音频处理方法、计算机设备及计算机存储介质与流程
- 国知局
- 2024-06-21 10:39:33
本申请实施例涉及音频处理领域,具体涉及一种音频处理方法、计算机设备及计算机存储介质。
背景技术:
1、多人合唱的场景下,合唱的每个用户的终端上传成员的歌声数据至服务端,服务端将多个用户的歌声数据合成为合唱歌声数据。
2、但是,由于每个用户的网络和设备不同,且用户之间的唱歌水平存在差异,全部合流会导致合唱歌声数据的听感存在较大的不确定性,例如有人在噪音很大的环境下加入合唱,必然会对合唱的整体效果带来很大的干扰,导致合唱歌声的听感不佳。
技术实现思路
1、本申请实施例提供了一种音频处理方法、计算机设备及计算机存储介质,用于从多路干声音频中筛选出优质的干声音频以提升合唱音频的听感。
2、本申请实施例第一方面提供了一种音频处理方法,所述方法应用于服务端,所述服务端与演唱端连接;所述方法包括:
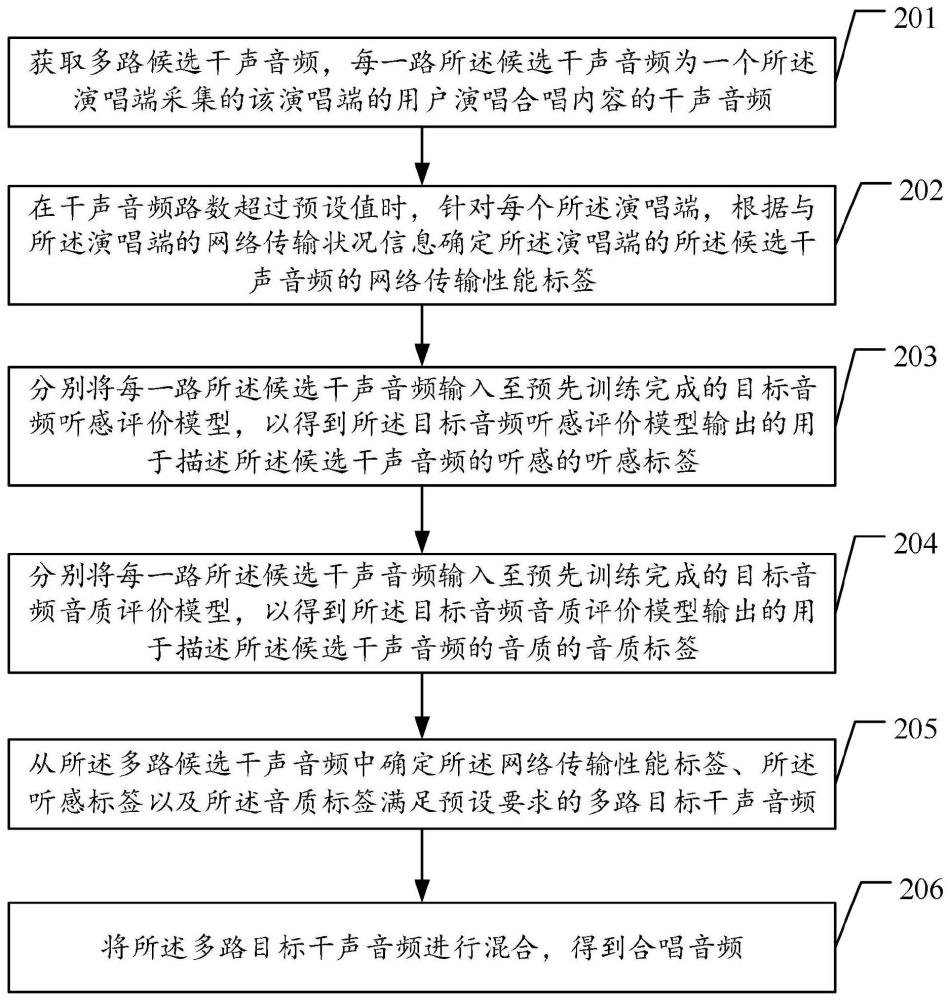
3、获取多路候选干声音频,每一路所述候选干声音频为一个所述演唱端采集的该演唱端的用户演唱合唱内容的干声音频,多个所述演唱端的用户演唱的合唱内容相同;
4、在干声音频路数超过预设值时,针对每个所述演唱端,根据与所述演唱端的网络传输状况信息确定所述演唱端的所述候选干声音频的网络传输性能标签;
5、分别将每一路所述候选干声音频输入至预先训练完成的目标音频听感评价模型,以得到所述目标音频听感评价模型输出的用于描述所述候选干声音频的听感的听感标签;
6、分别将每一路所述候选干声音频输入至预先训练完成的目标音频音质评价模型,以得到所述目标音频音质评价模型输出的用于描述所述候选干声音频的音质的音质标签;
7、从所述多路候选干声音频中确定所述网络传输性能标签、所述听感标签以及所述音质标签满足预设要求的多路目标干声音频;
8、将所述多路目标干声音频进行混合,得到合唱音频。
9、本申请实施例第二方面提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现前述第一方面的方法。
10、本申请实施例第三方面提供了一种计算机存储介质,计算机存储介质中存储有指令,该指令在计算机上执行时,使得计算机执行前述第一方面的方法。
11、本申请实施例第四方面提供了一种计算机程序产品,所述计算机程序产品包括计算机程序,该计算机程序被处理器执行时实现前述第一方面的方法。
12、从以上技术方案可以看出,本申请实施例具有以下优点:
13、根据与演唱端的网络传输状况信息确定演唱端的候选干声音频的网络传输性能标签,使用目标音频听感评价模型获得候选干声音频的听感标签,使用目标音频音质评价模型获得候选干声音频的音质标签,从多路候选干声音频中确定网络传输性能标签、听感标签以及音质标签满足预设要求的多路目标干声音频,并将多路目标干声音频进行混合,得到合唱音频。基于各项评价指标对多路干声音频的质量进行衡量,从而筛选出优质的干声音频,进而由多路优质的干声音频合成的合唱音频的听感效果更佳,提升用户合唱的兴趣和体验。
