语音识别方法、装置及车辆与流程
- 国知局
- 2024-06-21 11:27:32
本申请涉及语音识别,尤其涉及一种语音识别方法、装置及车辆。
背景技术:
1、在语音识别技术中,语音识别系统会根据用户的语音停顿来判断一句语音是否结束,继而针对一句完整的语音进行语音识别,以获得准确的语音识别文本。
2、在实际的语音识别场景中,可能存在用户表达不畅,导致一句完整的语音中间存在长时间停顿的情形,使得语音识别系统将一个长的整句语音截断成两段短的分句语音并分别进行识别。其中,前一段分句的语音识别文本先行正常输出显示;而后一段分句的语音识别文本会另外独立显示,甚至因缺少完整的上下文语义而输出不准确的识别结果。最终,基于前、后两段分句均为不完整的语音识别文本,会使得用户的真实语音指令无法正确响应,影响人机交互体验。
技术实现思路
1、为解决或部分解决相关技术中存在的问题,本申请提供一种语音识别方法、装置及车辆,能够确保语音识别结果的准确性,以及缩短句中静音时长,提高语音识别效率,改善用户体验。
2、本申请第一方面提供一种语音识别方法,其包括:
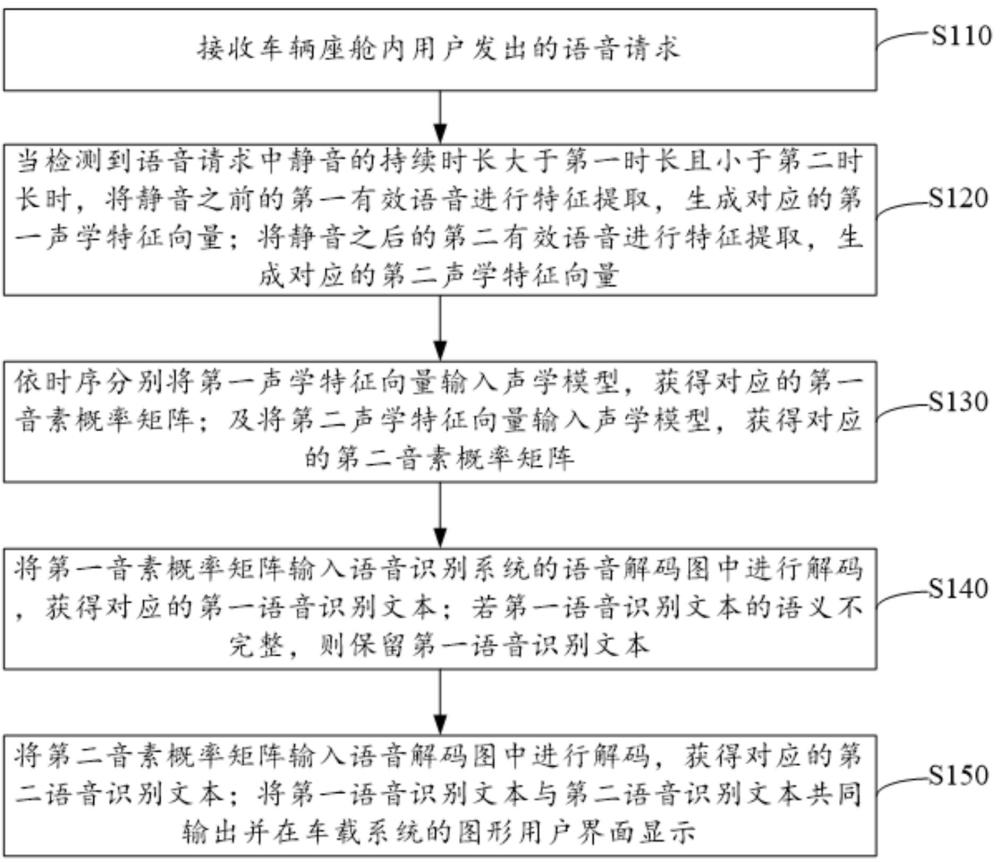
3、接收车辆座舱内用户发出的语音请求;当检测到所述语音请求中静音的持续时长大于第一时长且小于第二时长时,将所述静音之前的第一有效语音进行特征提取,生成对应的第一声学特征向量;将所述静音之后的第二有效语音进行特征提取,生成对应的第二声学特征向量;依时序分别将所述第一声学特征向量输入声学模型,获得对应的第一音素概率矩阵;及将所述第二声学特征向量输入所述声学模型,获得对应的第二音素概率矩阵;将所述第一音素概率矩阵输入语音识别系统的语音解码图中进行解码,获得对应的第一语音识别文本;若所述第一语音识别文本的语义不完整,则保留所述第一语音识别文本;将所述第二音素概率矩阵输入所述语音解码图中进行解码,获得对应的第二语音识别文本;将所述第一语音识别文本与第二语音识别文本共同输出并在车载系统的图形用户界面显示。
4、一些实施方式中,在将所述第一声学特征向量输入声学模型,获得对应的第一音素概率矩阵之后,还包括:跳过具有所述持续时长的静音。
5、一些实施方式中,在将所述第二声学特征向量输入所述声学模型之前,还包括:向所述声学模型加载具有预设时长的预设静音状态,其中,所述预设时长小于所述第一时长。
6、一些实施方式中,所述方法还包括:若所述第一语音识别文本的语义完整,则清空所述语音解码图中对应的解码状态,并将所述第一语音识别文本输出并在车载系统的图形用户界面显示;及另将所述第二语音识别文本单独输出并在车载系统的图形用户界面显。
7、一些实施方式中,所述方法还包括:当检测到所述语音请求中静音的持续时长不大于第一时长,则将所述静音之前的第一有效语音和所述静音之后的第二有效语音视为一句语音请求进行语音识别;或
8、当检测到所述语音请求中静音的持续时长不小于第二时长,则将所述静音之前的第一有效语音和所述静音之后的第二有效语音视为两句语音请求分别进行语音识别。
9、一些实施方式中,所述获得对应的第一语音识别文本之后,还包括:
10、获取所述第一语音识别文本的语义完整的置信度;当所述第一语音识别文本对应的置信度小于预设阈值时,则确定所述第一语音识别文本的语义不完整。
11、一些实施方式中,所述若所述第一语音识别文本的语义不完整,则保留所述第一语音识别文本,包括:若所述第一语音识别文本的语义不完整,则在所述语音解码图中保留状态得分最高的第一语音识别文本作为待拼接文本,并删除所述语音解码图中剩余的候选语音识别文本。
12、本申请第二方面提供一种语音识别装置,其包括:
13、语音接收模块,用于接收车辆座舱内用户发出的语音请求;
14、特征提取模块,用于当检测到所述语音请求中静音的持续时长大于第一时长且小于第二时长时,将所述静音之前的第一有效语音进行特征提取,生成对应的第一声学特征向量;将所述静音之后的第二有效语音进行特征提取,生成对应的第二声学特征向量;
