一种针对特定内容语音片段的声纹特征提取方法与流程
- 国知局
- 2024-06-21 11:32:41
本发明涉及说话人识别,特别涉及一种针对特定内容语音片段的声纹特征提取方法。
背景技术:
1、近年来,随着模式识别和人工智能的发展,说话人识别技术近年来取得了巨大的发展并有着越来越广泛的应用,成为了语音识别技术研究热点之一。
2、声纹识别技术,即说话人识别技术,在信息安全、公安司法、军事国防上都有着很重要的应用,目前声纹识别在很多数据集上都取得了很好的性能。随着互联网及移动设备的普及,身份验证的重要性尤为突出。在这一背景下,声纹密码的使用可以在原有身份验证技术的基础上增加账户访问的安全性和可靠性。在实际应用中,声纹识别技术常常使用特定内容进行设置,由于随机数字串的简单通用,成为了说话人识别技术在密码口令上应用的主流趋势。
3、但因为特定内容的协同发音问题(即某个发音器官的发音受到前后发音器官影响的现象),常用声纹特征提取技术未考虑特定内容以及为提升用户体验对特定内容长度的限制(短语音片段),使得实际应用中基于特定内容的说话人识别系统表现不佳。
4、当前,特定内容语音片段往往只有2-4秒的时间,使用普通的算法难以完全利用到语音特征中的有效信息,如何更好的提取包含特定内容的短语音片段的声学特征,已经成为了该领域的研究重点。
技术实现思路
1、本技术的目的在于解决现有技术存在的缺陷。
2、本技术提供了一种针对特定内容语音片段的声纹特征提取方法,所述声纹特征提取方法考虑到特定内容语音片段的短暂瞬时性,从多个尺度提取语音特征中的有效信息,本技术的声纹特征提取方法高效准确,实时性强。
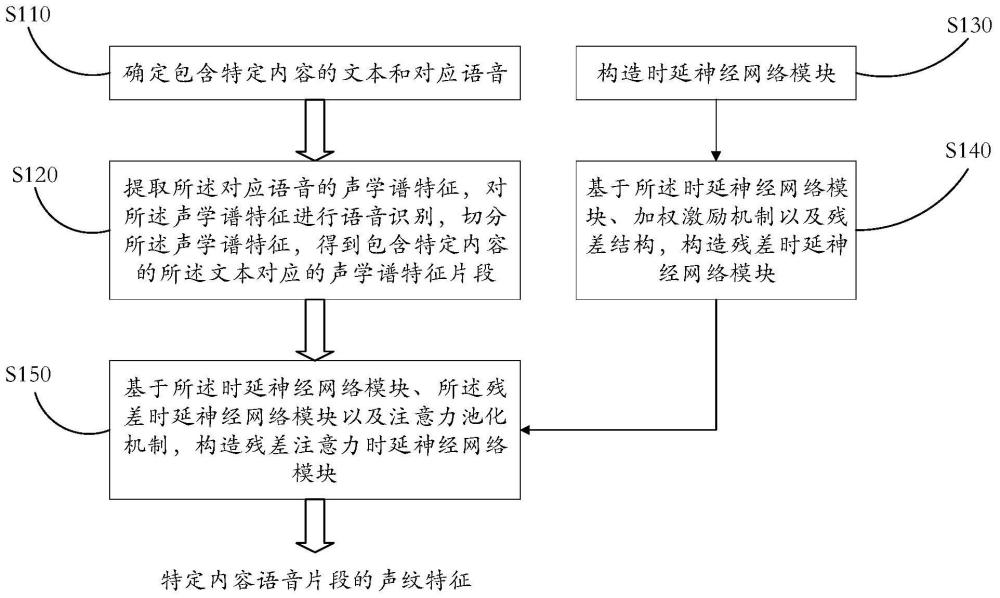
3、本技术提供了一种针对特定内容语音片段的声纹特征提取方法,所述声纹特征提取方法,包括:确定包含特定内容的文本和对应语音;提取所述对应语音的声学谱特征,对所述声学谱特征进行语音识别,切分所述声学谱特征,得到包含特定内容的所述文本对应的声学谱特征片段;基于时延神经网络模块、残差时延神经网络模块以及注意力池化机制,构造残差注意力时延神经网络模块,用于从声学谱特征片段中,输出特定内容语音片段的声纹特征,其中,所述时延神经网络模块,用于对输入特征信息进行时间长度上的一维卷积操作,提取声学特征信息,所述残差时延神经网络模块是基于所述时延神经网络模块、加权激励机制以及残差结构而构造的,用于从输入特征信息中,提取多尺度特征信息。
4、在一个可行的实施例中,所述提取所述对应语音的语音声学谱特征,对所述语音声学谱特征进行语音识别,切分所述语音声学谱特征,得到包含特定内容的所述文本对应的语音声学谱特征片段,包括:基于测试说话人或注册说话人的数字串朗读语音,提取声学谱特征;对所述声学谱特征进行端到端的语音识别,得到对应的数字串文本标签,以及对应的数字段和静音段的起始、结束时间标签;根据所述对应的数字段和静音段的起始、结束时间标签,对所述语音声学谱特征进行切分,并去除静音片段,得到数字段对应的声学谱特征片段。
5、在一个可行的实施例中,所述基于测试说话人或注册说话人的数字串朗读语音,提取声学谱特征,包括:基于测试说话人或注册说话人的数字串朗读语音,得到美尔倒谱特征(mfcc)或者感知线性预测特征(plp),对该特征进行差分倒谱特征(delta)分析,每帧可以得到60维特征向量,进而提取得到声学谱特征。
6、在一个可行的实施例中,所述时延神经网络模块,用于对输入特征信息进行时间长度上的一维卷积操作,提取声学特征信息,包括:使用一定大小的卷积核在时间尺度上进行一维卷积,提取特征信息,实现不同通道特征的融合;对卷积后的输出特征信息,使用leakyrelu(leaky rectified linear unit)激活函数进行激活计算;对leakyrelu激活函数计算后的输出特征信息,使用batchnorm函数进行批标准化,所述batchnorm函数的均值和标准差由各维度的均值和标准差计算得出。
7、在一个可行的实施例中,所述时延神经网络模块,用于对输入特征信息进行时间长度上的一维卷积操作,提取声学特征信息,包括:通过transpose函数,对输入特征信息进行转置;通过convolution函数,对转置后的信息进行卷积处理;通过leakyrelu激活函数和batchnorm函数,对卷积处理后的信息进行标准化;通过transpose函数,对标准化后的信息进行转置并输出。
8、在一个可行的实施例中,所述leakyrelu激活函数,包括:leakyrelu激活函数,leakyrelu(x)=max(0,x)+αmin(0,x),其中,α是一个较小的正数;所述batchnorm函数,包括:其中gamma和beta为可学习的参数向量。
