一种基于迁移学习的教师语音情感识别方法
- 国知局
- 2024-06-21 10:39:40
本发明属于教育信息化领域,涉及一种基于迁移学习的教师语音情感识别方法。
背景技术:
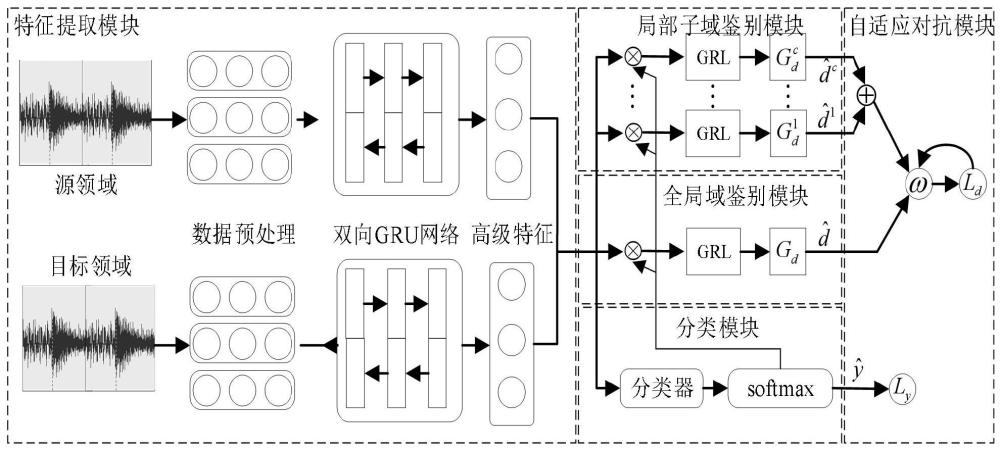
1、教师在课堂教学时的语音蕴含了其教学的情感,而教学情感对课堂教学质量和学生学习效果有直接影响。[pekrunr.the control-valuetheoryofachievementemotions:assumptions,corollaries,and implications for educational research andpractice[j].educational psychology review,2006,18:315-341.]提出的成就情绪控制价值理论可知,积极情绪可以增强学习动机,而消极情绪会损害学习,如焦虑会降低内在动机,导致学习者的学习兴趣逐渐降低。随着智慧教育课堂的逐步实施,海量的教育数据也随之产生,如学生教学评价文本、教师授课音视频等。利用这些教育数据可以深入地分析学生的学习情况和教师的工作情况。但是这些数据的质量参差不齐,大部分都是学校自发搜集的,并且都是未经标注和清洗的数据。未标注的数据虽然蕴含着丰富的情感,但是不能直接用于深度神经网络模型的训练。深度神经网络应用在语音情感识别领域可显著提高情感的识别率,而深度学习技术之所以有强大的性能,是因为它需要大量的已标记数据来训练深度学习模型。然而,获取足够的标记数据通常是昂贵和耗时的。因此,需要借助迁移学习解决教师语音情感识别领域中数据稀疏的问题,利用现有其他领域中丰富的标记样本来促进待教师语音情感识别领域的学习。因此,利用现有领域中丰富的标记样本来促进待学习领域的学习可以解决目标领域中数据稀疏的问题,迁移学习由此产生。
2、在机器学习领域,迁移学习是一种利用已有知识来改善新任务学习性能的技术。传统的机器学习算法通常假设训练集和测试集的数据是从同一个分布中采样得到的,但在现实场景中,这个假设往往不成立。特别是在目标领域没有足够的标注数据的情况下,传统算法的性能会显著下降。基于特征的迁移学习目标是减少源域和目标域之间的特征分布差异,进而使用传统的机器学习技术进行分类。文献[siddique l,rajib r,shahzady,etal.transfer learning for improving speech emotion classification accuracy[c].interspeech.india,2018:257-261.]提出了一种基于迁移学习的方法,用于提高语音情感分类的准确性。该方法利用说话者的语音和表情之间的关系,将表情的标注从视觉域转移到语音域,从而解决了音频数据无标签的问题,在情感识别任务中,该方法能够显著提高模型的分类准确度,并且在不同情感类别上都有很好的表现。文献[廖祥文,吴晓静,桂林,等.结合表示学习和迁移学习的跨领域情感分类[j].北京大学学报(自然科学版),2019,55(01):37-46.]提出一种融合文本特征的迁移学习算法,利用分层注意力网络对情感信息进行建模,随后采用类噪声估计算法挑选高质量样本扩充目标域的数据集。基于模型的迁移学习主要应用于深度学习模型中,其目的是为了使两个域的模型可以实现参数共享。文献[tzeng e,hoffman j,zhang n,et al.deep domain confusion:maximizing fordomain invariance[j].speech communication,2014,126:11-24.]提出一种引入适应层和额外的域混淆器的模型(deep domain confusion,ddc),该模型通过引入适应层和域混淆器来实现域不变性学习,从而在跨域场景中学习高质量的语义表示,该方法可以显著提高模型的准确率,并且在各种跨领域学习任务上都有很好的表现。文献[long m,zhu h,wang j,et al.unsupervised domain adaptation with residual transfer networks[j].advances in neural information processing systems,2016:136-144.]提出的自适应分类器(residual transfer network,rtn)可以实现源域和目标域数据中的联合学习,然后通过残差网络来实现分类器的自适应,在实验中与其他模型对比有着极大的优势。与其他模型相比,实验结果显示rtn具有显著优势。通过将源域和目标域数据的特征进行变换和融合,rtn可以有效地减小源域和目标域之间的分布差异,提高模型在目标域上的性能。该方法在无监督域适应任务上取得了良好的效果,并在多个数据集上都进行了验证。
