基于LIDAN的跨库语音情感识别方法及装置
- 国知局
- 2024-06-21 10:39:34
本发明涉及语音情感识别技术,尤其涉及一种基于lidan的跨库语音情感识别方法及装置。
背景技术:
1、伴随着计算机技术、信息技术、人工智能的飞速发展,人机交互的智能化、人性化需求越来越大,人们迫切希望一种可以自动探测并识别人类情感状态的智能设备问世,用以更好的为人类服务。语音是人类在日常生活中最基本、最直接的一种交流方式,包含着人类丰富的情绪信息,在人类的日常生活中发挥着重要作用,它可以揭示人类的自然情感状态。因此,使机器可以从人类的语音信号中自动理解情感状态,也就是语音情感识别研究有着巨大的潜在价值,目前也已成为情感计算、人机交互、语音信号处理等领域中的研究热点。
2、然而大部分现有的语音情感识别研究大都考虑的是在一个非常理想的环境下实现,即训练和测试语音样本来自同一个语音数据库,这距离真实场景仍有一定距离,其泛化性难以满足在真实场景中应用的需求。由于录制设备的不同、录制场地的不同、录制人员的语种不同、录制人员年龄段不同等因素的影响,在训练环境下性能优异的语音情感识别模型在测试环境中时可能会出现明显的性能下降。基于上述情况,研究者们引入了一个新的更具有挑战性的语音情感识别任务,即跨库语音情感识别任务。在跨库语音情感识别任务中,有情感标记的训练(源域)数据和无情感标记的测试(目标域)数据来自不同的语音情感数据库。
3、申请号为202211010176.6的专利文献公开了一种基于渐进式分布适配神经网络(progressive distribution adapted neural networks,pdan)的跨库语音情感识别方法及装置,该方案基于渐进式分布适配神经网络的跨库语音情感识别模型进行语音情感识别,但是该方案基于显式分布对齐的思想,使用最大均值差异(mmd)以及其变体来衡量训练语音数据和测试语音数据之间的边缘特征分布差异、粗粒度情感条件特征分布差异、细粒度情感条件特征分布差异,需要额外的计算步骤来精确预测原始无情感标记的测试语音样本的情感类别,并对训练数据和测试数据的特征分布进行统计估计,在很大程度上依赖于相应神经网络层中学习到的特征的情感判别能力,资源消耗较高、模型运算效率较低。
技术实现思路
1、发明目的:本发明针对现有技术存在的问题,提供一种计算资源消耗更低、运算效率更高的基于lidan的跨库语音情感识别方法及装置。
2、技术方案:本发明所述的基于lidan的跨库语音情感识别方法,包括如下步骤:
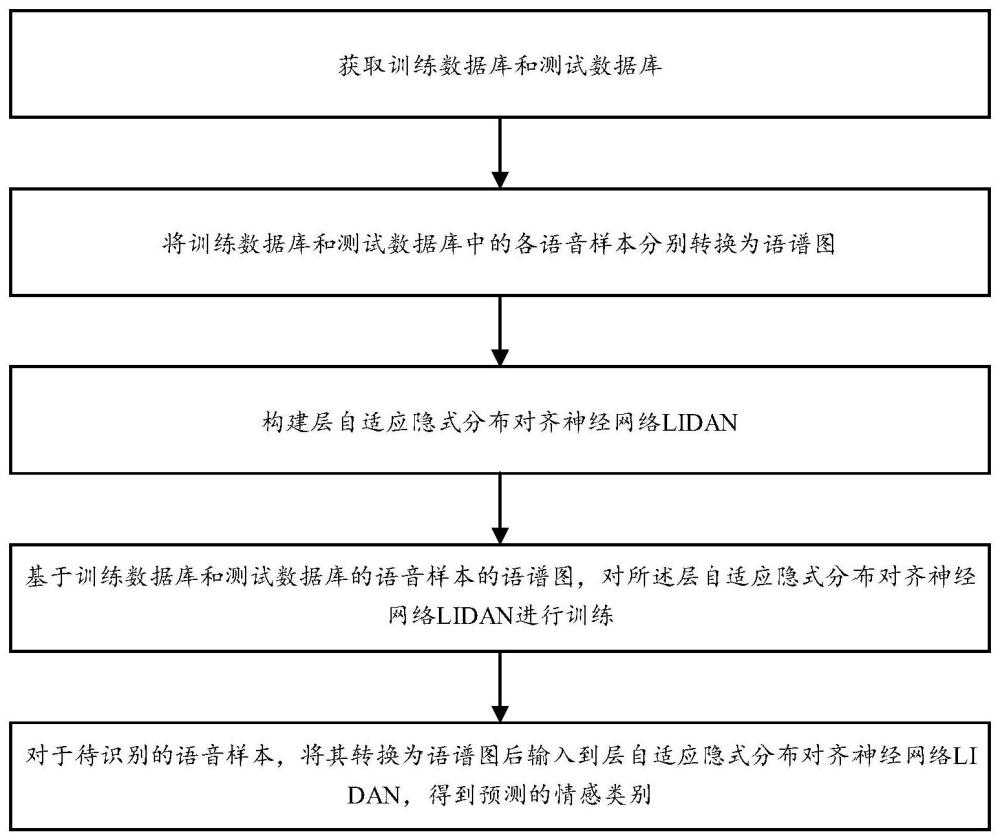
3、(1)获取训练数据库和测试数据库,其中训练数据库包括若干带有情感标签的训练语音样本,测试数据库包括若干不带有情感标签的测试语音样本;
4、(2)将训练数据库和测试数据库中的各语音样本分别转换为语谱图;
5、(3)构建层自适应隐式分布对齐神经网络lidan,包括:
6、卷积神经网络,用于从输入中提取语音特征;
7、多层感知机,包括三层依次连接的感知层,用于从语音特征中感知语音情感特征;
8、情感分类器,用于对多层感知机输出的语音情感特征进行分类得到情感类别;
9、深度回归模块,用于训练时计算输入训练语音样本时情感分类器输出的情感类别和情感标签的交叉熵损失;
10、层自适应隐式分布对齐模块,用于训练时基于对齐损失,将训练语音样本和测试语音样本在多层感知机各感知层的输出的分布进行自适应隐式对齐,对齐损失按照下式计算:
11、llida=llida(m)+llida(cc)+llida(fc)
12、
13、
14、
15、式中,llida表示对齐损失,llida(m)表示边缘分布隐式损失,和分别表示边缘分布训练特征矩阵和边缘分布测试特征矩阵,表示训练数据库中的第1,…,n个语音样本的语谱图输入时第一个感知层的输出,表示测试数据库中的第1,…,m个语音样本的语谱图输入时第一个感知层的输出,n,m分别表示训练数据库、测试数据库中语音样本数,wm表示第一重构系数矩阵,α是平衡系数,‖‖f表示f-范数,‖‖1表示l1范数,和分别表示属于第i个粗粒度情感类别的条件分布训练特征矩阵和条件分布测试特征矩阵,表示训练数据库中属于第i个粗粒度情感类别的的第1,…,ncc(i)个语音样本的语谱图输入时第二个感知层的输出,表示测试数据库中属于第i个粗粒度情感类别的第1,…,mcc(i)个语音样本的语谱图输入时第二个感知层的输出,ccc是粗粒度情感类别总数,代表第二重构系数矩阵,和分别表示属于第j个细粒度情感类别的条件分布训练特征矩阵和条件分布测试特征矩阵,表示训练数据库中属于第j个细粒度情感类别的第1,…,nfc(j)个语音样本的语谱图输入时第三个感知层的输出,表示测试数据库中属于第j个细粒度情感类别的第1,…,mfc(j)个语音样本的语谱图输入时第三个感知层的输出,c是细粒度情感类别总数,代表第三重构系数矩阵;
16、损失计算模块,用于训练时将交叉熵损失和对齐损失的加权和作为总损失;
17、(4)基于训练数据库和测试数据库的语音样本的语谱图,对所述层自适应隐式分布对齐神经网络lidan进行训练;
18、(5)对于待识别的语音样本,将其转换为语谱图后输入到层自适应隐式分布对齐神经网络lidan,得到预测的情感类别。
19、进一步的,步骤(2)具体包括:
20、(2-1)使用python语言的librosa扩展库对训练数据库和测试数据库的语音样本进行分帧、加窗;
21、(2-2)使用python语言的librosa扩展库对分帧、加窗后的语音样本进行短时离散傅里叶变换,得到语谱图。
22、进一步的,所述卷积神经网络包括若干依次连接的卷积基本块,每个卷积基本块包括依次连接的若干卷积层、激活函数和池化层。
23、进一步的,所述情感分类器具体为单层全连接层。
24、进一步的,所述深度回归模块具体用于执行如下计算:
25、
26、其中ldr表示交叉熵损失,j()表示交叉熵函数,表示训练数据库中的第n个语音样本的语谱图输入lidan时情感分类器输出的情感类别,表示训练数据库中的第n个语音样本的情感标签。
27、本发明所述的基于lidan的跨库语音情感识别装置包括:
28、数据库获取模块,用于获取训练数据库和测试数据库,其中训练数据库包括若干带有情感标签的训练语音样本,测试数据库包括若干不带有情感标签的测试语音样本;
29、语音处理模块,用于将训练数据库和测试数据库中的各语音样本分别转换为语谱图;
30、神经网络构建模块,用于构建层自适应隐式分布对齐神经网络lidan,包括:
31、卷积神经网络,用于从输入中提取语音特征;
32、多层感知机,包括三层依次连接的感知层,用于从语音特征中感知语音情感特征;
33、情感分类器,用于对多层感知机输出的语音情感特征进行分类得到情感类别;
34、深度回归模块,用于训练时计算输入训练语音样本时情感分类器输出的情感类别和情感标签的交叉熵损失;