9、在一个可行的实施例中,所述残差时延神经网络模块是基于所述时延神经网络模块、加权激励机制以及残差结构而构造的,用于从输入特征信息中,提取多尺度特征信息,,包括:使用不同卷积核大小和卷积步长的至少一层所述时延神经网络模块;使用linear1线性函数进行降维,经过relu激活函数进行激活,再通过linear2线性函数进行升维,通过sigmoid激活函数进行激活,得到加权激励系数;将加权激励系数作用到最后一个时延神经网络模块的输出特征信息,输出经过加权激励机制的输出特征信息;将经过加权激励机制的所述输出特征信息与第一层时延神经网络模块的输入特征信息相加得到此层网络的输出特征信息。
10、在一个可行的实施例中,所述残差时延神经网络模块是基于所述时延神经网络模块、加权激励机制以及残差结构而构造的,用于从输入特征信息中,提取多尺度特征信息,包括:多个所述时延神经网络模块,加权激励机制由多个线性层及对应激活函数组成,残差结构提取残差信息并与原始特征(第一层时延神经网络模块的输入特征信息)叠加;在这个过程中使用分组卷积减小计算量。
11、在一个可行的实施例中,所述残差时延神经网络模块是基于所述时延神经网络模块、加权激励机制以及残差结构而构造的,用于从输入特征信息中,提取多尺度特征信息。该模块具体包括:多个时延神经网络模块,通过时间长度上的一维卷积操作提取声学特征中的信息;引入加权激励机制,优选特征图中的有效部分;引入残差结构提高深层网络的性能。
12、在一个可行的实施例中,所述relu激活函数,包括:relu(x)=max(0,x);所述sigmoid激活函数,包括:
13、在一个可行的实施例中,所述基于所述时延神经网络模块、所述残差时延神经网络模块以及注意力池化机制,构造残差注意力时延神经网络模块,包括:通过至少一层时延神经网络模块、至少一层残差时延神经网络模块,提取特征信息;使用convolution函数对最后一层时延神经网络模块的输出特征信息进行一维卷积,通过tanh激活函数激活,再使用convolution函数进行一维卷积,再经过softmax激活函数后得到注意力系数,将注意力系数作用到最后一层时延神经网络模块的输出特征信息,得到均值和标准差,将所述均值和标准差拼接后,输出经过注意力池化机制的特征信息;通过batchnorm函数,对所述经过注意力池化机制的特征信息进行标准化,经过线性层输出特定内容语音片段的声纹特征。
14、在一个可行的实施例中,所述tanh激活函数,包括:所述softmax激活函数,包括:
15、在一个可行的实施例中,所述构造残差注意力时延神经网络模块,包括:多层所述时延神经网络模块和多层所述残差时延神经网络模块相连接;注意力池化机制由多个一维卷积及对应激活函数组成,得到注意力系数后作用到注意力池化机制的输入后求得均值和标准差;使用batchnorm函数进行批标准化;最后通过线性层得到分类结果的置信度。
16、本技术提供了一种针对特定内容语音片段的声纹特征提取方法,所述声纹特征提取方法,包括:通过预处理阶段,得到声学谱特征片段;构造时延神经网络模块;基于所述时延神经网络模块、加权激励机制以及残差结构,构造残差时延神经网络模块;基于所述时延神经网络模块、所述残差时延神经网络模块、注意力池化机制,构造残差注意力时延神经网络模块;将所述声学谱特征片段输入所述残差注意力时延神经网络模块,得到特定内容语音片段的声纹特征。本所述提供的声纹特征提取方法,从多个尺度提取特征的深层次信息,并结合残差网络、加权激励、注意力池化机制等方法,能够有效的对特定内容语音片段进行建模及识别,得到声纹特征。
17、在本技术的声纹特征提取算法的框架结构中,不同网络模块之间互相调用。本技术的声纹特征提取技术,能够对短暂特定内容语音片段的音频特征进行精细化、深层化的处理,有效提高了特定内容语音的说话人表征的高效性和准确性。常用的声纹提取技术未考虑说话内容,本技术提供了一种针对特定内容语音片段提取声纹特征的技术,可以扩展声纹技术的应用场景。常规的神经网络算法从某一角度提取特征信息,对于特定内容语音片段,很难提取出丰富的声纹信息。本技术提供的算法从多个尺度提取特征的深层次信息,并结合残差网络、加权激励、注意力机制等方法,能够有效的对特定内容语音片段进行建模及识别。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22131.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。