光纤分布式声学传感信号识别方法、系统、设备及介质
- 国知局
- 2024-06-21 11:32:20
本发明属于光纤传感,涉及一种信号识别方法,尤其涉及一种光纤分布式声学传感(das)信号的跨场景少标签识别方法、系统、设备及介质。
背景技术:
1、基于相敏光时域反射技术(φ-otdr)的光纤分布式声学传感器(das)因其长距离、大容量、高灵敏度和全尺度连续感应能力等优势,它已广泛应用于城市范围内的油气供热管道、通信或电力电缆、周界安防、海底电缆、各种第三方损害和自然灾害等方面的安全监测。
2、近年来,除了在das硬件方面改进确保解调信号的高保真度,以及扩展监测范围、提高检测灵敏度和带宽外,先进的后处理技术也在不断发展,以降低成本提高其感知智能性。在2017年之前,das信号识别主要采用传统的特征提取和分类技术。随着人工智能技术的快速发展,越来越多的深度学习技术被用来进一步提高其识别准确性。例如,基本的一维(1-d)和二维(2-d)卷积神经网络(cnn)、基于注意力的长短时记忆(alstm),以及它们的演化形式如双路径网络(dpn),以及高效的you-only-look-once(yolo),此外还包括多尺度cnn结合隐马尔可夫模型(mcnn-hmm)、1d-cnn结合双向lstm(1d-cnn-bi-lstm)。最近,无监督脉冲神经网络(snn),以及生成对抗网络(gan)也相继被提出。
3、然而,一方面目前的大多数das信号识别模型仅可以在单一场景下运行,当场景发生改变时,需要重新部署且无法利用源场景的知识。为此基于alexnet和支持向量机(alexnet-svm)的迁移学习模型被提出,通过在预训练模型基础上,将一部分网络冻结,利用目标域数据集对另一部分网络进行微调,可缩短模型部署的时间。然而这种迁移学习方法并没有充分的利用源域的知识,导致识别表现不佳。另一方面,现有的das信号识别模型多为监督学习,然而收集大量的标签信号需要耗费人力物力成本,所以为了解决如何利用无标签信号进行训练也是一个关键性问题。因此,半监督生成对抗网络(1d-ssgan)和堆叠稀疏自编码器(ssae)相继被提出。ssgan使用生成器生成的样本作为无标签样本,实际上并没有利用现场的无标签样本,ssae以无监督的方式训练编码器,无法利用标签信息进行训练,因此预训练的编码器可能无法捕获与特定任务相关的有用特征。因此,提取的特征通常是高度抽象的,难以直接与具体标签关联,导致了难以解释的特征表示和较低的识别性能。此外基于vgg16模型的fixmatch的半监督算法也被提出用来进行高速轨道检测,其利用有标签样本进行监督训练,对于无标签样本,预测其弱增强之后的伪标签,与同一样本强增强之后预测结果计算交叉损失熵,以此进行无监督训练。然而现有的das半监督识别方法均缺乏可迁移性。
4、因此本发明中,提出一种结合迁移学习与半监督学习的新型das信号识别方法,针对现有das信号识别中迁移学习以及半监督学习方法的局限性进行改进,并将迁移学习与半监督学习二者特征结合,在一个学习网络中解决了有标签信号样本不足及跨场景识别的双重挑战性问题。
技术实现思路
1、本发明的目的在于:提供一种光纤分布式声学传感信号识别方法、系统、设备及介质,通过对迁移学习以及半监督学习方法的局限性进行改进,并将迁移学习与半监督学习二者特征结合,解决跨场景识别的问题。
2、本发明为了实现上述目的具体采用以下技术方案:
3、光纤分布式声学传感信号识别方法,包括以下步骤:
4、步骤1:数据准备;
5、获取图像并形成图像数据集;
6、采集不同场景下的不同类型的das信号,形成das信号数据集,并对das信号数据集中的das信号进行预处理,得到二维时频图数据集;
7、步骤2:构建信号识别网络模型;
8、构建信号识别网络模型,信号识别网络模型采用resnet-34网络;
