语音数据、会议语音的处理方法及服务器与流程
- 国知局
- 2024-06-21 10:40:52
本申请涉及计算机技术,尤其涉及一种语音数据、会议语音的处理方法及服务器。
背景技术:
1、在语音处理领域,越来越多场景(如语音翻译、音视频会议、直播、短视频、智能电话客服质检与外呼等)迫切需要强大语音处理(如语音识别、语音分类等)能力的支持。传统语音处理(如语音识别、语音分类等)模型,需要依赖标注大量不同场景不同语言的语音数据的训练,才可以在通用或某些特定领域上取得较好的准确率。模型效果强依赖于语音数据及其对应标注数据(如文本、类别)的标注量,为提高模型的准确率,需要标注大量数据但是训练数据的标注成本高、标注质量差,高质量的标注数据难以获取,导致语音处理模型容易出现因训练数据缺乏、应用场景数据不匹配而导致的性能下降问题。
2、基于大量无监督数据预训练的大型预训练语音模型已成为语音处理领域的主导力量,通过使用下游任务的较小规模的标注训练数据进行微调训练,来获得在特定下游任务尚准确率较高的语音处理模型。但是,在有噪声的语音条件下,噪声的存在破坏了语音内容,引入了不必要的失真,放大了微调方法的过平滑问题,导致在各类噪声的语音条件下语音处理模型的鲁棒性低、语音处理准确性较低。
技术实现思路
1、本申请提供一种语音数据、会议语音的处理方法及服务器,用以解决在各类噪声的语音条件下语音处理模型的鲁棒性低、语音处理的准确性较低的问题。
2、第一方面,本申请提供一种语音数据的处理方法,包括:
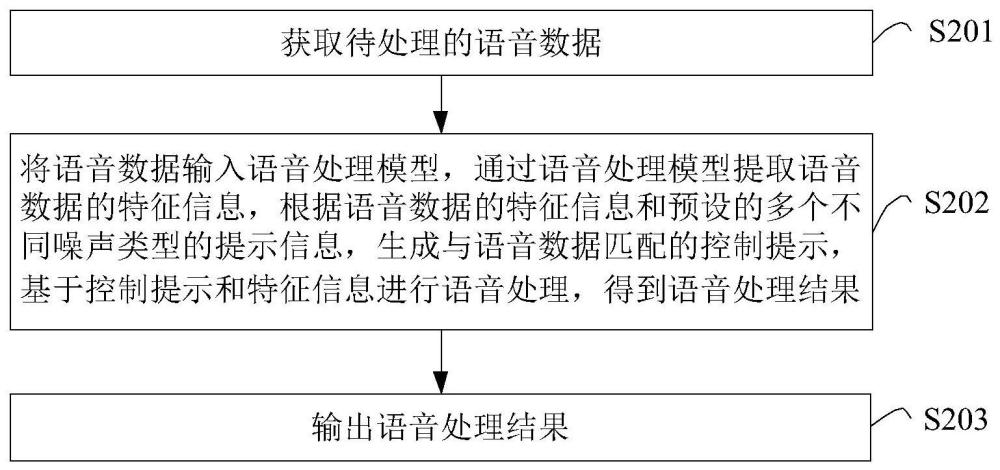
3、获取待处理的语音数据;将所述语音数据输入语音处理模型,通过所述语音处理模型提取所述语音数据的特征信息,根据所述语音数据的特征信息和预设的多个不同噪声类型的提示信息,生成与所述语音数据匹配的控制提示,基于所述控制提示和所述特征信息进行语音处理,得到语音处理结果;输出所述语音处理结果。
4、第二方面,本申请提供一种会议语音的处理方法,包括:
5、接收端侧设备发送的会议语音;将所述会议语音输入语音识别模型,通过所述语音识别模型提取所述会议语音的特征信息,根据所述会议语音的特征信息和预设的多个不同噪声类型的提示信息,生成与所述会议语音匹配的控制提示,基于所述控制提示和所述会议语音的特征信息进行语音识别,得到所述会议语音的内容文本;向所述端侧设备输出所述会议语音的内容文本。
6、第三方面,本申请提供一种服务器,包括:
7、至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述服务器执行前述任一方面所述的方法。
8、本申请提供的语音数据、会议语音的处理方法及服务器,通过获取待处理的语音数据,将语音数据输入语音处理模型,通过语音处理模型提取语音数据的特征信息,根据语音数据的特征信息和预设的多个不同噪声类型的提示信息,生成与语音数据匹配的控制提示,基于控制提示和特征信息进行语音处理,得到语音处理结果,并输出语音处理结果,能够根据输入语音的特征信息和多个不同噪声类型的提示信息,自适应地生成与输入语音数据匹配的控制提示,相较于现有技术中使用固定的噪声提示信息,本申请的方案提升了语音处理模型的抗噪声能力,提升了语音处理模型在各类噪声条件下的鲁棒性,从而提升了在各类噪声条件下语音处理的准确性。
