自适应蒸馏的制作方法
- 国知局
- 2024-06-21 10:39:29
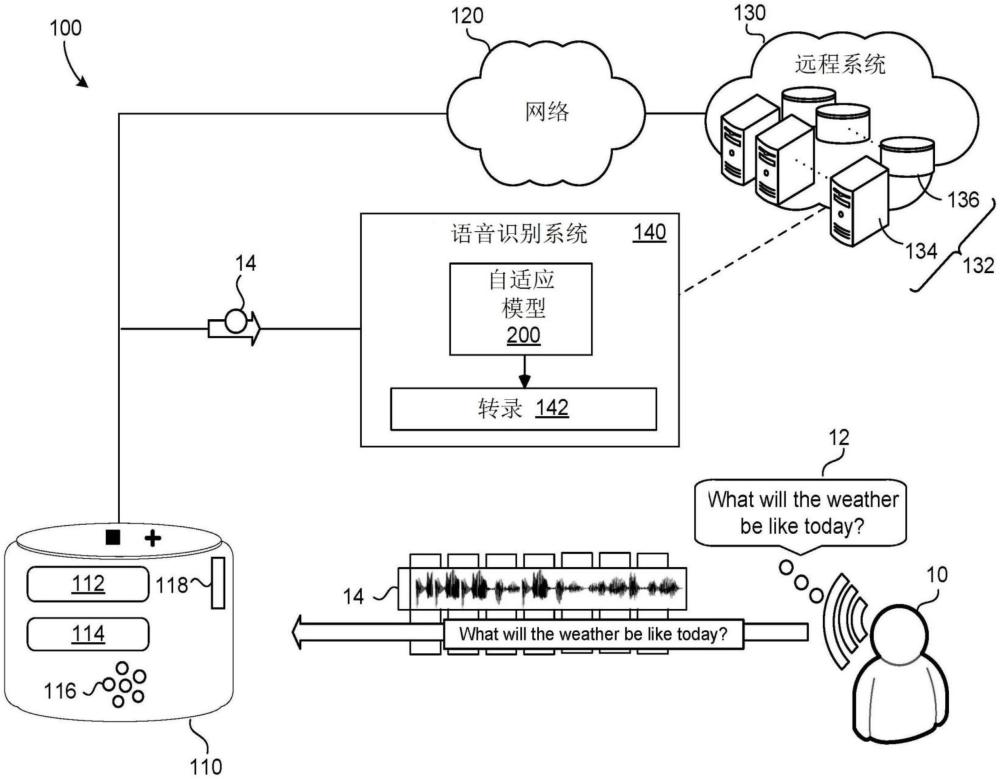
本公开涉及自适应蒸馏。
背景技术:
1、随着自动语音识别(asr)近年来的普及,asr正被更广泛地应用到世界各地的语言中。不幸的是,这些语言中的一些具有影响asr模型的质量或健壮性的限制。例如,语言资源可以从高到低不等,其中这些资源指asr模型利用来训练和提高精确度和健壮性的资源。由于资源差异,asr模型可能遇到不同程度的性能下降,这对于使用asr模型的应用或程序不可避免地影响用户的体验。
技术实现思路
1、本公开的方面提供了一种用于将一个或多个训练好的教师自动语音识别(asr)模型蒸馏为多语言学生模型的计算机实现的方法。当在数据处理硬件上执行时,计算机实现的方法使得数据处理硬件执行接收多个教师训练示例和多个学生训练示例的操作。操作还包括使用多个教师训练示例来训练一个或多个教师asr模型。每个教师asr模型被配置为输出相应音频输入的相应的文本表示。该操作还包括通过使用多个学生训练示例训练多语言学生asr模型以及使用可调蒸馏损失权重将训练的一个或多个教师asr模型蒸馏为多语言学生asr模型来生成多语言学生asr模型。每个学生asr模型被配置为接收音频输入并输出所接收的音频输入的相应的文本表示。
2、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,一个或多个教师asr模型被配置为共同地识别比多语言学生asr模型少的语言。可调蒸馏损失权重可以包括恒定值。在一些另外的实施方式中,训练多语言学生模型存在跨越n个训练步骤,并且可调蒸馏损失权重包括基于n个训练步骤而递减的递减函数。
3、在一些示例中,一个或多个教师asr模型和多语言学生asr模型中的每一个包括递归神经网络传感器(rnn-t)架构。在这些执行例中,可调蒸馏损失权重可以包括基于rnn-t损失的递减函数,rnn-t损失与一个或多个教师asr模型对应。或者,这些示例中的可调蒸馏损失权重可包括基于与一个或多个教师asr模型对应的第一rnn-t损失和与多语言学生asr模型对应的第二rnn-t损失的递减函数。这里,在一段时间内减少与一个或多个教师asr模型对应的第一rnn-t损失,以及在一段时间内增加与多语言学生asr模型对应的第二rnn-t损失。
4、一个或多个教师asr模型中的每一个教师asr模型可以对应于单语asr模型。或者,一个或多个教师asr模型可对应于单个多语言asr模型。
5、本公开的另一方面提供了一种用于将一个或多个训练好的教师自动语音识别(asr)模型蒸馏为多语言学生模型的系统。该系统包括数据处理硬件和与数据处理硬件通信的存储器硬件。存储器硬件存储指令,指令在数据处理硬件上执行时使数据处理硬件执行包括接收多个教师训练示例和多个学生训练示例的操作。操作还包括使用多个教师训练示例来训练一个或多个教师asr模型。每个教师asr模型被配置为输出相应音频输入的相应的文本表示。该操作还包括通过使用多个学生训练示例训练多语言学生asr模型以及使用可调蒸馏损失权重将训练的一个或多个教师asr模型蒸馏为多语言学生asr模型来生成多语言学生asr模型。每个学生asr模型被配置为接收音频输入并输出所接收的音频输入的相应的文本表示。