15、声学处理模块,用于依时序分别将所述第一声学特征向量输入声学模型,获得对应的第一音素概率矩阵;及将所述第二声学特征向量输入所述声学模型,获得对应的第二音素概率矩阵;
16、语音识别模块,用于将所述第一音素概率矩阵输入语音识别系统的语音解码图中进行解码,获得对应的第一语音识别文本;若所述第一语音识别文本的语义不完整,则保留所述第一语音识别文本;将所述第二音素概率矩阵输入所述语音解码图中进行解码,获得对应的第二语音识别文本;将所述第一语音识别文本与第二语音识别文本共同输出并在车载系统的图形用户界面显示。
17、本申请第三方面提供一种车辆,包括:
18、处理器;以及
19、存储器,其上存储有可执行代码,当所述可执行代码被所述处理器执行时,使所述处理器执行如上所述的方法。
20、本申请第四方面提供一种计算机可读存储介质,其上存储有可执行代码,当所述可执行代码被车辆的处理器执行时,使所述处理器执行如上所述的方法。
21、本申请提供的技术方案可以包括以下有益效果:
22、本申请的语音识别方法,在声学模型的处理阶段,通过对静音前、后的两段语音进行截断,且跳过具有持续时长的静音,大大提高了声学模型的处理效率,缩短了整句语音请求的处理时长,使后续语音识别文本可以加速输出显示,且额外在第二有效语音的句首增加预先已经处理好的预设时长静音,确保了第二有效语音的识别准确率,且无需声学模型对加载的预设静音进行识别,确保识别效率;另外,在语音解码图中,根据第一语音识别文本的语义完整性采取不同的输出和显示方案,使得语义不完整的第一语音识别文本可以等待第二语音识别文本的拼接,而语义完整的第一语音识别文本可以与第二语音识别文本各自分开输出显示,获得准确的语音识别结果,确保人机交互的可靠性。
23、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
技术特征:1.一种语音识别方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,在将所述第一声学特征向量输入声学模型,获得对应的第一音素概率矩阵之后,还包括:
3.根据权利要求2所述的方法,其特征在于,在将所述第二声学特征向量输入所述声学模型之前,还包括:
4.根据权利要求1所述的方法,其特征在于,所述方法还包括:
5.根据权利要求1所述的方法,其特征在于,所述方法还包括:
6.根据权利要求1所述的方法,其特征在于,所述获得对应的第一语音识别文本之后,还包括:
7.根据权利要求1所述的方法,其特征在于,所述若所述第一语音识别文本的语义不完整,则保留所述第一语音识别文本,包括:
8.一种语音识别装置,其特征在于,包括:
9.一种车辆,其特征在于,包括:
10.一种计算机可读存储介质,其上存储有可执行代码,当所述可执行代码被车辆的处理器执行时,使所述处理器执行如权利要求1-7中任一项所述的方法。
技术总结本申请涉及一种语音识别方法、装置及车辆。该方法包括:接收车辆座舱内用户发出的语音请求;当检测到语音请求中静音的持续时长大于第一时长且小于第二时长时,将第一音素概率矩阵输入语音识别系统的语音解码图中进行解码,获得对应的第一语音识别文本;若第一语音识别文本的语义不完整,则保留第一语音识别文本;将第二音素概率矩阵输入语音解码图中进行解码,获得对应的第二语音识别文本;将第一语音识别文本与第二语音识别文本共同输出并在车载系统的图形用户界面显示。本申请提供的方案,能够确保语音识别结果的准确性,以及缩短句中静音时长,提高语音识别效率,改善用户体验。技术研发人员:张辽受保护的技术使用者:广州小鹏汽车科技有限公司技术研发日:技术公布日:2024/2/8本文地址:https://www.jishuxx.com/zhuanli/20240618/21646.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表