一种基于说话人信息的未成年人识别方法和系统与流程
- 国知局
- 2024-06-21 10:39:34
本技术涉及基于说话人信息的未成年人识别,特别是涉及一种基于说话人信息的未成年人识别方法和系统。
背景技术:
1、在现代社会中,随着互联网技术的发展,各种形式的在线媒体和社交平台越来越受到人们的关注和使用。然而,这些平台中也存在着一些不良信息和不良行为,其中包括对未成年人的侵害。为了保护未成年人的利益和隐私,各种形式的未成年人审核已经成为了在线媒体和社交平台的必要措施之一。
2、目前,对未成年人进行识别的方法为,将音频信号直接送到分类识别引擎中,通过和未成年人模版比较距离或者是通过模型对未成年人打分进行判断。然而,由于这些方法需要大量且场景丰富的人工标注数据进行模型训练,同时未成年人生理发育有差异,导致当前现有方法识别准确率不高。
技术实现思路
1、本技术提供一种基于说话人信息的未成年人识别方法和系统以解决现有未成年人识别方案成本过高且准确率不高的问题。
2、第一方面,一种基于说话人信息的未成年人识别方法,所述方法包括:
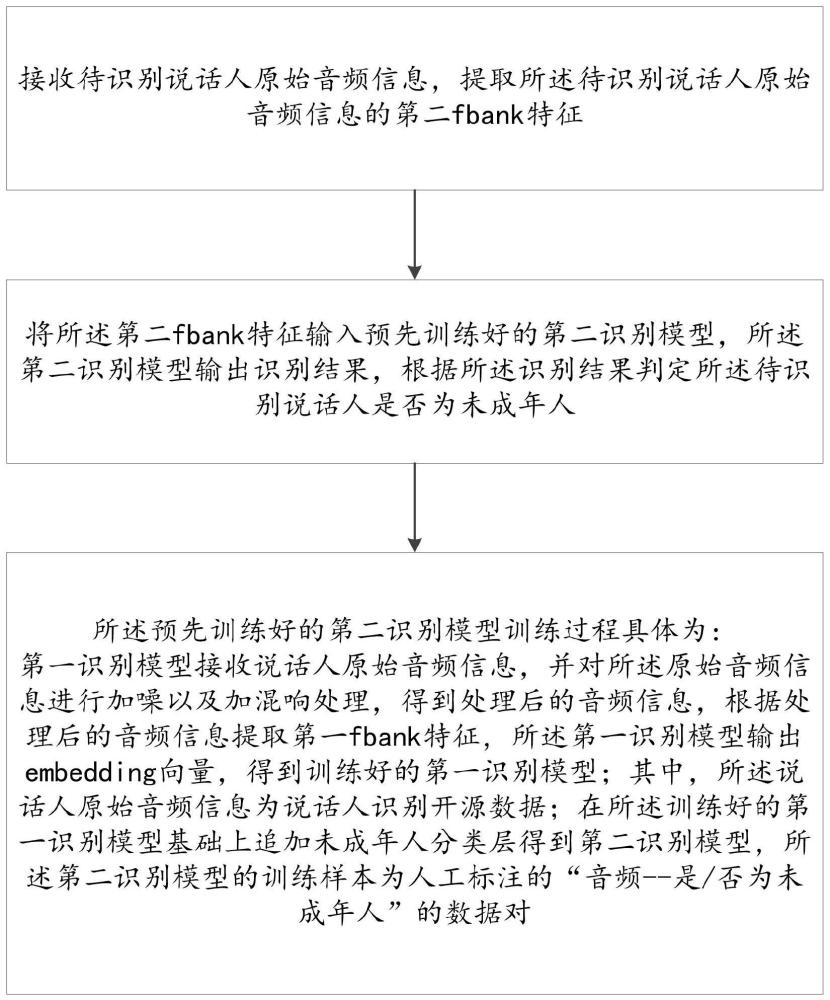
3、接收待识别说话人原始音频信息,提取所述待识别说话人原始音频信息的第二fbank特征;
4、将所述第二fbank特征输入预先训练好的第二识别模型,所述第二识别模型输出识别结果,根据所述识别结果判定所述待识别说话人是否为未成年人;
5、其中,所述预先训练好的第二识别模型训练过程具体为:
6、第一识别模型接收说话人原始音频信息,并对所述原始音频信息进行加噪以及加混响处理,得到处理后的音频信息,根据处理后的音频信息提取第一fbank特征,所述第一识别模型输出embedding向量,得到训练好的第一识别模型;其中,所述说话人原始音频信息为说话人识别开源数据;
7、在所述训练好的第一识别模型基础上追加未成年人分类层得到第二识别模型,所述第二识别模型的训练样本为人工标注的“音频--是/否为未成年人”的数据对。
8、上述方案中,可选的,所述embedding向量为说话人信息表征;
9、所述说话人识别开源数据为cn-celeb、cn-celeb2两个中文说话人识别开源数据集,总计时长1000小时以上,其中,训练样本为说话人音频与说话人id相对应的数据对,说话人识别模型输出结果为256维的向量。
10、上述方案中,可选的,所述原始音频信息进行加噪以及加混响处理,得到处理后的音频信息包括:
11、对原始音频数据进行加噪及加混响处理,其中,所述加噪处理具体为:噪声数据来自真实场景录制噪声和仿真得到的高斯噪声,将所述高斯噪声与原始音频数据进行线性相加得到带噪数据,信噪比控制在0~30db范围内;
12、所述混响处理中混响数据来自真实环境采集数据和仿真模拟得到的脉冲响应信号,与原始音频数据进行卷积操作得到加混响数据。
13、上述方案中,可选的,所述根据所述处理后的音频信息提取fbank特征,具体包括:
14、首先对处理后的音频信息进行预加重、分帧、加窗处理,其中,帧长25ms,帧移10ms,窗类型选择汉明窗;
15、通过傅立叶变换转换到频域,得到频域数据;
16、计算所述频域数据能量谱,送到梅尔滤波器中,得到80维频域信息,并进行log运算,得到所述处理后的音频信息的fbank特征。
17、上述方案中,可选的,所述第一识别模型为说话人识别模型,训练过程具体包括:
18、所述说话人识别模型构建:搭建resnet网络结构,参数随机初始化;
19、将原始训练音频数据提取的fbank特征送入模型,模型输出为高维特征向量,所述高维特征向量为embedding向量,将所述高维特征向量送入说话人分类层计算每个说话人的概率;使用交叉熵损失函数,通过梯度下降算法优化模型参数;使用adam优化器,初始学习率设置为0.002,使用warmup策略调整学习率,预热步数设置为1000;训练总轮数设置为30轮。
