基于时间自注意力卷积神经网络的语音增强方法及设备
- 国知局
- 2024-06-21 10:39:33
本发明涉及语音增强技术,尤其涉及一种基于时间自注意力卷积神经网络的语音增强方法及设备。
背景技术:
1、用于提高感知质量的实时语音增强(speech enhancement:se)是一个具有数十年历史的经典问题,近年来基于学习的方法获得了远超传统方法的突出结果。根据其训练目标的不同,语音增强分为三类算法:基于掩膜(masking-based)的时频域算法、基于映射(mapping-based)的时频域算法、基于时域波形的端到端算法。
2、神经网络是一种近年来十分活跃且效果优异的统计学习方法。大量的神经网络结构,如卷积神经网络(convolutional neural network:cnn)、循环神经网络(recurrentneural network:rnn)、注意力(attention)网络等已经应用于语音增强领域。传统的cnn、rnn模型的感受野不足,限制了模型对时序信号的建模能力。注意力网络的建模能力很强,但参数量大、计算量大,限制了其使用范围。因此,语音增强这一研究领域依然需要开展大量、深入的研究工作,从而满足日益增长的高质量语音应用需求。
3、公开号为cn115497496a的专利文献公开了一种基于fireps卷积神经网络的语音增强方法,该方法提取对数功率谱图,作为fireps卷积神经网络的输入特征进行语音增强,不过该专利方法对语音信号的时序信息利用较不充分,且因为使用fire块、提取特征时使用空洞卷积网络块以及上采样的像素重排块,导致结构较为复杂,模型复杂度较高。
技术实现思路
1、发明目的:本发明针对现有技术存在的问题,提供一种基于时间自注意力卷积神经网络的语音增强方法及设备。
2、技术方案:本发明所述的基于时间自注意力卷积神经网络的语音增强方法包括:
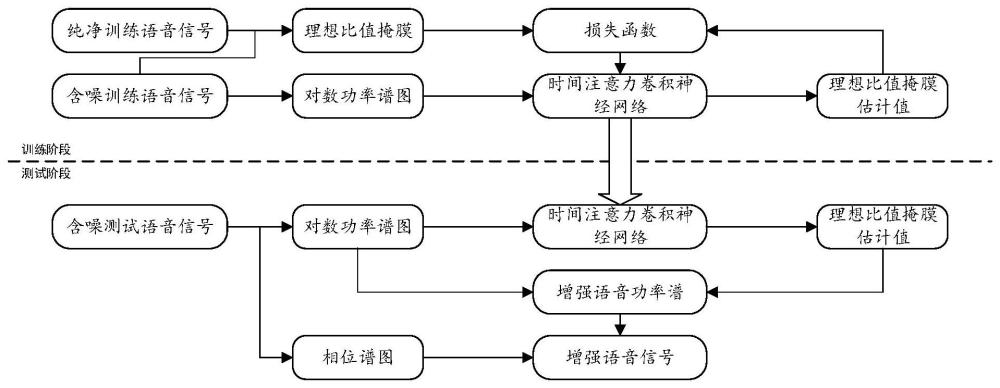
3、步骤1、将单通道的纯净训练语音信号与各种加性噪声按不同信噪比混合,得到若干含噪训练语音信号;
4、步骤2、对每个含噪训练语音信号进行预处理,得到对应对数功率谱图,并计算每个含噪训练语音信号的理想比值掩膜irm;
5、步骤3、构建时间注意力卷积神经网络,所述时间注意力卷积神经网络包括依次连接的卷积模块、编码器模块、时间自注意力块、解码器模块和反卷积模块,所述编码器模块还与所述解码器模块残差连接,所述编码器模块用于下采样,所述解码器模块用于上采样;
6、步骤4、将含噪训练语音信号的对数功率谱图和理想比值掩膜irm,分别作为时间注意力卷积神经网络的输入特征和标签,完成训练;
7、步骤5、将待增强的含噪测试语音信号通过预处理得到对数功率谱图和相位谱图;
8、步骤6、将含噪测试语音信号的对数功率谱图输入时间注意力卷积神经网络,得到理想比值掩膜估计值,并根据理想比值掩膜估计值和相位谱图计算得到时域增强语音信号。
9、进一步的,所述步骤2具体包括:
10、步骤2.1、将纯净训练语音信号和每个含噪训练语音信号分别依次进行分帧、加窗和短时傅里叶变换,得到对应语音信号的若干帧频谱;
11、步骤2.2、将每个含噪训练语音信号的所有帧的频谱分别进行对数运算,得到每帧的对数功率谱,并将所有帧的对数功率谱按照帧顺序、频点顺序进行排列,组成对数功率谱矩阵,即为对数功率谱图;
12、步骤2.3、根据每个含噪训练语音信号的所有帧的频谱和对应纯净训练语音信号的所有帧的频谱,计算得到每个含噪训练语音信号的理想比值掩膜irm。
13、进一步的,所述卷积模块包括依次连接的卷积层、批归一化层和prelu激活函数。
14、进一步的,所述反卷积模块包括依次连接的反卷积层和sigmoid激活函数。
15、进一步的,所述编码器模块包括若干编码器,每个编码器包括依次连接的卷积层、批归一化层、dropout层和prelu激活函数。
16、进一步的,所述解码器模块包括与编码器同等数量的解码器,每个编码器与对应解码器残差连接,每个解码器包括依次连接的反卷积层、批归一化层、dropout层和prelu激活函数。
17、进一步的,所述时间自注意力块包括若干依次连接的时间注意力层,所述时间注意力层用于先对输入进行一维卷积、维度重整和softmax函数计算出一组权重系数,同时将输入通过一维卷积和维度重整求出特征信息,再将特征信息与权重系数加权求和得到加权相量,最后将加权相量经过维度重整得到与输入维度相同的加权向量。
18、进一步的,所述时间注意力卷积神经网络训练时采用的损失函数为:
19、loss=10*lossirm(log-mae)+k1*losssi-sdr+k2*losspmsqe