技术特征:1.一种音频处理方法,其特征在于,所述方法应用于服务端,所述服务端与演唱端连接;所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述从所述多路候选干声音频中确定所述网络传输性能标签、所述听感标签以及所述音质标签满足预设要求的多路目标干声音频,包括:
3.根据权利要求2所述的方法,其特征在于,所述网络传输性能标签、所述听感标签以及所述音质标签包括优先级最高的标签、优先级次高的标签以及优先级最低的标签;
4.根据权利要求1所述的方法,其特征在于,所述方法还包括:
5.根据权利要求1所述的方法,其特征在于,所述网络传输性能标签包括所述演唱端向所述服务端传输音频数据包的丢包率、所述候选干声音频的延迟时间;和/或
6.根据权利要求1所述的方法,其特征在于,所述目标音频听感评价模型的训练步骤包括:
7.根据权利要求1所述的方法,其特征在于,所述目标音频音质评价模型的训练步骤包括:
8.根据权利要求1至7任一项所述的方法,其特征在于,所述服务端还与观众端连接;所述方法还包括:
9.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至8中任一项所述的方法。
10.一种计算机存储介质,其特征在于,所述计算机存储介质中存储有指令,所述指令在计算机上执行时,使得所述计算机执行如权利要求1至8中任一项所述的方法。
技术总结本申请实施例公开了一种音频处理方法、计算机设备及计算机存储介质。本申请实施例包括:服务端根据与演唱端的网络传输状况信息确定演唱端的候选干声音频的网络传输性能标签,使用目标音频听感评价模型获得候选干声音频的听感标签,使用目标音频音质评价模型获得候选干声音频的音质标签,从多路候选干声音频中确定网络传输性能标签、听感标签以及音质标签满足预设要求的多路目标干声音频,并将多路目标干声音频进行混合,得到合唱音频。基于各项评价指标对多路干声音频的质量进行衡量,从而筛选出优质的干声音频,进而由多路优质的干声音频合成的合唱音频的听感效果更佳,提升用户合唱的兴趣和体验。技术研发人员:王磊,黄斯亮,王玉奎,龙少杭,冯伟赞,刘伶俐,施翠婷,梁兴威,欧阳金凯,刘腾飞,张田博,李贤茂,宗旋受保护的技术使用者:腾讯音乐娱乐科技(深圳)有限公司技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/21004.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表