20、上述方案中,可选的,所述搭建resnet网络结构包括:输入卷积层,包括1层卷积层、batch norm层和relu激活层;深度卷积层,包括32层卷积层,其中每经过2层卷积会进行一次残差连接,用来缓解随着模型深度增加性能变差的问题;平均池化层,在时间维度上对频域信息作平均,将帧级别信息转化为段级别信息;特征提取层,将上一模块输出的段级别信息转化为256维频域特征,用来表征说话人信息。
21、上述方案中,可选的,将原始训练音频数据提取的fbank特征送入模型,具体为:
22、原始训练音频数据提取的fbank特征包括处理原始训练音频数据对应的说话人识别数据,对训练数据进行加噪、加混响处理,然后提取fbank特征得到数据的频域表征;其中,对训练数据进行加噪、加混响处理包括对原始音频数据进行加噪及加混响处理,所述加噪处理具体为:噪声数据来自真实场景录制噪声和仿真得到的高斯噪声,将所述高斯噪声与原始音频数据进行线性相加得到带噪数据,信噪比控制在0~30db范围内;所述混响处理中混响数据来自真实环境采集数据和仿真模拟得到的脉冲响应信号,与原始音频数据进行卷积操作得到加混响数据。
23、上述方案中,可选的,所述第二识别模型为未成年人识别模型,训练过程具体为:
24、采用第一识别模型相同的特征提取方法,提取原始音频数据的频域特征;
25、在所述第一识别模型追加一个未成年人分类层,构建整体模型;
26、将所述未成年人识别模型和第一识别模型结构相同部分的参数用训练好的第一识别模型参数作为初始化,不同部分的参数随机初始化;
27、将原始音频数据提取特征送入第二识别模型进行预测,模型输出对应预测的是否为未成年人概率;使用交叉熵损失函数,通过梯度下降算法优化模型参数,和第一识别模型相比,训练未成年人识别模型时初始学习率调整为原来的1/20,剩余参数不变。
28、第二方面,一种基于说话人信息的未成年人识别系统,所述系统包括:
29、输入模块:用于接收待识别说话人原始音频信息,提取所述待识别说话人原始音频信息的第二fbank特征;
30、输出模块:用于将所述第二fbank特征输入预先训练好的第二识别模型,所述第二识别模型输出识别结果,根据所述识别结果判定所述待识别说话人是否为未成年人;
31、训练模块:第一识别模型接收说话人原始音频信息,并对所述原始音频信息进行加噪以及加混响处理,得到处理后的音频信息,根据处理后的音频信息提取第一fbank特征,所述第一识别模型输出embedding向量,所述说话人原始音频信息为训练集,所述训练集具体为说话人识别开源数据,得到训练好的第一识别模型;
32、在所述训练好的第一识别模型基础上追加未成年人分类层得到第二识别模型,所述第二识别模型的训练样本为人工标注的“音频--是/否为未成年人”的数据对。
33、相比现有技术,本技术至少具有以下有益效果:
34、本技术基于对现有技术问题的进一步分析和研究,认识到现有未成年人识别方案成本过高且准确率不高的问题。本发明通过接收待识别说话人原始音频信息,提取所述待识别说话人原始音频信息的第二fbank特征;将所述第二fbank特征输入预先训练好的第二识别模型,所述第二识别模型输出识别结果,根据所述识别结果判定所述待识别说话人是否为未成年人;其中,所述预先训练好的第二识别模型训练过程具体为:第一识别模型接收说话人原始音频信息,并对所述原始音频信息进行加噪以及加混响处理,得到处理后的音频信息,根据处理后的音频信息提取第一fbank特征,所述第一识别模型输出embedding向量,得到训练好的第一识别模型;其中,所述说话人原始音频信息为说话人识别开源数据;在所述训练好的第一识别模型基础上追加未成年人分类层得到第二识别模型,所述第二识别模型的训练样本为人工标注的“音频--是/否为未成年人”的数据对。本方案充分利用可获取资源,和说话人标注数据相比,未成年人标注数据稀缺,将说话人分类任务作为未成年人识别任务的上游任务,和传统分类方法相比,既降低了未成年人数据采集、标注成本,又提高了模型的准确性和鲁棒性,可以得到更高的识别准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21007.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表