基于噪声抑制残差网络的语音关键词识别方法
- 国知局
- 2024-06-21 10:39:34
本发明涉及语音识别,具体涉及基于噪声抑制残差网络的语音关键词识别方法。
背景技术:
1、深度学习算法进入了一个新的阶段,在语音识别等各种认知任务中,其准确性已经超过人类。越来越多的人工智能产品也进入到我们的日常生活中,人们工作、学习和生活的效率得到了极大提高。语音交互解放了人们的双手和双眼,将用户手部的工作量转移到语音交互设备,语音交互设备将语音转换成文字,再根据文字的内容对设备进行具体的指令控制,例如语音助手、命令控制、智能家居、手机等,在需要多种感官协同操作的场景下效率更高。语音交互设备大部分时间处于睡眠状态,等待并时刻检测唤醒词,当唤醒词发生时则监听用户的语音输入,激活语音交互程序。语音交互越来越成为未来科技感生活的潮流,从集成在其他设备中的辅助工具到独立的语音交互产品,也反映了语音交互的飞跃发展。
2、语音交互产品大多数都属于小型的嵌入式设备,并且使用语音关键词识别模型检测唤醒词,因此关键词识别模型要求占用内存小,计算低,同时还要保证检测的准确性,避免过多消耗语音交互设备有限的电量。此外,现有的语音关键词识别模型测试通常在实验室的安静环境中进行,但是在现实环境中伴随着不同的噪声和干扰,这会使得关键词识别模型的准确性大幅下降。关键词识别任务在噪声环境下的表现是至关重要的,因为这决定了用户在开放的现实场景中能否顺利和设备进行交互。现实生活场景中,各种各样的噪声是不可避免的,因此构建一个轻量级的,噪声鲁棒性高的语音关键词识别模型是亟需解决的问题。
3、基于深度学习的语音关键词识别模型是一种高度智能化的技术,它通过深度神经网络架构、数据集以及数据增强技术等手段来提高准确率。这些模型使用深度神经网络以学习语音特征的表示,通过在大规模数据集上进行训练,模型可以更好地适应各种发音、口音和说话方式,提高鲁棒性。此外,数据增强技术的应用,包括引入各种噪声和变换,有助于模型在不同的噪声环境下表现出色,并且还可以通过优化模型结构和参数来降低模型内存占用,实现更轻量级的语音关键词识别模型。目前主要技术可以从模型实现方法分为以下两类:
4、(1)基于卷积的语音关键词识别模型。卷积神经网络cnn能够通过卷积核在不同时间尺度上滑动,从而捕捉到音频信号中的局部特征和频率信息。这使得它们能够有效地识别发音中的语音片段和声音模式。此外,cnn的参数共享机制使得模型具有相对较少的可调参数,这有助于减轻过拟合的风险,尤其是在训练数据有限的情况下。另外,卷积操作可以并行计算,因此在一定程度上提高了模型的计算效率。目前有很多基于卷积的语音关键词识别模型,例如bc-resnet,在语音关键词识别任务中表现出良好效果。但cnn的卷积核在每一层都只能感受输入数据的局部信息,这意味着它们可能会错过全局上下文中的重要信息,所以其鲁棒性相对较低。故当模型面临不同的噪声环境、口音变化或语速变化时,其性能可能会受到明显的影响。
5、(2)基于注意力模型的语音关键词识别模型。例如ast[3]模型,在处理语音数据时表现出了独特的优势。注意力允许模型在不同的时间步上动态地分配权重,以便关注到输入序列中的重要信息,这使得模型能够更好地捕捉长距离的上下文和语音信号中的关键部分。这对于处理具有变长输入或需要上下文理解的任务尤其有益。此外,基于注意力的模型通常能够更好地适应不同的噪声环境和口音变化,因为它们能够灵活地调整关注的重点;但通常具有更多的参数,这可能导致在训练和推理时需要更多的计算资源。这在资源有限的嵌入式设备上会过多的占用内存空间。另外,模型的复杂性也增加了过拟合的风险,因此需要更多的数据来进行有效训练,这可能在数据稀缺的情况下成为挑战。
技术实现思路
1、本发明的目的在于,提出基于噪声抑制残差网络的语音关键词识别方法,通过鲁棒性高的轻量级语音关键词识别模型,以提高识别准确率,且在保证识别性能的前提下降低模型参数量。
2、为实现上述目的,本技术提出的基于噪声抑制残差网络的语音关键词识别方法,包括:
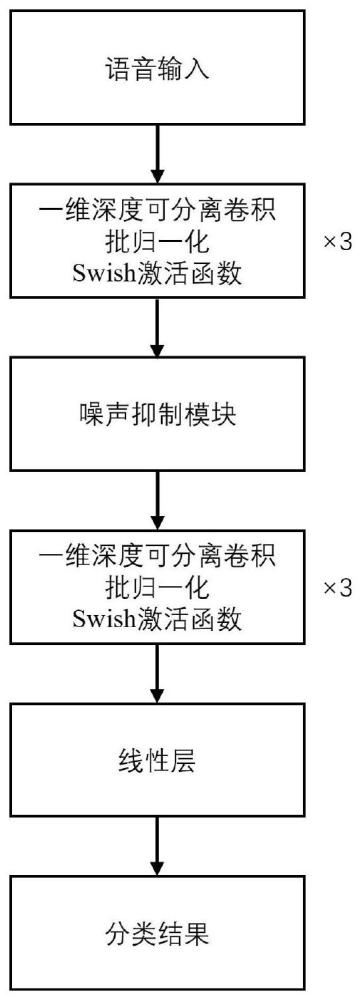
3、通过第一卷积层对语音信息进行处理获得初步语音特征;
4、构建噪声抑制残差模块,该模块在处理初步语音特征同时降低不相关信息对语音特征的干扰;
5、通过第二卷积层对噪声抑制残差模块输出的语音特征进行处理获得最终语音特征;
6、所述最终语音特征经过最大池化层和全连接层后,得到关键词识别结果。
7、进一步地,所述第一卷积层设置3个,每个卷积层包括一维深度可分离卷积、批归一化和swish激活函数,其卷积核大小分别设置为3、5、1。
8、进一步地,所述第二卷积层设置3个,每个卷积层包括一维深度可分离卷积、批归一化和swish激活函数,其卷积核大小分别设置为17、19、1,卷积滤波器数量设置为128,128,128。