3、迁移学习模型能否成功的关键在于学习一个判别模型来减少两个域之间的分布差异。传统的方法,例如:文献[chen y,wang j,hhuang m,et al.cross-positionactivity recognition with stratified transfer learning[j].pervasive andmobile computing,2019,57:1-13.]提出的一种称为分层迁移学习(stratified transferlearning,stl)的新方法来重新加权源域中的样本,用于解决在跨位置活动识别中可能会遇到的问题,从而提高跨位置活动识别的精度;文献[wang j,feng w,chen y,etal.visual domain adaptation with manifold embedded distribution alignment[c].proceedings ofthe 26th acm international conference on multimedia.korea,2018:402-410.]通过学习一个嵌入式映射函数,将源域样本和目标域样本映射到一个共享特征空间。这个映射函数是通过最小化源域和目标域之间的分布差异来学习的。其次,通过对齐源域和目标域的嵌入分布来进一步减小它们之间的差异。随着深度学习的快速发展,文献[tzeng e,hoffman j,saenko k,et al.adversarial discriminative domainadaptation[c].proceedings ofthe ieee conference on computer vision andpattern recognition.usa,2017:7167-7176.]将对抗学习可通过嵌入深度网络中,减少源域和目标域之间的分布差异。该方法包括两个关键组件:鉴别器和生成器。生成器的目标是通过将源域数据映射到目标域数据的分布上,来生成具有目标域特征的伪样本。鉴别器的目标是区分真实的目标域样本和生成的伪样本。这两个组件通过对抗训练进行优化,即生成器试图欺骗鉴别器,而鉴别器努力辨别真假样本。通过不断迭代训练,生成器能够生成更具目标域分布特征的样本,从而减小源域和目标域之间的差异。大多数迁移学习模型是通过学习单个域鉴别器来对齐源域的目标分布,或者关注多个鉴别器来对齐子域的目标分布,而在实际的应用中,域之间的全局分布和局部分布通常有着不同的贡献。为了解决高质量的教师语音数据集的缺失的问题,我们引入迁移学习,为了更好地使用迁移学习模型跨领域地对教师的语音情感进行识别,如何自适应地评估源域和目标域全局分布与局部分布的相对重要性,是亟待解决的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于迁移学习的教师语音情感识别方法,利用迁移学习技术对没有标签的教师语音数据进行情感识别,自适应对抗部分动态地评估全局分布和局部分布的相对重要性,自动分配全局分布和局部分布的权重,最终获取源域和目标域的共同特征,完成教师课堂教学的跨领域语音情感识别。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于迁移学习的教师语音情感识别方法,该方法包括以下步骤:
4、s1:数据预处理:利用录音设备获取所需的研究数据,同时对采集的数据进行预处理,预处理后的数据为目标域数据,选择合适有标签的语音情感识别数据集作为源域数据;
5、s2:特征提取阶段:利用双向gru进行训练,获取源域和目标域数据集中语音特征的前后记忆信息的高级情感特征;
6、s3:局部子域鉴别阶段:利用对抗学习的思想,通过域鉴别和特征提取的相互对抗训练,对齐源域和目标域之间的局部分布;
7、s4:全局域鉴别器阶段:利用对抗学习的思想,通过域鉴别和特征提取的相互对抗训练,对齐源域和目标域之间的全局分布;
