一种语音识别方法及系统
- 国知局
- 2024-06-21 10:39:39
本发明涉及语音识别的,尤其涉及一种语音识别方法及系统。
背景技术:
1、语言是人类最主要的交流方式之一,随着人工智能的不断发展进步,语言不仅用于人与人之间的日常交流,还用于人机交流,且人机交互越来越频繁与深入。现有的人机交互技术中,包括语言交互和语音交互等,语言交互是人通过手动操作,将字符信号输入至机器中,机器做出相应的反映,而语音交互是人将语音作为信号传输至机器中,机器做出相应的反应。
2、现有常用于语音识别技术的方法主要有lpcc(线性预测倒谱系数)、mfcc(mel频率倒谱系数)、分数阶gfcc(gammatone频率倒谱系数)以及它们的一些组合与各种深度学习模型等。lpcc是一种用于提取音频信号特征的方法,它通过线性预测分析(lpc)提取语音信号的预测系数,这些系数描述了信号的的频率特性与共振峰,对这些系数进行倒谱分析得到lpcc系数,以捕捉语音信号的主要特性。mfcc是基于梅尔尺度(mel scale),将音频信号的频谱转换为与人耳感知特性接近的尺度,通过一系列预处理后通过梅尔滤波器与离散余弦变换(dct)得mfcc倒谱系数,并结合差分系数结合成完整的mfcc系数。而gfcc是在gammatone滤波器基础上改进的一种特征提取方法,它模拟了人耳对不同频率的敏感性,对音频信号滤波得到滤波器系数,再通过dct变化得到gfcc系数。
3、然而,上述方法存在动态特性建模能力与线性预测的抗噪声能力较弱,导致适用的场景受到限制,且对数据量要求高,在数据量少的情况下性能会断崖式下降,导致语音识别性能受限,从而语音识别的工作量增大。现有技术公开一种语音识别神经网络模型及其训练方法、语音识别方法,解决了基于cnn的语音识别方法导致cnn的模型参数量过大且难以优化、以及语音识别性能受限的问题。但该方案仍存在动态特性建模能力与线性预测的抗噪声能力较弱,无法准确地分析语音信号的变化和动态特性,从而无法有效的捕捉语音信号的频率细节,导致语音识别性能较差的问题。
技术实现思路
1、为解决现有语音识别技术存在语音识别性能差导致语音识别工作量大的问题,本发明提出一种语音识别方法及系统,可以有效地捕捉语音信号的频率细节,提升语音识别的性能,进而减小语音识别的工作量。
2、为实现本发明的目的,本发明采用如下技术方案实现:
3、一种语音识别方法,包括以下步骤:
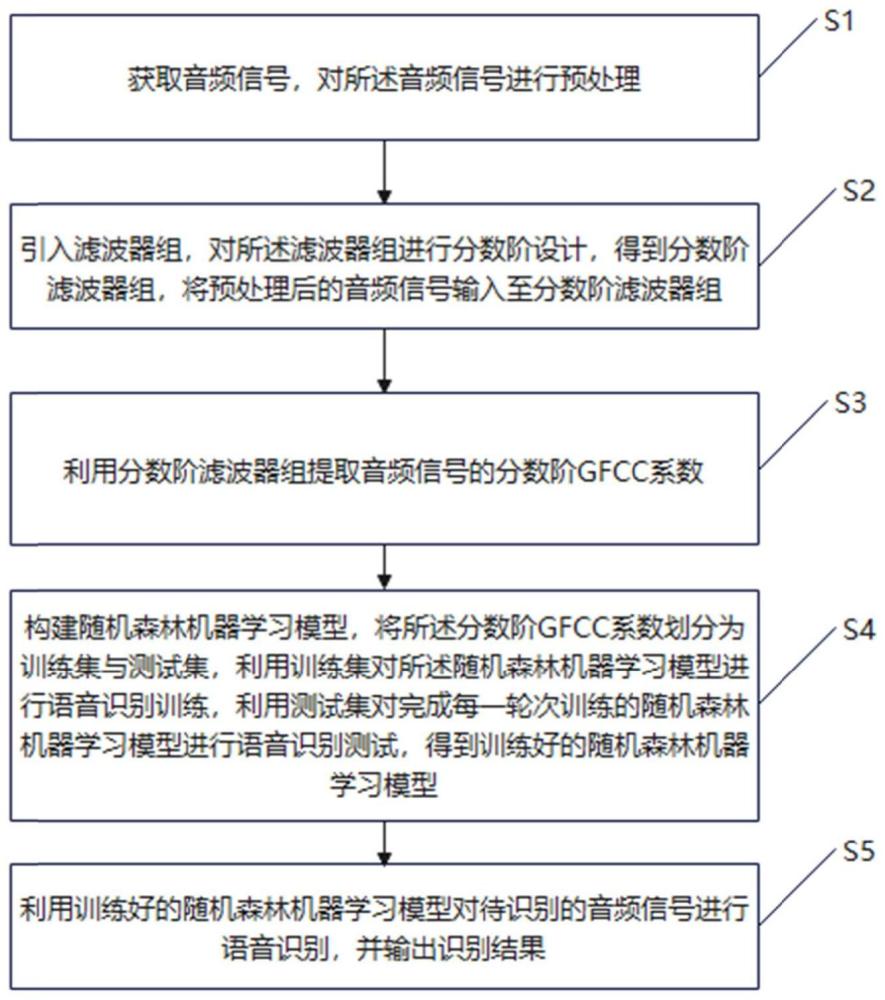
4、s1:获取音频信号,对所述音频信号进行预处理;
5、s2:引入滤波器组,对所述滤波器组进行分数阶设计,得到分数阶滤波器组,将预处理后的音频信号输入至分数阶滤波器组;
6、s3:利用分数阶滤波器组提取音频信号的分数阶gfcc系数;
7、s4:构建随机森林机器学习模型,将所述分数阶gfcc系数划分为训练集与测试集,利用训练集对所述随机森林机器学习模型进行语音识别训练,利用测试集对完成每一轮次训练的随机森林机器学习模型进行语音识别测试,得到训练好的随机森林机器学习模型;
8、s5:利用训练好的随机森林机器学习模型对待识别的音频信号进行语音识别,并输出识别结果;
9、其中,gfcc系数表示gammatone频率倒谱系数。
10、在上述技术发中,对获取的音频信号进行预处理,能够有效的提高音频信号在使用过程中的有效性;对滤波器组进行分数阶设计,能够将滤波器组在时域上频率转换为频域上频率,得到分数阶滤波器组,进而增强语音识别过程中频率分辨的能力,从而更好地捕捉语音信号的频率细节,同时,分数阶滤波器组能够在时域与频域上更准确的分析语音信号的变化和动态特性,进而更好地捕捉语音信号中的非线性变换,从而有效地提取音频信号的分数阶gfcc系数;利用提取的gfcc系数对构建的随机森林机器学习模型进行训练与测试,能够得到一个满足预期要求并用于的语音识别随机森林机器学习模型,利用所述随机森林机器学习模型对待识别的语音信号进行语音识别,能够有效地捕捉语音信号的频率细节,提升语音识别的性能,进而减小语音识别的工作量。