6、该方面可以包括一个或多个以下可选特征。在一些实施方式中,一个或多个教师asr模型被配置为共同地识别比多语言学生asr模型少的语言。可调蒸馏损失权重可以包括恒定值。在一些另外的实施方式中,训练多语言学生模型存在跨越n个训练步骤,并且可调蒸馏损失权重包括基于n个训练步骤而递减的递减函数。
7、在一些示例中,一个或多个教师asr模型和多语言学生asr模型中的每一个包括递归神经网络传感器(rnn-t)架构。在这些执行例中,可调蒸馏损失权重可以包括基于rnn-t损失的递减函数,rnn-t损失与一个或多个教师asr模型对应。或者,这些示例中的可调蒸馏损失权重可包括基于与一个或多个教师asr模型对应的第一rnn-t损失和与多语言学生asr模型对应的第二rnn-t损失的递减函数。这里,在一段时间内减少与一个或多个教师asr模型对应的第一rnn-t损失,以及在一段时间内增加与多语言学生asr模型对应的第二rnn-t损失。
8、一个或多个教师asr模型中的每一个教师asr模型可以与单语asr模型对应。或者,一个或多个教师asr模型可以与单个多语言asr模型对应。
9、本公开的一个或多个实现的细节在附图和以下描述中阐述。从说明书和附图以及从权利要求书中,其它方面,特征和优点将是显而易见的。
技术特征:1.一种计算机实现的方法(400),其特征在于,当由数据处理硬件(134)执行时使得所述数据处理硬件(134)进行操作,所述操作包括:
2.根据权利要求1所述的方法(400),其特征在于,所述一个或多个教师asr模型(210)被配置为共同地识别比所述多语言学生asr模型(200)少的语言。
3.根据权利要求1或2所述的方法(400),其特征在于,所述可调蒸馏损失权重(222)包括恒定值。
4.根据权利要求1-3中任一项所述的方法(400),其特征在于:
5.根据权利要求1-4中任一项所述的方法(400),其特征在于,所述一个或多个教师asr模型(210)和所述多语言学生asr模型(200)中的每一个包括递归神经网络传感器(rnn-t)架构。
6.根据权利要求5所述的方法(400),其特征在于,所述可调蒸馏损失权重(222)包括基于rnn-t损失的递减函数(210),所述rnn-t损失与所述一个或多个教师asr模型对应。
7.根据权利要求5或6所述的方法(400),其特征在于,所述可调蒸馏损失权重(222)包括基于与所述一个或多个教师asr模型(210)对应的第一rnn-t损失和与所述多语言学生asr模型(200)对应的第二rnn-t损失的递减函数。
8.根据权利要求7所述的方法(400),其特征在于,所述递减函数:
9.根据权利要求1-8中任一项所述的方法(400),其特征在于,所述一个或多个教师asr模型(210)中的每一个教师asr模型(210)与单语教师asr模型(210)对应。
