一种智慧语音LED/LCD时钟及语音处理方法与流程
- 国知局
- 2024-06-21 10:40:48
本发明涉及智慧时钟,特别涉及一种智慧语音led/lcd时钟及语音处理方法。
背景技术:
1、随着计算机与人工智能、互联网云服务的普及,人工智能应用在工作和生活的多个领域。闹铃多种选择可选为起床闹铃、起床报时、报时加天气信息播报。还可以语音触发各项功能,从而避免手动调节带来的不便,例如,通过语音进行时间查询,通过语音进行时间校正。但是,在进行语音交互过程中,由于受到噪声的干扰影响,时钟中的语音处理单元无法正确区分语音指令与噪声,而不能及时进行响应,反而降低了用户体验。
技术实现思路
1、现有的智能语音时钟,由于受到背景声音的干扰影响,时钟中的语音处理单元无法正确区分语音指令与噪声,无法及时进行功能响应,降低了用户体验。
2、针对上述问题,提出一种智慧语音led/lcd时钟及语音处理方法,以解决上述问题。
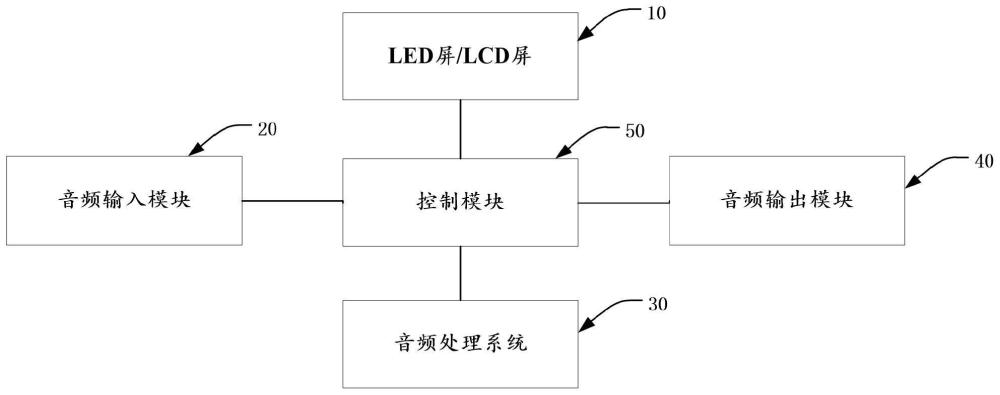
3、第一方面,一种智慧语音led/lcd时钟,通过语音与用户进行交互,包括:led屏/lcd屏、音频输入模块、音频处理系统、音频输出模块及控制模块;所述led屏/lcd屏、所述音频输入模块、所述音频处理系统、所述音频输出模块分别与所述控制模块电连接;所述led屏/lcd屏用于显示时钟信息;所述音频输入模块用于拾取用户语音指令;所述音频处理系统用于对拾取的音频信号进行处理;所述音频输出模块根据控制指令输出交互语音;其中,所述音频处理系统包括训练模块及判决模块;
4、所述训练模块包括音频分离单元、梯度单元及训练单元;
5、所述音频分离单元用于:
6、利用两步法进行语音分离:第一步、从拾取的声音信号中提取方差特征及匹配度特征;第二步、若所述声音信号的基准参量小于规定阈值,且方差特征值小于规定阈值或匹配度特征值小于规定阈值,则当前帧为噪声帧,若所述声音信号的基准参量大于规定阈值,且所述方差特征值和所述匹配度特征值分别小于其规定阈值,则当前帧为噪声帧,获取噪声段及语音段;
7、所述梯度单元用于:
8、将所述噪声段分别与各指令语音样本进行叠加,对叠加后获取的训练信号集提取谱分布特征,并对所述谱分布特征进行阶梯量化,获取第一梯度特征、第二梯度特征、第三梯度特征及梯度特征集;
9、所述训练单元用于:
10、利用所述梯度特征集对所述第一梯度特征、第二梯度特征及第三梯度对应的第一子判决器、第二子判决器、第三子判决器进行训练;
11、所述判决单元用于:
12、利用训练完成的所述第一子判决器、第二子判决器、第三子判决器对拾取的声音信号进行投票判决;
13、其中,所述基准参量为该帧的对数能量与谱熵的比值,所述第一梯度特征的能量强度大于第二梯度特征的能量强度,所述第二梯度特征的能量强度大于第三梯度特征的能量强度,所述梯度特征集包括第一梯度特征子集、第二梯度特征子集及第三梯度特征子集。
14、结合本发明第一方面所述所述的智慧语音led/lcd时钟,第一种可能的实施方式中,所述音频分离单元包括:
15、第一特征提取单元;
16、所述第一特征提取单元用于将输入的声音信号进行傅里叶变换,获取声音信号序列,对所述声音信号序列进行分帧加窗后进行均匀划分并获取划分后的谱分布的能量方差,获取方差特征。
17、结合本发明第一方面第一种可能的实施方式,第二种可能的实施方式中,所述梯度单元包括:
18、分类单元;
19、叠加单元;
20、所述分类单元用于对各指令的语音训练样本的信噪比进行估计,并将所述语音训练样本按照信噪比进行分类;