11、步骤s1所述的对所述音频信号进行预处理的具体过程为:
12、s11:将音频信号划分为有声音频信号与无声音频信号,将无声音频信号切割剔除,保留有声音频信号;
13、s12:对有声音频信号进行预加重处理;
14、s13:将预加重处理后的有声音频信号进行分帧,对分帧后的每一帧有声音频信号进行加窗处理。
15、步骤s11中将无声音频信号切割剔除方法为语音活动检测方法vad。
16、在步骤12中,使用预加重函数对有声音频信号进行预加重处理,预加重函数表达式为:
17、
18、其中,α表示加重权重,表示vad切割后的有声音频信号段。
19、在步骤s13中,使用加窗函数对分帧后的每一帧有声音频信号进行加窗处理,加窗函数表达式为:
20、x(n)=z(n)w(n);
21、其中,w(n)表示窗函数,x(n)表示加窗后的有声音频信号,z(n)表示预加重后的有声音频信号。
22、根据上述技术方案,利用语音活动检测方法vad将音频信号中的无声音频信号剔除,保留有声音频信号,能够减少随机森林机器学习模型的训练量,进而减少训练时间,且增加训练的稳定性;对有声音频信号进行预加重处理,能够有效补偿声音在空气中传播损失的高频分量;对有声音频信号进行分帧,能够有效地将一整段有声音频信号划分为若干份一定程度的短时帧有声音频信号,对分帧后的每一帧有声音频信号进行加窗,能够有效地将每一帧有声音频信号独立出来,进而方便使用的过程中,更容易的提取使用。
23、步骤s2所述的对所述滤波器组进行分数阶设计的具体过程为:
24、s21:引入一个gammatone滤波器组,设所述gammatone滤波器组包含m个gammatone滤波器,每一个gammatone滤波器在时域上的频率为hi(t),表达式为:
25、
26、其中,mi表示滤波器的阶数,bi表示滤波器的带宽,ai、fi、φ分别表示滤波器的振幅、中心频率和相位,i表示第i个gammatone滤波器,i=0,...,m-1,表示单位阶跃函数;
27、s22:设用于对gammatone滤波器进行分数阶设计的分数阶微分函数为dp,表达式为:
28、
29、其中,dp表示第p阶导数算子,p≥1,γ(z)表示gamma函数,0≤1-p≤z;
30、s23:利用分数阶微分函数dp将每一个gammatone滤波器在时域上的频率转化为频域上的频率,得到分数阶gammatone滤波器组在频域上的频率h(ω),表达式为:
31、
32、其中,j表示虚数,i=0,...,m-1。
33、根据上述技术方案,利用分数阶微分函数为dp对gammatone滤波器组中的每一个gammatone滤波器进行进行分数阶设计,进而将gammatone滤波器组在时域上的频率转化为频域上的频率,得到分数阶gammatone滤波器组在频域上的频率h(ω),分数阶gammatone滤波器组能够在时域与频域上更准确的分析语音信号的变化和动态特性,进而更好地捕捉语音信号中的非线性变换,从而有效地提取音频信号的分数阶gfcc系数。
34、步骤s3所述的利用分数阶gammatone滤波器组提取音频信号的分数阶gfcc系数的具体过程为:
35、s31:利用分数阶gammatone滤波器组从加窗后每一帧有声音频信号中提取m个分数阶gammatone滤波器系数s(i),表达式为:
36、
37、其中,n表示每一帧有声音频信号的长度,x(ω)表示每一帧有声音频信号的频域表达,hi(ω)表示第i个gammatone滤波器在频域上的频率;
38、s32:将m个分数阶gammatone滤波器系数s(i)进行离散余先变换dct,得到分数阶gammatone滤波器组从每一帧有声音频信号中提取出对应的分数阶gfcc系数;
39、s33:将从每一帧有声音频信号中提取的分数阶gfcc系数进行累加,得到输入分数阶gammatone滤波器组的完整有声音频信号的分数阶gfcc系数c(p),表达式为:
40、
41、其中,p表示预设的值。