9、步骤3:训练信号识别网络模型;
10、利用步骤1中的图像数据集对信号识别网络模型进行预训练训练,再经过某一场景下das二维时频图数据集对信号识别网络模型进行训练调整,得到源模型;
11、在源模型基础上,利用其它场景所对应的das二维时频图数据集对信号识别网络模型进行迁移学习和半监督训练,从而得到最终的识别模型;
12、步骤4:das信号实时识别;
13、实时采集das信号,并输入步骤3构建的识别模型,识别模型输出信号识别结果。
14、步骤1中,获取图像数据集和采集不同场景下的不同类型的das信号时,具体方法为:
15、获取imagenet数据集作为图像数据集,其包括一千种共计一百余万张图片。
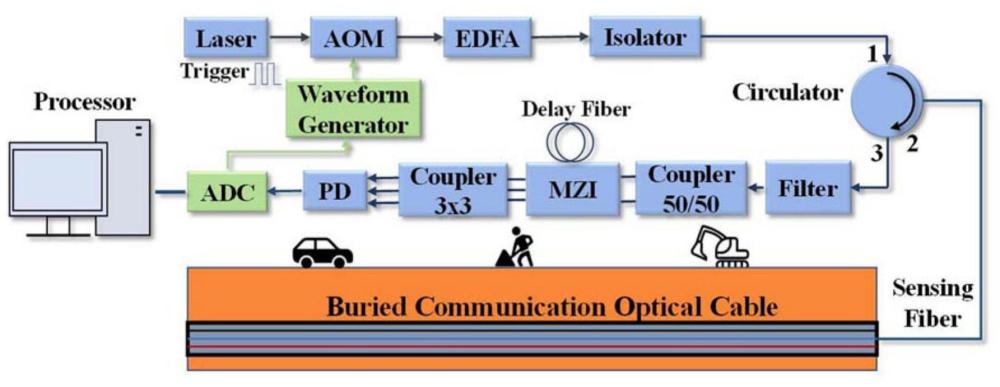
16、利用基于相敏光时域反射仪的分布式光纤声波传感系统或分布式光纤振动传感系统,采集多场景下管道沿线的声音或振动信号,从而形成不同场景下多种类型的das信号数据集。
17、进一步地,步骤1中,获取图像数据集和采集不同场景下的不同类型的das信号时,具体方法为:
18、获取imagenet数据集作为图像数据集,其包括一千种共计一百余万张图片。
19、利用基于相敏光时域反射仪的分布式光纤声波传感系统或分布式光纤振动传感系统,采集多场景下管道沿线的声音或振动信号,从而形成不同场景下多种类型的das信号数据集。
20、进一步地,在对das信号进行预处理时,具体处理方法为:
21、原始采集到的das信号为时空矩阵形式,将有事件发送的空间点的一维时序信号提取出来并截断,对截断之后时序信号进行傅里叶变换得到时频图,得到二维时频图数据集。
22、进一步地,通过傅里叶变换得到时频图,时频图的计算方式为:
23、
24、其中,w(n)为汉明窗,l为窗长度,r是窗的连续帧之间的样本数,mr(m=1,2,3,...)是以窗口数据为中心的离散时间傅里叶变换(dtft)的时间。
25、进一步地,步骤2中,resnet-34网络包括依次设置的输入层、第一卷积模块、第二卷积模块、第三卷积模块、第四卷积模块和全连接层,第一卷积模块、第二卷积模块、第三卷积模块、第四卷积模块中卷积层的数量分别是6、8、12、6。
26、进一步地,步骤3中,在进行迁移学习和半监督训练时,具体步骤为:
27、步骤3.1,迁移学习;
28、步骤3.1.1,通过源域预训练信号识别网络模型得到源模型,将目标域的训练样本分别输入到源模型与目标模型中,得到源特征与目标特征,并计算源特征与目标特征的交叉熵损失;
29、步骤3.1.2,设置阈值,计算源模型预测目标域样本结果的熵,并筛选出熵低于阈值的样本进行知识蒸馏;
30、步骤3.2,半监督学习;
31、步骤3.2.1,对于有标签的样本,计算该样本的预测结果与真实标签之间的交叉熵损失,构成有监督损失ls;对于无标签的样本,先预测出该样本的伪标签,并计算伪标签与该样本的强增强样本的预测结果的交叉熵损失,构成无监督损失lu;
32、步骤3.2.2,通过arc计算lr约束有标签样本与无标签样本特征分布间的mmd距离。
33、进一步地,信号识别网络模型的整体损失函数为:
34、l=λsls+λulu+λklk+λrlr
35、步骤3.1.1中,交叉熵损失lk表示为:
36、
37、
38、步骤3.2.1中,有监督损失ls、无监督损失lu分别表示为:
39、
40、
41、
42、步骤3.2.2中,arc计算lr的具体过程为:
43、
44、其中,λs、λu、λk、λr均表示权重因子;
45、表示目标数据集中的小批量有标签样本,
46、表示目标数据集中的小批量无标签样本,
