)。
109.在一些实施例中,如图6所示,针对数据修改指令,所述根据调用方法属性、第一注解或预设调用方法确定rediskey变量的前缀,包括以下步骤:
110.步骤51,若调用方法属性不为空,则执行步骤52;若调用方法属性为空,则执行步骤53。
111.若redisaddmethod属性的值不为空,则将redisaddmethod属性对应的调用方法的返回值对象的类名作为rediskey变量的前缀。若redisaddmethod属性的值为空,则获取@redisadd注解对应的调用方法。
112.步骤52,确定调用方法属性对应的调用方法的返回值对象的类名,将所述类名作为rediskey变量的前缀。
113.步骤53,获取第一注解对应的调用方法。
114.在本步骤中,通过java反射机制获取具有@redisadd注解的调用方法。
115.步骤54,若获取到第一注解对应的调用方法,则执行步骤55;若未获取到第一注解对应的调用方法,则执行步骤56。
116.若获取到@redisadd注解对应的调用方法,且该调用方法为多个时,则将首个调用方法的返回值对象的类名作为rediskey变量的前缀。若没有获取到 @redisadd注解对应的调用方法,则将selectbyprimarykey方法的返回值对象的类名作为rediskey变量的前缀,以便将rediskey变量的前缀设置为默认值。
117.步骤55,确定调用方法中首个调用方法的返回值对象的类名,将所述类名作为rediskey变量的前缀。
118.在本步骤中,可以将第一个@redisadd注解设置的rediskeyprefix变量的值作为rediskey变量的前缀。在rediskeyprefix变量的值为空的情况下,通过java 反射机制获取该调用方法的返回值的类名,将其作为rediskey变量的前缀。
119.步骤56,确定预设调用方法的返回值对象的类名,将所述类名作为rediskey 变量的前缀。
120.需要说明的是,如果没有定义selectbyprimarykey方法,表示没有自动添加分布式缓存的调用方法,则直接在数据库中执行数据修改指令对应的操作。
121.本发明实施例利用自定义注解(@redisadd注解和@redisdelete注解),可以指定
新增缓存、删除缓存对应的方法,或者需要进行分布式缓存的方法,具有较强的灵活性。
122.本发明实施例提供的数据缓存方法,基于mybatis、springboot、redis技术。通过mybatis的拦截器扩展功能,实现了自动缓存的mybatis插件,在查询数据库时自动将查询到的数据添加到分布式缓存,在更改数据库时,自动删除分布式缓存内相应的数据。
123.传统的mybatis二级缓存技术,在修改数据库中某一个数据时,会将分布式缓存中所有数据均删除,这样会影响后续数据的读取效率,实用性差。而本发明实施例可以针对一条数据对分布式缓存进行操作,具有较高的实用性。
124.基于相同的技术构思,本发明实施例还提供一种数据缓存装置,如图7所示,所述数据缓存装置包括接收模块101、获取模块102、第一处理模块103和第二处理模块104,接收模块101用于,接收针对数据库的数据操作指令,获取所述数据操作指令所调用方法的全限定名。
125.获取模块102用于,根据所述全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀。
126.第一处理模块103用于,响应于在本地缓存中查询到所述全限定名对应的 rediskey变量名和rediskey变量的前缀,确定所述rediskey变量名对应的变量值,并根据所述前缀和所述变量值得到rediskey变量。
127.第二处理模块104用于,在分布式缓存中对所述rediskey变量对应的数据执行与所述数据操作指令相对应的操作。
128.在一些实施例中,如图8所示,所述数据缓存装置还包括判断模块105,判断模块105用于,在第一处理模块103在获取所述数据操作指令所调用方法的全限定名之后,根据所述全限定名在本地缓存中查询rediskey变量名和 rediskey变量的前缀之前,判断所述全限定名是否在忽略列表中。
129.第一处理模块103用于,响应于所述全限定名不在所述忽略列表中,根据所述全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀。
130.在一些实施例中,第一处理模块103还用于,响应于所述全限定名在所述忽略列表中,在所述数据库中执行所述数据操作指令对应的操作。