20、其中,loss表示总损失,参数k1和k2是权重系数,lossirm(log-mae)是理想比值掩膜和理想比值掩膜估计值两者的对数值之间的最小绝对误差损失函数,losssi-sdr是增强语音信号相对于纯净语音信号的尺度不变失真比si-sdr损失函数,losspmsqe是语音质量算法知觉度量pmsqe损失函数。
21、进一步的,所述根据理想比值掩膜估计值和相位谱图计算得到时域增强语音信号,具体包括:将理想比值掩膜估计值与对应对数功率谱图相乘得到增强语音功率谱,再将增强语音功率谱与对应相位谱图相乘,得到增强语音信号的频谱,最后将增强语音信号的频谱经短时傅里叶逆变换和重叠相加法得到时域增强语音信号。
22、本发明所述的基于时间注意力卷积神经网络的语音增强设备,包括处理器及存储在存储器上并可在处理器上运行的可执行程序,所述处理器执行所述可执行程序时实现上述方法。
23、本发明与现有技术相比,其有益效果是:本发明增大了传统卷积神经网络的感受野,减少神经网络的参数量,解决了现有技术中对语音信号这一时序信号的建模能力不足的问题,同时减少计算量、缩短模型所须的计算时间。本发明通过引入时间自注意力机制,对语音信号的时序信息特征更好地进行捕捉,充分利用了语音信号的时序信息,同时本发明使用结构更加简单的卷积块,降低了模型复杂度。
技术特征:1.一种基于时间自注意力卷积神经网络的语音增强方法,其特征在于,包括:
2.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述步骤2具体包括:
3.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述卷积模块包括依次连接的卷积层、批归一化层和prelu激活函数。
4.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述反卷积模块包括依次连接的反卷积层和sigmoid激活函数。
5.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述编码器模块包括若干编码器,每个编码器包括依次连接的卷积层、批归一化层、dropout层和prelu激活函数。
6.根据权利要求5所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述解码器模块包括与编码器同等数量的解码器,每个编码器与对应解码器残差连接,每个解码器包括依次连接的反卷积层、批归一化层、dropout层和prelu激活函数。
7.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述时间自注意力块包括若干依次连接的时间注意力层,所述时间注意力层用于先对输入进行一维卷积、维度重整和softmax函数计算出一组权重系数,同时将输入通过一维卷积和维度重整求出特征信息,再将特征信息与权重系数加权求和得到加权相量,最后将加权相量经过维度重整得到与输入维度相同的加权向量。
8.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述时间注意力卷积神经网络训练时采用的损失函数为:
9.根据权利要求1所述的基于时间注意力卷积神经网络的语音增强方法,其特征在于:所述根据理想比值掩膜估计值和相位谱图计算得到时域增强语音信号,具体包括:
10.一种基于时间注意力卷积神经网络的语音增强设备,包括处理器及存储在存储器上并可在处理器上运行的可执行程序,其特征在于:所述处理器执行所述可执行程序时实现如权利要求1-9中任一项所述的方法。
技术总结本发明公开了一种基于时间自注意力卷积神经网络的语音增强方法及设备,方法包括:对含噪训练语音信号进行预处理,得到对数功率谱图和IRM;构建时间注意力卷积神经网络,包括依次连接的卷积模块、编码器模块、时间自注意力块、解码器模块和反卷积模块;将对数功率谱图和IRM,分别作为网络的输入特征和标签完成训练;将待增强的含噪测试语音信号通过预处理得到对数功率谱图和相位谱图;将含噪测试语音信号的对数功率谱图输入网络,得到对应理想比值掩膜估计值,根据理想比值掩膜估计值和相位谱图计算得到时域增强语音信号。本发明计算量小,效果更好。技术研发人员:闫桐嘉,周琳,李奥,李明諹,徐良,陈惜金受保护的技术使用者:东南大学技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/21003.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。