10.根据权利要求1-9中任一项所述的方法(400),其特征在于,所述一个或多个教师asr模型(210)与单个多语言asr模型对应。
11.一种系统(100),其特征在于,包括:
12.根据权利要求11所述的系统(100),其特征在于,所述一个或多个教师asr模型(210)被配置为共同地识别比所述多语言学生asr模型(200)少的语言。
13.根据权利要求11或12所述的系统(100),其特征在于,所述可调蒸馏损失权重(222)包括恒定值。
14.根据权利要求11-13中任一项所述的系统(100),其特征在于,:
15.根据权利要求11-14中任一项所述的系统(100),其特征在于,所述一个或多个教师asr模型(210)和所述多语言学生asr模型(200)中的每一个包括递归神经网络传感器(rnn-t)架构。
16.根据权利要求15所述的系统(100),其特征在于,所述可调蒸馏损失权重(222)包括基于rnn-t损失的递减函数(210),所述rnn-t损失与所述一个或多个教师asr模型对应。
17.根据权利要求15或16所述的系统(100),其特征在于,所述可调蒸馏损失权重(222)包括基于与所述一个或多个教师asr模型(210)对应的第一rnn-t损失和与所述多语言学生asr模型(200)对应的第二rnn-t损失的递减函数。
18.根据权利要求17所述的系统(100),其特征在于,所述递减函数:
19.根据权利要求11-18中任一项所述的系统(100),其特征在于,所述一个或多个教师asr模型(210)中的每一个教师asr模型(210)与单语教师asr模型(210)对应。
20.根据权利要求11-19中任一项所述的系统(100),其特征在于,所述一个或多个教师asr模型(210)与单个多语言asr模型对应。
技术总结一种用于将一个或多个训练好的教师自动语音识别(ASR)模型(210)蒸馏为多语言学生模型(200)的方法(400),所述方法(400)包括接收多个教师训练示例(152)和多个学生训练示例(154)。所述方法也包括使用所述多个教师训练示例来训练一个或多个教师ASR模型。每一个教师ASR模型被配置为输出相应的音频输入的相应的文本表示。所述方法还包括使用所述多个学生训练示例训练多语言学生ASR模型来生成多语言学生ASR模型(222),并且使用可调蒸馏损失权重将训练好的所述一个或多个教师ASR模型蒸馏到所述多语言学生ASR模型。所述学生ASR模型被配置为接收音频输入(14)并且输出接收的所述音频输入的对应文本表示(142)。技术研发人员:伊莎贝尔·李尔,尼拉杰·高尔,帕里莎·哈哈尼,布莱恩·法里斯,布瓦那·拉马巴德兰,马纳萨·普拉萨德,佩德罗·J·莫雷诺门希瓦尔,朱云受保护的技术使用者:谷歌有限责任公司技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20997.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表