42、在上述技术方案中,利用分数阶gammatone滤波器组对应提取每一帧的有声音频信号中的分数阶gammatone滤波器系数s(i),再将提取的分数阶gammatone滤波器系数s(i)进行离散余先变换操作,得到分数阶gammatone滤波器组从每一帧有声音频信号中提取出对应的分数阶gfcc系数,最后,将提取的所有分数阶gfcc系数进行累加,得到输入分数阶gammatone滤波器组的完整有声音频信号的分数阶gfcc系数c(p),有效的得到训练模型所需的数据集,进而对随机森林机器学习模型进行训练与测试。
43、步骤s4所述的利用训练集对所述随机森林机器学习模型进行语音识别训练的具体过程为:
44、设置k轮次的训练次数,将分数阶gfcc系数c(p)划分为训练集t1和测试集t2;
45、将训练集t1输入至随机森林机器学习模型中,对所述随机森林机器学习模型进行语音识别训练,对所述随机森林机器学习模型进行训练的过程中,使用交叉熵函数对随机森林机器学习模型中的参数进行优化,利用测试集t2对完成每轮次训练的随机森林机器学习模型进行测试,当交叉熵损失函数的值收敛或训练达到训练轮次数上限值时,得到训练完成的随机森林机器学习模型,利用所述随机森林机器学习模型对待识别的音频信号进行语音识别,并输出结果。
46、利用训练集t1对所述随机森林机器学习模型进行语音识别训练时,采用自适应动量优化器adam。
47、根据上述技术方案,设置k轮次的训练次数,能够更好的利用测试集对训练过程中每一个轮次训练完成的随机森林机器学习模型进行测试比较,进而判断随机森林机器学习模型训练的效果,在训练的过程中,使用交叉熵损失函数与自适应动量优化器adam对随机森林机器学习模型的进行不断地优化,保证训练得到的随机森林机器学习模型能够得到预期的训练效果,进而保证训练完成的随机森林机器学习模型在对待识别的音频信号进行语音识别的过程中,能够有效地捕捉语音信号的频率细节,提升语音识别的性能,进而减小语音识别的工作量。
48、一种语音识别系统,包括:
49、获取模块,用于获取音频信号;
50、处理模块,用于对获取的音频信号进行预处理;
51、设计模块,用于对引入的滤波器组进行分数阶设计,得到分数阶滤波器组;
52、提取模块,用于将预处理后的音频信号输入至分数阶滤波器组,利用分数阶滤波器组提取音频信号的分数阶gfcc系数;
53、划分模块,用于将所述分数阶gfcc系数划分为训练集与测试集;
54、构建模块,用于构建随机森林机器学习模型;
55、所述处理模块,还用于利用训练集对所述随机森林机器学习模型进行语音识别训练,利用测试集对训练后的随机森林机器学习模型进行语音识别测试,得到训练后的随机森林机器学习模型;
56、检测模块,用于利用随机森林机器学习模型对待识别的音频信号进行语音识别,并输出识别结果;
57、其中,gfcc系数表示gammatone频率倒谱系数。
58、相比现有技术,本发明的有益效果在于:
59、本发明提出一种语音识别方法及系统,首先,对获取的音频信号进行预处理,能够有效的提高音频信号在使用过程中的有效性;然后,对滤波器组进行分数阶设计,能够将滤波器组在时域上频率转换为频域上频率,得到分数阶滤波器组,进而增强语音识别过程中频率分辨的能力,从而更好地捕捉语音信号的频率细节,同时,分数阶滤波器组能够在时域与频域上更准确的分析语音信号的变化和动态特性,进而更好地捕捉语音信号中的非线性变换,从而有效地提取音频信号的分数阶gfcc系数;最后,利用提取的gfcc系数对构建的随机森林机器学习模型进行训练与测试,能够得到一个满足预期要求并用于的语音识别随机森林机器学习模型,利用所述随机森林机器学习模型对待识别的语音信号进行语音识别,能够有效地捕捉语音信号的频率细节,提升语音识别的性能,进而减小语音识别的工作量。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21023.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表