技术特征:1.一种语音数据的处理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述语音处理模型包括:特征提取网络、编码器和解码器,所述编码器包括依次堆叠的多个编码层,所述编码层包含依次堆叠的多个处理模块,至少一个所述编码层包括与同一所述编码层中指定处理模块对应的噪声感知提示控制模块;
3.根据权利要求2所述的方法,其特征在于,所述编码层至少包括如下处理模块:注意力模块和前馈网络,所述前馈网络包含前后依次连接的第一前馈层和第二前馈层;
4.根据权利要求2所述的方法,其特征在于,所述噪声感知提示控制模块包括:第一线性变换单元、第一控制单元、第二线性变换单元和第二控制单元,
5.根据权利要求2所述的方法,其特征在于,所述将所述语音数据输入语音处理模型,通过所述语音处理模型提取所述语音数据的特征信息,根据所述语音数据的特征信息和预设的多个不同噪声类型的提示信息,生成与所述语音数据匹配的控制提示,基于所述控制提示和所述特征信息进行语音处理,得到语音处理结果,包括:
6.根据权利要求2所述的方法,其特征在于,所述根据输入对应指定处理模块的特征信息对输入对应指定处理模块的多个提示信息进行加权控制,生成与输入的特征信息匹配的控制提示,包括:
7.根据权利要求6所述的方法,其特征在于,所述基于所述第二门控系数对所述第一中间提示进行加权计算,生成第一控制提示,包括:
8.根据权利要求2所述的方法,其特征在于,所述语音处理模型通过如下方式获得:
9.根据权利要求8所述的方法,其特征在于,所述预训练语音模型包括特征提取网络、编码器和解码器,
10.根据权利要求9所述的方法,其特征在于,所述使用训练集对所述语音处理模型进行训练,更新所述噪声感知提示控制模块的参数和所述多个不同噪声类型的提示信息,得到训练好的语音处理模型和多个不同噪声类型的提示信息,包括:
11.根据权利要求8-10中任一项所述的方法,其特征在于,所述使用训练集对所述语音处理模型进行训练之前,还包括:
12.根据权利要求1-10中任一项所述的方法,其特征在于,所述获取待处理的语音数据,包括:
13.一种会议语音的处理方法,其特征在于,包括:
14.一种服务器,其特征在于,包括:
技术总结本申请提供一种语音数据、会议语音的处理方法及服务器。本申请的方法,在语音处理模型的至少一个编码层中增加了噪声感知提示控制模块NPG,通过将待处理的语音数据输入语音处理模型,通过所述语音处理模型提取所述语音数据的特征信息,通过NPG根据所述语音数据的特征信息和多个不同噪声类型的预设提示信息,自适应地生成与所述语音数据匹配的控制提示,并基于所述控制提示和特征信息实现语音处理,得到语音处理结果,并返回所述语音处理结果,提升了语音处理模型的抗噪能力,从而提升语音处理模型在各类噪声条件下的鲁棒性和准确性。技术研发人员:黄殿文,张冲,马煜坤,阮忠孝,张芮熙,倪崇嘉,赵胜奎,叶家祺,王昊,梁祥智,庄永祥,马斌受保护的技术使用者:杭州阿里云飞天信息技术有限公司技术研发日:技术公布日:2024/1/22本文地址:https://www.jishuxx.com/zhuanli/20240618/21159.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。