一种基于微生物宏基因组学的河流含氮污染物溯源的机器学习方法
- 国知局
- 2024-07-12 10:35:43
本发明涉及环境,尤其涉及一种基于微生物宏基因组学的河流含氮污染物溯源的机器学习方法。
背景技术:
1、氮污染是水体恶化的主要原因之一,与环境灾难密切相关。河流中氮污染源的准确定位至关重要,若只使用水文模型进行河流氮污染物溯源,面临着复杂性高、对大量准确数据的依赖、验证难度大、不确定性存在以及适用性局限等挑战。同位素溯源技术也同样存在局限性,其同位素特征可能会受到河内过程的影响产生分馏,且只能分析硝酸盐而不是总氮(总氮在污染区划分中起非常重要的作用)。
2、传统方法如水文模型存在高质量数据缺乏的情况,这限制了水文模型的可靠性;同位素技术也存在局限性,其同位素特征可能会受到河内过程的影响产生分馏,且只能分析硝酸盐而不是总氮。因此,如何在缺乏氮污染源调查数据的情况下,溯源河流含氮污染物以保护河流水体,已成为遏制水体富营养化、保护河流生态系统的重要课题之一。
3、现有的研究中,开发了多种机器学习(ml)算法,如分类和回归树、人工神经网络、随机森林等,通过阐明非线性、多元和非单调关系,为解析微生物数据提供了新途径。机器学习不仅可以识别水样的来源,还能确定样本的深度和区域盐度,具有广泛的应用前景。
技术实现思路
1、本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种基于微生物宏基因组学的河流含氮污染物溯源的机器学习方法,通过整合微生物宏基因组数据与机器学习方法克服了传统河流氮污染物溯源方法的技术限制,实现了全面、自动化的信息获取和多源信息综合。
2、为解决上述技术问题,本发明提出的技术方案为:
3、一种基于微生物宏基因组学的河流含氮污染物溯源的机器学习方法,包括以下步骤:
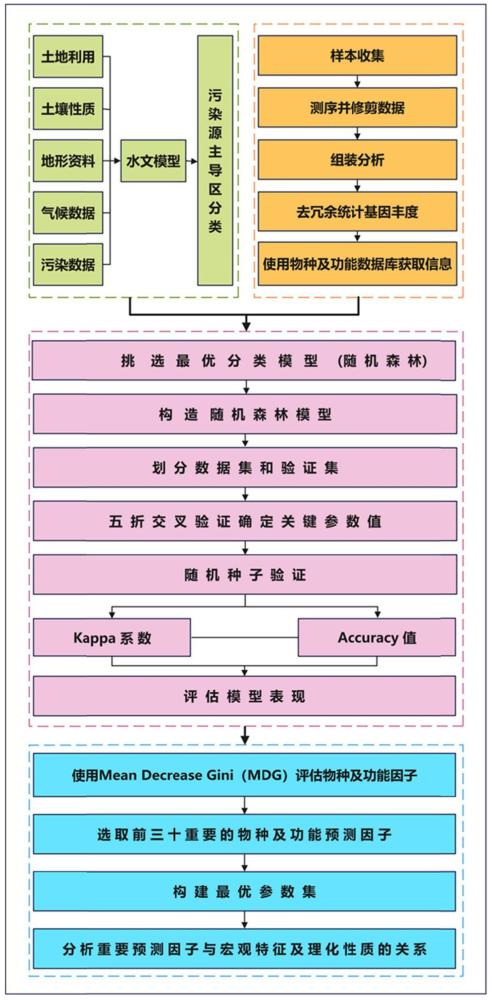
4、s1)通过水文模型分析指定流域的氮污染类别,将流域划分为点源主导区(pa)、作物种植污染主导区(ca)和化粪池污染主导区(sa);
5、s2)根据分析得到的氮污染类别状况,分别从不同污染区域指定采样点进行现场取样,采集沉积物样本;
6、s3)对采集的样本进行微生物的宏基因组测序,并将测序数据匹配预设的物种及分类数据库,得到微生物组成及功能数据等特征信息;
7、s4)将微生物组成及功能数据作为解释变量,将对应的氮污染类别作为响应变量,构建数据集并训练氮污染物溯源模型以预测主要氮污染物来源;
8、s5)使用mean decrease gini(mdg)作为特征重要性指标评估物种及功能因子,从解释变量中筛选最优参数,形成最优参数集并分析最优参数与河流的宏观特征及理化性质的数据等环境变量的相关性。
9、进一步的,步骤s1中,通过水文模型分析指定流域的氮污染类别时,包括:
10、构建指定流域的水文模型,引入污染源数据库到水文模型中,运行水文模型模拟氮污染源来识别污染区域。
11、进一步的,引入污染源数据库到水文模型中之后,还包括对模型进行参数化和校准的步骤,包括:
12、比对当前模型的模拟结果和实测数据,调整模型参数以提高拟合度;
13、使用指定的优化算法对调整后的模型参数进行优化。
14、进一步的,步骤s2中,分别从不同污染区域指定采样点进行现场取样时,包括:
15、根据支流和主河道的氮污染状况,在每个污染区域设置指定数量的采样点,每个采样点在指定采样时间采集沉积物样本并进行均质化处理。
16、进一步的,步骤s3中,对采集的样本进行微生物宏基因组测序时,包括:
17、提取样本的dna,通过鸟枪法生成原始宏基因组测序数据,对原始宏基因组测序数据进行数据修剪,得到高质量序列;
18、对所述高质量序列进行组装和分析,得到代表宏基因组连读序列的contigs与对应的开放阅读框orfs。
19、进一步的,步骤s3中,将测序数据匹配预设的数据库时,包括:
20、判断所有基因序列之间的相似性,将相似度超过预设阈值的基因序列合并,得到去冗余后的基因序列;
21、将去冗余后的基因序列与预设的物种及分类数据库进行比对,得到对应的具体的物种及功能指标作为序列注释。
22、进一步的,步骤s4中,将微生物组成及功能数据作为解释变量之前还包括预处理的步骤,包括:删除宏基因组测序的原始数据中reads数量小于第一指定值和/或在所有微生物中占比小于第二指定值的微生物及功能数据。
23、进一步的,步骤s4中,训练氮污染物溯源模型时,包括:
24、将所述数据集划分为训练集和测试集;
25、构建随机森林模型,使用训练集通过5倍交叉验证确定随机森林模型的关键参数最佳值;
26、使用测试集通过不同的随机种子重复测试训练好的随机森林模型。
27、进一步的,步骤s5中,从解释变量中筛选最优参数时,包括:
28、使用不同的随机种子构建随机森林模型;
29、将数据集输入每个随机森林模型中,计算每个随机森林模型的解释变量的mdg结果;
30、对所述mdg结果进行统计分析,按照排名从高到低的顺序筛选最优参数,得到最优参数集。
31、进一步的,步骤s5中,从解释变量中筛选最优参数之后,还包括:使用最优参数集对训练好的氮污染物溯源模型进行交叉验证以评估模型性能。
32、进一步的,步骤s5中,分析最优参数与河流的宏观特征及理化性质的数据等环境变量的相关性时,包括:将最优参数集中的最优参数作为重要预测因子并与河流的宏观特征及理化性质的数据整合;解释重要预测因子与河流宏观特征及理化性质之间的关系,确定哪些因子对于特定特征和性质的影响更为显著。
33、与现有技术相比,本发明的优点在于:
34、本发明结合微生物信息这一灵敏的反应器,能够更准确地反映河流现状,且宏基因组测序能提供更高的物种分类分辨率,避免引物偏倚引起的假阳性/假阴性,同时提供微生物物种及功能信息,从而最终使得模型能够提供更为精确、全面的溯源信息,为解决河流氮污染问题带来新的数据驱动解决方案。此外,相比较于直接在污染源出口处采集样本训练模型,本发明所使用的成熟水文模型通常会考虑环境变量(如流速、流量、地形等)对污染物迁移扩散的影响以分析不同来源含氮污染物在河流中的实际含量,从而直接评估自然河道中的主要污染物来源,这提供了一种更为系统和全面的溯源策略。通过水文模型的辅助,可以更好地理解河流污染的动态变化和传输路径,从而在使用宏基因组数据进行预测时,能够提供更多的背景信息,直接将物种与功能信息关联到具体的环境条件和污染物特性,增强预测的准确性,有助于更好地理解宏基因组数据与实际河流环境的关系,为在河流中直接采样而进行污染物溯源提供基础。因此,本发明预先通过构建成熟水文模型溯源含氮污染源,并通过机器学习的方法掌握了河流微生物宏基因组数据与各类主要含氮污染源之间的具体映射关系。通过本专利构建的新方法,能在缺乏高精度污染数据的前提下通过原位采样获取流域主要含氮污染源信息,为环境管理者提供技术和数据支持,有助于制定更具针对性的水质管理政策,采取更有针对性的生态保护和恢复措施,这一创新方法为实现可持续环境发展和水资源保护提供了科学支持。
本文地址:https://www.jishuxx.com/zhuanli/20240614/87917.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表