一种终端到云端的语音识别测试方法及装置与流程
- 国知局
- 2024-06-21 11:27:25
本发明属于语音识别,具体涉及一种终端到云端的语音识别测试方法及装置。
背景技术:
1、目前,由于语音识别整个链路从开始录音到ssp降噪处理,再到上传识别音频到云端进行识别,每个过程中都存在多线程,因此会存在音频数据不一致,即异步处理不当导致丢音频问题。
2、现阶段,语音识别测试只能靠人工或者通过工具播放音频,然后对比播放音频实际对应的结果和识别结果对比,进而统计语音识别效果。该方式不仅费时费力,测试不全面,而且仅仅只能统计最终识别结果,而无法知道整个链路中哪块存在问题,比方原始录音问题、降噪问题、终端读取录音问题还是网络传输问题等。如何实现自动化的流程协助排查和定位,以提升内部研发效率具有现实的应用意义。
技术实现思路
1、为此,本发明提供一种终端到云端的语音识别测试方法及装置,解决传统技术测试不全面,只能统计最终识别结果,无法对整个链路中存在缺陷进行分析的问题。
2、为了实现上述目的,本发明提供如下技术方案:一种终端到云端的语音识别测试方法,包括:
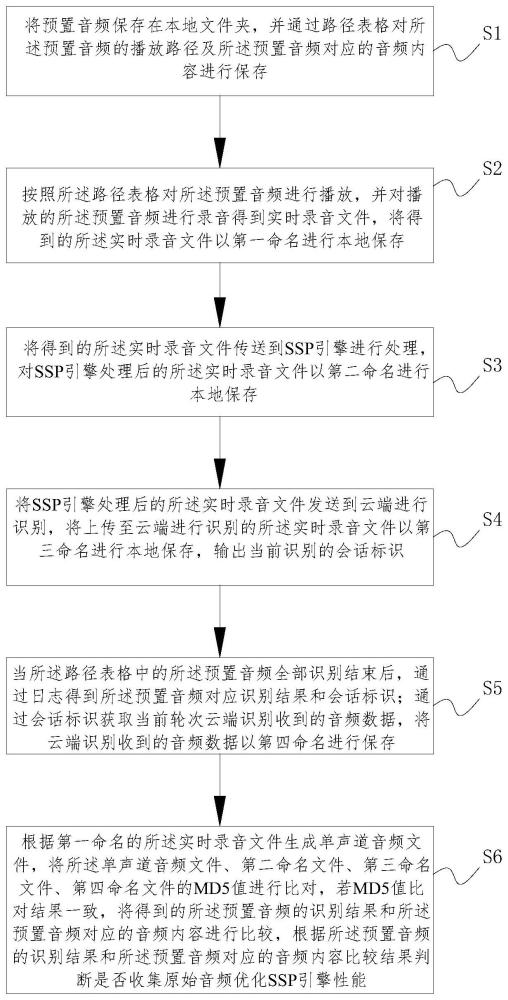
3、将预置音频保存在本地文件夹,并通过路径表格对所述预置音频的播放路径及所述预置音频对应的音频内容进行保存;
4、按照所述路径表格对所述预置音频进行播放,并对播放的所述预置音频进行录音得到实时录音文件,将得到的所述实时录音文件以第一命名进行本地保存;
5、将得到的所述实时录音文件传送到ssp引擎进行处理,对ssp引擎处理后的所述实时录音文件以第二命名进行本地保存;
6、将ssp引擎处理后的所述实时录音文件发送到云端进行识别,将上传至云端进行识别的所述实时录音文件以第三命名进行本地保存,输出当前识别的会话标识;
7、当所述路径表格中的所述预置音频全部识别结束后,通过日志得到所述预置音频对应识别结果和会话标识;通过会话标识获取当前轮次云端识别收到的音频数据,将云端识别收到的音频数据以第四命名进行保存;
8、根据第一命名的所述实时录音文件生成单声道音频文件,将所述单声道音频文件、第二命名文件、第三命名文件、第四命名文件的md5值进行比对,若md5值比对结果一致,将得到的所述预置音频的识别结果和所述预置音频对应的音频内容进行比较,根据所述预置音频的识别结果和所述预置音频对应的音频内容比较结果判断是否收集原始音频优化ssp引擎性能。
9、作为终端到云端的语音识别测试方法优选方案,按照所述路径表格对所述预置音频利用电脑和保真音响进行播放,并通过usb线连接包含语音识别应用的移动设备实时获取设备输出日志。
10、作为终端到云端的语音识别测试方法优选方案,利用第一命名的所述实时录音文件调用裸引擎脚本生成所述单声道音频文件。
11、作为终端到云端的语音识别测试方法优选方案,将所述单声道音频文件、第二命名文件、第三命名文件、第四命名文件的md5值进行比对过程中,若md5值比对结果不一致,提取md5值不一致的命名文件,对md5值不一致的命名文件对应的处理流程进行重新处理。
12、作为终端到云端的语音识别测试方法优选方案,若所述预置音频的识别结果和所述预置音频对应的音频内容比较结果一致,判定所述预置音频及ssp引擎处理数据符合预设要求;若所述预置音频的识别结果和所述预置音频对应的音频内容比较结果不一致,重新收集不一致的原始音频以优化ssp引擎性能。
13、本发明还提供一种终端到云端的语音识别测试装置,包括:
14、预置音频存储模块,用于将预置音频保存在本地文件夹,并通过路径表格对所述预置音频的播放路径及所述预置音频对应的音频内容进行保存;
15、第一命名文件生成模块,用于按照所述路径表格对所述预置音频进行播放,并对播放的所述预置音频进行录音得到实时录音文件,将得到的所述实时录音文件以第一命名进行本地保存;