21、所述叠加单元用于根据信噪比将噪声段与各指令语音样本进行叠加,获取训练信号集。
22、结合本发明第一方面第二种可能的实施方式,第三种可能的实施方式中,所述梯度单元还包括:
23、第二特征提取单元;
24、所述第二特征提取单元用于分别提取所述训练信号集中的谱分布特征。
25、第二方面,一种语音处理方法,用于对第一方面所述的智慧语音led/lcd时钟拾取的用户语音进行处理,包括:
26、步骤100、训练阶段;
27、所述步骤100包括:
28、步骤110、利用两步法进行语音分离:第一步、从拾取的声音信号中提取方差特征及匹配度特征;第二步、若所述声音信号的基准参量小于规定阈值,且方差特征值小于规定阈值或匹配度特征值小于规定阈值,则当前帧为噪声帧,若所述声音信号的基准参量大于规定阈值,且所述方差特征值和所述匹配度特征值分别小于其规定阈值,则当前帧为噪声帧,获取噪声段及语音段;
29、步骤120、将所述噪声段分别与各指令语音样本进行叠加,对叠加后获取的训练信号集提取谱分布特征,并对所述谱分布特征进行阶梯量化,获取第一梯度特征、第二梯度特征及第三梯度特征;
30、步骤130、利用所述第一梯度特征、第二梯度特征及第三梯度特征获取所述训练信号集的梯度特征集,并利用所述梯度特征集对所述第一梯度特征、第二梯度特征及第三梯度对应的第一子判决器、第二子判决器、第三子判决器进行训练;
31、步骤200、判决分类阶段;
32、利用训练完成的所述第一子判决器、第二子判决器、第三子判决器对拾取的声音信号进行投票判决;
33、其中,所述第一梯度特征的能量强度大于第二梯度特征的能量强度,所述第二梯度特征的能量强度大于第三梯度特征的能量强度,所述梯度特征集包括第一梯度特征子集、第二梯度特征子集及第三梯度特征子集。
34、结合本发明第二方面所述的语音处理方法,第一种可能的实施方式中,所述步骤110包括:
35、步骤111、将输入的声音信号进行傅里叶变换,获取声音信号序列;
36、步骤112、对所述声音信号序列进行分帧加窗后进行均匀划分;
37、步骤113、计算均匀划分后的所述声音信号序列的能量方差,获取方差特征。
38、结合本发明第二方面第一种可能的实施方式中,第二种可能的实施方式中,所述步骤110还包括:
39、步骤114、获取所述声音信号的噪声帧;
40、步骤115、若所述噪声帧的帧数大于规定阈值,则确定为噪声段。
41、结合本发明第二方面第一种可能的实施方式,第三种可能的实施方式中,所述步骤120包括:
42、步骤121、对各指令的语音训练样本的信噪比进行估计,并将所述语音训练样本按照信噪比进行分类;
43、步骤122、根据信噪比将噪声段与各指令的语音训练样本进行叠加,获取训练信号集。
44、结合本发明第二方面第三种可能的实施方式,第四种可能的实施方式中,所述步骤120还包括:
45、步骤123、提取所述训练信号集中的谱分布特征;
46、步骤124、利用所述谱分布特征中的梯度特征集对判决器进行训练。
47、实施本发明所述的一种智慧语音led/lcd时钟及语音处理方法,通过利用方差特征、匹配度特征以及噪声帧数阈值对拾取的用户声音进行分离,提高了分离精度;通过进行梯度量化并采用多个子判决器对不同的梯度特征进行判决识别,提高在低信噪比下对语音指令内容的识别精度,提高了智慧语音led/lcd时钟的用户体验。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21150.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表