35、层自适应隐式分布对齐模块,用于训练时基于对齐损失,将训练语音样本和测试语音样本在多层感知机各感知层的输出的分布进行自适应隐式对齐,对齐损失按照下式计算:
36、llida=llida(m)+llida(cc)+llida(fc)
37、
38、
39、
40、式中,llida表示对齐损失,llida(m)表示边缘分布隐式损失,和分别表示边缘分布训练特征矩阵和边缘分布测试特征矩阵,表示训练数据库中的第1,…,n个语音样本的语谱图输入时第一个感知层的输出,表示测试数据库中的第1,…,m个语音样本的语谱图输入时第一个感知层的输出,n,m分别表示训练数据库、测试数据库中语音样本数,wm表示第一重构系数矩阵,α是平衡系数,‖‖f表示f-范数,‖‖1表示l1范数,和分别表示属于第i个粗粒度情感类别的条件分布训练特征矩阵和条件分布测试特征矩阵,表示训练数据库中属于第i个粗粒度情感类别的的第1,…,ncc(i)个语音样本的语谱图输入时第二个感知层的输出,表示测试数据库中属于第i个粗粒度情感类别的第1,…,mcc(i)个语音样本的语谱图输入时第二个感知层的输出,ccc是粗粒度情感类别总数,代表第二重构系数矩阵,和分别表示属于第j个细粒度情感类别的条件分布训练特征矩阵和条件分布测试特征矩阵,表示训练数据库中属于第j个细粒度情感类别的第1,…,nfc(j)个语音样本的语谱图输入时第三个感知层的输出,表示测试数据库中属于第j个细粒度情感类别的第1,…,mfc(j)个语音样本的语谱图输入时第三个感知层的输出,c是细粒度情感类别总数,代表第三重构系数矩阵;
41、损失计算模块,用于训练时将交叉熵损失和对齐损失的加权和作为总损失;
42、网络训练模块,用于基于训练数据库和测试数据库的语音样本的语谱图,对所述层自适应隐式分布对齐神经网络lidan进行训练;
43、情感识别模块,用于对于待识别的语音样本,将其转换为语谱图后输入到层自适应隐式分布对齐神经网络lidan,得到预测的情感类别。
44、进一步的,所述语音处理模块具体包括:
45、第一处理单元,用于使用python语言的librosa扩展库对训练数据库和测试数据库的语音样本进行分帧、加窗;
46、第二处理单元,用于使用python语言的librosa扩展库对分帧、加窗后的语音样本进行短时离散傅里叶变换,得到语谱图。
47、进一步的,所述卷积神经网络包括若干依次连接的卷积基本块,每个卷积基本块包括依次连接的若干卷积层、激活函数和池化层。
48、进一步的,所述情感分类器具体为单层全连接层。
49、进一步的,所述深度回归模块具体用于执行如下计算:
50、
51、其中ldr表示交叉熵损失,j()表示交叉熵函数,表示训练数据库中的第n个语音样本的语谱图输入lidan时情感分类器输出的情感类别,表示训练数据库中的第n个语音样本的情感标签。
52、有益效果:本发明以隐式的方式减少训练数据和测试数据的特征分布差异,无需对训练数据和测试数据的进行预先假设以及相应统计矩的估计,节省了计算资源消耗,提高了模型运算效率;结合了深度神经网络层级化学习的性质,可以由浅入深地将不同粒度的特征分布与模型情感预测能力相结合;本发明识别准确率更高。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21006.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表