16、第二命名文件生成模块,用于将得到的所述实时录音文件传送到ssp引擎进行处理,对ssp引擎处理后的所述实时录音文件以第二命名进行本地保存;
17、第三命名文件生成模块,用于将ssp引擎处理后的所述实时录音文件发送到云端进行识别,将上传至云端进行识别的所述实时录音文件以第三命名进行本地保存,输出当前识别的会话标识;
18、第四命名文件生成模块,用于当所述路径表格中的所述预置音频全部识别结束后,通过日志得到所述预置音频对应识别结果和会话标识;通过会话标识获取当前轮次云端识别收到的音频数据,将云端识别收到的音频数据以第四命名进行保存;
19、命名文件比对模块,用于根据第一命名的所述实时录音文件生成单声道音频文件,将所述单声道音频文件、第二命名文件、第三命名文件、第四命名文件的md5值进行比对;
20、识别结果分析模块,用于若md5值比对结果一致,将得到的所述预置音频的识别结果和所述预置音频对应的音频内容进行比较,根据所述预置音频的识别结果和所述预置音频对应的音频内容比较结果判断是否收集原始音频优化ssp引擎性能。
21、作为终端到云端的语音识别测试装置优选方案,所述第一命名文件生成模块中,按照所述路径表格对所述预置音频利用电脑和保真音响进行播放,并通过usb线连接包含语音识别应用的移动设备实时获取设备输出日志。
22、作为终端到云端的语音识别测试装置优选方案,所述命名文件比对模块中,利用第一命名的所述实时录音文件调用裸引擎脚本生成所述单声道音频文件。
23、作为终端到云端的语音识别测试装置优选方案,还包括指定环节重新处理模块,用于将所述单声道音频文件、第二命名文件、第三命名文件、第四命名文件的md5值进行比对过程中,若md5值比对结果不一致,提取md5值不一致的命名文件,对md5值不一致的命名文件对应的处理流程进行重新处理。
24、作为终端到云端的语音识别测试装置优选方案,所述识别结果分析模块中:若所述预置音频的识别结果和所述预置音频对应的音频内容比较结果一致,判定所述预置音频及ssp引擎处理数据符合预设要求;若所述预置音频的识别结果和所述预置音频对应的音频内容比较结果不一致,重新收集不一致的原始音频以优化ssp引擎性能。
25、本发明具有如下优点:将预置音频保存在本地文件夹,并通过路径表格对所述预置音频的播放路径及所述预置音频对应的音频内容进行保存;按照所述路径表格对所述预置音频进行播放,并对播放的所述预置音频进行录音得到实时录音文件,将得到的所述实时录音文件以第一命名进行本地保存;将得到的所述实时录音文件传送到ssp引擎进行处理,对ssp引擎处理后的所述实时录音文件以第二命名进行本地保存;将ssp引擎处理后的所述实时录音文件发送到云端进行识别,将上传至云端进行识别的所述实时录音文件以第三命名进行本地保存,输出当前识别的会话标识;当所述路径表格中的所述预置音频全部识别结束后,通过日志得到所述预置音频对应识别结果和会话标识;通过会话标识获取当前轮次云端识别收到的音频数据,将云端识别收到的音频数据以第四命名进行保存;根据第一命名的所述实时录音文件生成单声道音频文件,将所述单声道音频文件、第二命名文件、第三命名文件、第四命名文件的md5值进行比对,若md5值比对结果一致,将得到的所述预置音频的识别结果和所述预置音频对应的音频内容进行比较,根据所述预置音频的识别结果和所述预置音频对应的音频内容比较结果判断是否收集原始音频优化ssp引擎性能。本发明可以实现全自动化的语音识别测试流程协助排查和定位,直观体现识别准确性,提升内部研发效率,可以作为通用的测试方案,在不同的平台适用。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21636.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表