9、进一步地,在噪声抑制残差模块中,初步语音特征先经过频域特征提取层,再进入时域特征提取层,最后经过噪声抑制层的处理,与两个跳跃链接所携带的特征进行叠加,得到输出特征。
10、进一步地,所述噪声抑制残差模块实现的整体流程为:
11、y1=δ*bwn(f(δ*f2(δ*f(x)))) (1)
12、z=δ*bn(f1(y1)) (2)
13、y=x+y1+ns(z) (3)
14、其中,式(1)展示了频域特征提取层,其使用卷积计算频率维度的信息,f代表二维卷积,δ代表swish激活函数,f2代表二维深度可分离卷积,bwn代表频带加权归一化;式(2)展示了时域特征提取层,其中f1代表一维深度可分离卷积,bn为批归一化;式(3)展示了噪声抑制残差模块最终输出,ns代表噪声抑制层。
15、更进一步地,当初步语音特征流入频域特征提取层时,此时特征形状为忽略batch维度后,将初步语音特征x的形状以表示,其中h和w分别表示特征矩阵的高度和宽度;在提取频域特征时为了拟合二维深度可分离卷积的输入形状,使用unsqueeze函数为其增加一个维度,此时特征形状为之后通过二维卷积层并增加通道数量与swish激活函数处理,再经过二维深度可分离卷积提取频域特征与swish激活函数处理,最后使用二维卷积层还原通道数量并进行频带加权归一化与swish激活函数处理,最终通过squeeze函数压缩回形状作为频域特征提取层的输出y1;此时特征y1会被记录,通过跳跃链接方式与模块最终输出叠加,以增加特征丰富度;之后特征y1进入时域特征提取层,在此层中特征通过一维深度可分离卷积、批归一化和swish激活函数处理得到特征z,将特征z传进入噪声抑制层。
16、更进一步地,在噪声抑制层中特征z被复制两份,即z1、z2,并通过两个以ctime和cfreq表示的二维卷积,分别对时间维度和频率维度进行卷积:特征z1经过unsqueeze函数处理后通过卷积核大小为h×3的ctime得到形状为的特征t,之后将其广播至形状与特征z叠加;特征z2经过转置后,通过卷积核大小为w×3的cfreq得到形状为的特征u,并广播至形状后与特征z的转置zt叠加;此过程描述为:
17、t=ctime(z) (4)
18、u=cfreq(zt) (5)
19、其中t=(t1,...,tw),u=(u1,...,uh);不同的ti和ui携带信息重要程度不同,其分别表示了在时域与频域中语音信息重要性的变化情况。
20、更进一步地,在噪声抑制层中特征z经过layernorm归一化层与swish激活函数后作为噪声抑制层的输出,并与两个跳跃链接所携带的特征进行叠加;整体的噪声抑制层描述为:
21、
22、其中t代表经过时间卷积的特征,u代表经过频率卷积的特征,layernorm代表层归一化,bc代表广播操作。
23、作为更进一步地,在提取频域特征时二维卷积中使用了频带加权归一化方式,具体为:将特征划分为n个子带使其形状成为此时特征x=(x0,...,xn-1),并初始化与子带数量相同的n个初始值为1的可学习权重参数αi,i∈{1,n},其取值范围为[0,2];将所有的可学习参数αi归一化至区间[0,1]后,将每个可学习参数αi与对应的子带xi,i∈[0,n)相乘,为n个子带赋予可更新的权重参数;此过程描述为:
24、xi=x[b,i,h/n,w]×αi (7)
25、式(7)描述了对特征x中的不同子带进行加权;其中xi代表第i个子带,αi代表子带对应的可学习权重参数。这样可以通过对不同频带中信息的重要性进行调整,使得模型能够更加关注有价值的语音信息。
26、作为更进一步地,频带加权归一化方式还包括:将特征通道数量还原为原来特征形状经过频带加权后的特征记录为对于一个batch中的不同特征表示为将归一化过程描述为:
27、
28、
29、
30、式(8)描述了计算均值的过程,式(9)描述了计算方差的过程,式(10)描述将对应的输入进行归一化后得到的输出yi;其中i∈[1,m]代表batch中不同语音特征的同一通道经过频带加权后的输出,m代表batchsize大小;yi,i∈{1,m}代表经过归一化后对应的输出;μ代表均值,σ代表方差;γ和β分别代表可学习的比例参数和偏差参数。
31、本发明采用的以上技术方案,与现有技术相比,具有的优点是:本发明构造了基于噪声抑制残差模块的关键词识别模型,提出了噪声抑制层和频带加权归一化方法,以应对在噪声条件下关键词识别模型鲁棒性低的问题。其中噪声抑制残差模块能从频域、时域两个维度中降低噪声对语音的干扰从而提升模型性能。提出的频带加权归一化方法会对不同频带信息进行重要性调整,使模型能够更加关注高价值的频带信息并降低不相关频带信息的干扰,进一步提高关键词识别模型在噪声条件下的性能。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21005.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表