47、与分别为源模型与目标模型提取出的目标域样本特征;bl目标数据集中的小批量有标签样本的样本数,bu目标数据集中的小批量无标签样本的样本数,表示自适应样本权值,表示目标域有标签样本,表示目标域无标签样本,表示目标域有标签样本的标签,i表示样本序号,l表示损失,表示目标域有标签数据集,表示目标域无标签数据集,k表示知识蒸馏,表示样本预测结果熵,εk表示知识蒸馏样本选择阈值;表示模型对有标签样本的预测结果,表示有标签的真实标签与预测结果间的交叉熵;表示模型对无标签样本的预测结果,并作为伪标签;表示无标签样本的强增强结果,表示模型对无标签样本强增强之后的预测结果,表示权重系数;pi表示目标域有标签样本标签,表示无标签样本强增强之后提取的特征,表示无标签样本的预测伪标签与其强增强之后预测结果的交叉损失熵;ql、qu分别表示有标签样本特征与无标签样本特征的分布,κ表示高斯径向基函数;m表示用于计算lr的有标签样本数,n表示用于计算lr的有标签样本数,表示目标域无标签样本特征。
48、光纤分布式声学传感信号识别系统,包括:
49、数据准备模块,用于图像并形成图像数据集;
50、采集不同场景下的不同类型的das信号,形成das信号数据集,并对das信号数据集中的das信号进行预处理,得到二维时频图数据集;
51、信号识别网络模型构建模块,用于构建信号识别网络模型,信号识别网络模型采用resnet-34网络;
52、信号识别网络模型训练模块,用于利用数据准备模块中的imagenet图像数据集对信号识别网络模型进行训练,再经过某一场景下das二维时频图数据集对信号识别网络模型进行训练调整,得到源模型;
53、在源模型基础上,利用其它场景所对应的das二维时频图数据集对信号识别网络模型进行迁移学习和半监督训练,从而得到最终的识别模型;
54、das信号实时识别模块,用于实时采集das信号,并输入信号识别网络模型训练模块最后选择出来的识别模型,识别模型输出信号识别结果。
55、一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述方法的步骤。
56、一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行上述方法的步骤。
57、本发明的有益效果如下:
58、1.本发明旨在解决具有不足标签信号的跨场景下识别的困难问题,其通过在新的应用场景下快速部署识别模型,提供了一种更好的迁移学习工具,在迁移学习基础上增加半监督学习能力,不仅可以充分利用源模型获得的知识,还可以利用目标域有标签样本和无标签样本的价值;同时,它还使模型中的半监督学习部分具有可迁移性。
59、2.本发明中,在迁移学习子网中,采用了知识蒸馏(kd)的思想,不仅利用预训练模型为模型训练提供了更好的起点,而且通过自适应知识一致性(akc)约束源模型和目标模型提取的目标域有无标签样本特征之间的一致性,继续提取有用信息,充分提取源域知识。
60、3.本发明中,在半监督学习部分,采用改进的fixmatch算法,它不仅利用了一般的半监督学习策略,即一致性正则化和伪标记,而且还对有标签和未无标签样本的特征分布施加了自适应表示一致性(arc)约束;此外,嵌入在fixmatch中的数据增强方法已被修改以适应das信号的时间特性。
61、4.本发明中,现场测试结果表明,结合模型的识别准确性高于单独的迁移学习或半监督学习网络。获得了有用的指导信息,以更有效地使用迁移学习和半监督学习方法:(1)在更接近的应用场景间迁移可以使模型实现更快的收敛和更高的识别准确性,相比于跨越更远的源域;(2)在训练集中不同数量的已标记和未标记样本都提高了识别准确性,但已标记数量的增加比未标记数量的增加带来更显著的改善。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22085.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表