131.在一些实施例中,第一处理模块103还用于,在根据所述全限定名在本地缓存中查询rediskey变量名和rediskey变量的前缀之后,响应于在本地缓存中未查询到所述全限定名对应的rediskey变量名和rediskey变量的前缀,获取所述全限定名对应的rediskey变量名和rediskey变量的前缀;响应于确定出需要在所述分布式缓存中对所述rediskey变量对应的数据进行操作,将所述 rediskey变量名和所述rediskey变量的前缀存储在本地缓存中;确定所述 rediskey变量名对应的变量值,并根据所述前缀和所述变量值得到rediskey变量。
132.在一些实施例中,第一处理模块103还用于,响应于在本地缓存中未查询到所述全限定名对应的rediskey变量名和rediskey变量的前缀,获取所述全限定名对应的rediskey变量名和rediskey变量的前缀之后,响应于确定出不需要在所述分布式缓存中对所述rediskey变量对应的数据进行操作,将所述全限定名添加到所述忽略列表中。
133.在一些实施例中,所述数据操作指令为数据查询指令,第二处理模块104 用于,在分布式缓存中查询所述rediskey变量对应的数据,响应于在所述分布式缓存中未查询到所
述rediskey变量对应的数据,从所述数据库中查询相应的数据,并在所述分布式缓存中存储所述数据。
134.在一些实施例中,所述数据操作指令为数据查询指令,第一处理模块103 用于,根据第一注解获取rediskey变量名和rediskey变量的前缀,具有所述第一注解的调用方法能够在所述分布式缓存中存储返回的数据;其中,若所述 rediskey变量名为空,则将预设字符作为rediskey变量名;若所述rediskey 变量的前缀为空,则确定所述全限定名对应的调用方法,并确定所述调用方法的返回值对象的类名,将所述类名作为所述rediskey变量的前缀。
135.在一些实施例中,所述数据操作指令为数据修改指令,第二处理模块104 用于,在分布式缓存中查询所述rediskey变量对应的数据;响应于在所述分布式缓存中查询到所述rediskey变量对应的数据,在所述分布式缓存中对所述数据执行删除操作,并在所述数据库中执行所述数据修改指令对应的操作;响应于在所述分布式缓存中未查询到所述rediskey变量对应的数据,在所述数据库中对所述数据执行所述数据修改指令对应的操作。
136.在一些实施例中,第二处理模块104还用于,响应于在所述分布式缓存中查询到所述rediskey变量对应的数据,在所述数据库中对所述数据执行所述数据修改指令对应的操作之后,或者,响应于在所述分布式缓存中未查询到所述 rediskey变量对应的数据,在所述数据库中对所述数据执行所述数据修改指令对应的操作之后,在所述分布式缓存中查询所述rediskey变量对应的数据;响应于在所述分布式缓存中查询到所述rediskey变量对应的数据,在所述分布式缓存中删除所述数据。
137.在一些实施例中,所述数据操作指令为数据修改指令,第一处理模块103 用于,根据第二注解获取rediskey变量名、rediskey变量的前缀和调用方法属性,具有所述第二注解的调用方法能够在所述分布式缓存中删除返回的数据;其中,若所述rediskey变量名为空,则将预设字符作为所述rediskey变量的变量名;若所述rediskey变量的前缀为空,则根据所述调用方法属性、第一注解或预设调用方法确定所述rediskey变量的前缀。
138.在一些实施例中,第一处理模块103用于,响应于所述调用方法属性不为空,确定所述调用方法属性对应的调用方法的返回值对象的类名,将所述类名作为所述rediskey变量的前缀;响应于所述调用方法属性为空,获取第一注解对应的调用方法,确定所述调用方法中首个调用方法的返回值对象的类名,将所述类名作为所述rediskey变量的前缀;响应于所述调用方法属性为空且未获取到第一注解对应的调用方法,确定预设调用方法的返回值对象的类名,将所述类名作为所述rediskey变量的前缀。
139.本发明实施例还提供了一种计算机设备,该计算机设备包括:一个或多个处理器以及存储装置;其中,存储装置上存储有一个或多个程序,当上述一个或多个程序被上述一个或多个处理器执行时,使得上述一个或多个处理器实现如前述各实施例所提供的数据缓存方法。
140.本公开实施例还提供了一种计算机可读介质,其上存储有计算机程序,其中,该计算机程序被执行时实现如前述各实施例所提供的数据缓存方法。
141.可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精
神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