8、s5:分类阶段:利用源域数据的监督信息对目标域数据进行训练,构造情感分类器,挖掘和识别语音中的情感特征;
9、s6:自适应对抗阶段:自适应地计算全局分布和局部分布的相对重要性,并自动地配置权重ω。
10、可选的,所述s1中,情感识别任务采集教师课堂教学下的语音数据作为研究对象,对采集的数据进行抽样量化、分帧、加窗和端点检测的数据预处理,以便模型训练和使用;教师的语音数据作为目标域数据,收集到的相关的已经完善的有标签的语音情感识别数据集作为源域数据。
11、可选的,所述s2中,使用双向gru模型提取语音序列的前后依赖关系,并通过gru模型获取源域和目标域中语音数据的高级特征;前向gru计算公式如下:
12、
13、其中,es表示输入的语音特征;为前向gru的隐藏状态;
14、后向gru的输出隐藏状态为
15、
16、其中,为后向gru的隐藏状态;
17、将前向与后向的隐藏记忆信息进行拼接,得到双向gru的整体隐藏状态h,即为语音的高级特征,h的计算公式:
18、
19、可选的,所述s3中,自适应对抗学习包含两个部分:特征提取部分gf、域鉴别部分gd;gy为标签分类部分,θf,θd,θy分别表示gf,gd,gy的参数自适应对抗学习的损失函数可形式化为公式:
20、
21、其中,λ表示权重参数;ly和ld分别表示标签分类部分和域鉴别部分的损失函数;
22、局部子域鉴别部分能够被分成c类子域鉴别器每一类子域鉴别器负责匹配与各自相关的源域和目标域数据;局部子域鉴别部分的损失函数:
23、
24、其中,代表c类子域鉴别器;代表c类子域鉴别器的交叉熵损失;gf为特征提取部分提取的高级特征;代表输入样本xi在c类子域鉴别器的预测概率分布;di代表输入样本xi的域标签。
25、可选的,所述s4中,全局域鉴别部分的作用就是对齐源域和目标域之间的全局分布;全局域鉴别部分和局部子域鉴别部分共同作用,目的就是学习和识别源域和目标域之间的域不变特征;计算全局域鉴别部分的损失函数:
26、
27、其中,ld表示域鉴别器交叉熵损失函数;gf表示特征提取部分中的高级特征;di代表样本xi的域标签。
28、可选的,所述s5中,利用源域数据的监督信息对其进行训练,使用softmax函数作为情感分类器,挖掘和识别语音中的情感特征,其只关注语音中蕴含的情感信息,而对输入语音来自哪个领域不予考虑,利用源域中带有情感标签的样本数据对其进行训练,最后输出目标域中无标签样本所蕴含的情感;标签分类部分的训练目标是交叉熵损失:
29、
30、其中,c表示分类的个数;表示输入样本xi属于类别c的概率;gy为标签分类部分;gf为特征提取部分提取的高级特征。
31、可选的,所述s6中,提出自适应对抗因子ω,自适应对抗部分能够自动更新网络内自适应对抗因子ω的值;将全局域鉴别部分的全局a-distance:
32、da,g(ds,dt)=2(1-2(lg))
33、而局部子域鉴别部分的局部a-distance:
34、
35、最终,自适应对抗因子ω:
36、
37、其中,和代表来自c类子域的样本;lg代表全局鉴别器的损失;代表c类局部子域鉴别器的损失;
38、综合各组成部分,其最终学习目标:
39、
40、其中,λ表示权衡参数;ly表示标签分类部分的损失函数;lg,ll分别表示全局域鉴别器和局部子域鉴别器的损失函数;ω表示自适应对抗因子。
41、本发明的有益效果在于:
42、(1)本发明一种基于迁移学习的教师语音情感方法可以对不含情感标签的教师语音数据进行情感识别,解决了相关领域数据集缺少的问题,为教师的自我认知和教学方式改进提供科学支持。
43、(2)本发明使用自适应对抗部分动态地评估全局分布和局部分布的相对重要性,并自动分配权重。这样可以在不同的领域中有效地学习到共同的特征,帮助提高跨领域语音情感识别的准确性。
44、(3)本发明使用全局域鉴别部分和局部子域鉴别部分,分别计算全局分布和局部分布之间的差异。这样可以更充分地利用跨领域数据的信息,提高模型的鲁棒性和泛化能力。
45、(4)本发明使用双向gru网络提取源域和目标域数据中蕴含的高级特征。gru模型能够捕捉语音序列的前后依赖关系,从而更好地表达语音中的情感信息。
46、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21027.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表