一种智能家具控制器及控制方法与流程
- 国知局
- 2024-06-21 11:32:27
本发明涉及家具控制器,特别涉及一种智能家具控制器及控制方法。
背景技术:
1、智能家具提供智能控制旨在提高用户操作的便利性,智能家具集成语音识别后,用户仅需在使用智能家具过程中通过语音说出触发指令,智能家具的控制器通过采集用户的语音信号并进行语音识别,便可根据语音识别结果对智能家具进行控制,而不会影响用户当前对智能家具功能的使用过程。即用户不再需要寻找遥控器或实体按钮来操作功能,提高用户操作的便利性。例如,用户闭眼躺在智能沙发椅上之后,想要调整沙发椅的按摩功能、加热功能时,可以在不睁开眼也不用动的情况下,通过语音说出触发指令,直接控制沙发椅执行相应的加热功能等。
2、沙发椅等智能家具放置在客厅等作为家庭公共空间的地方,一次只有一个使用用户,在用户使用该智能家具并使用语音识别进行功能控制时,容易受到处于同一个空间下的其他人的说话声或者电视声音的干扰。例如,紧挨着沙发椅的椅子上用户说话声或电视播放声音与用户声音混合,导致声源之间的干扰,使得无法有效地分辨和提取目标声源,降低语音信号的清晰度和质量。经检索,相关技术中可以利用麦克风阵列的声源定位并结合波束成形(beamforming)技术来增强指定音区的语音信号,实现有效分辨和提取目标声源,从而提升语音识别的准确性。如专利文献1披露了可以采用麦克风阵列技术来实现仅采集指定音区(主音区)的声音用于语音控制,并且屏蔽剩余音区的方案,该方案可以提升语音识别的准确性。并且,专利文献1进一步还披露了由于用户移动而导致的用户声源跨音区的解决方案,即用户移动到其他音区之后,认为用户声源从之前的主音区跨入另一个音区,所以需要更新用户所处的最新位置为主音区。
3、如果将专利文献1的方案应用到沙发椅等智能家具场景时,可以将沙发椅边框(包括沙发椅的扶手、靠背的外侧面等)包围的区域作为主音区,通过只对主音区的声音进行采集和响应,可以提高声音信号质量和语音识别准确性,并且用户使用沙发椅(即躺在沙发椅或坐在沙发椅上的状态)时,由于用户不移动,也不会面临专利文献1中的用户声源跨音区问题。
4、但是,在沙发椅的语音控制场景中,却存在非用户声源跨音区的问题,即沙发椅一般布置在客厅并与其他的椅子紧挨在一起,所以在客厅活动的其他人或者坐在紧挨着沙发椅的椅子上的其他人的头部很容易挨着沙发椅主音区的边界,甚至进入到沙发椅的主音区范围内,该现象定义为非用户声源跨音区问题。
5、由于沙发椅等智能家具的使用场景是公共空间的多人场景,并且存在非用户声源夸音区问题,会导致从沙发椅的主音区采集的目标语音除了包括用户声音之外,还混合有紧挨着沙发椅的椅子上用户说话声,降低语音信号的清晰度和质量以及语音识别准确性。
6、专利文献1,中国专利,公开号,cn111986678b,专利名称,一种多路语音识别的语音采集方法、装置,公开日,2023-12-29。
技术实现思路
1、本发明的目的在于提供一种智能家具控制器及控制方法, 能够根据用户的坐姿动态调整智能家具的响应音区的范围与用户的嘴部位置相匹配,得到以声源为中心的范围更小的响应音区,降低非用户声源进入响应音区的几率,从而获得更高质量的语音信号,提升语音识别准确性。
2、为实现上述发明目的,提供一种智能家具控制方法,所述方法包括:
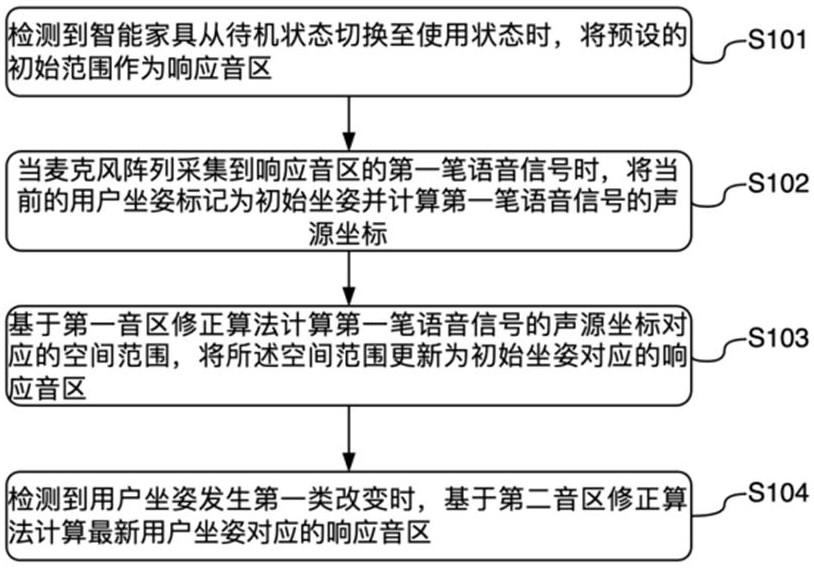
3、检测到智能家具从待机状态切换至使用状态时,将预设的初始范围作为响应音区;
4、当麦克风阵列采集到响应音区的第一笔语音信号时,将当前的用户坐姿标记为初始坐姿并计算第一笔语音信号的声源坐标;
5、基于第一音区修正算法计算第一笔语音信号的声源坐标对应的空间范围,将所述空间范围更新为初始坐姿对应的响应音区;
6、检测到用户坐姿发生第一类改变时,基于第二音区修正算法计算最新用户坐姿对应的响应音区。
7、作为进一步的改进,所述智能家具包括坐垫和靠背、部署在坐垫上的第一压力传感器阵列以及部署在靠背上的第二压力传感器阵列,所述初始坐姿为仅有坐垫平面上的第一压力传感器阵列被用户触发时的用户坐姿;
8、所述基于第一音区修正算法计算第一笔语音信号的声源坐标对应的空间范围,具体包括:
9、根据以下的公式一计算出第一笔语音信号的声源坐标对应的空间范围(x,y,z):
10、
11、其中,为初始坐姿状态下,坐垫平面上的第一压力传感器阵列中被用户触发的压力传感器组成的几何图形的重心点p0的坐标,r为重心点p0到第一笔语音信号的声源坐标的距离,θ为预设的人体摆动角度,0°≤θ≤45°。
12、作为进一步的改进,用户坐姿发生第一类改变是指,用户坐姿改变前后仅有坐垫平面上的第一压力传感器阵列被用户触发;
13、所述基于第二音区修正算法计算最新用户坐姿对应的响应音区,具体包括:
14、获取最新坐姿状态下,坐垫平面上的第一压力传感器阵列中被用户触发的压力传感器组成的几何图形的重心点p1的坐标;
15、用p1减去p0,得到平移偏移量;
16、将当前响应音区的所有坐标点加上平移偏移量,得到最新坐姿对应的响应音区的所有坐标点。
17、作为进一步的改进,所述方法还包括:
18、利用第三音区修正算法对公式一进行修正;
19、修正后的公式一为:
20、
21、其中,d为通过实验预先测定的坐垫下沉深度;
22、通过以下步骤确定坐垫下沉深度d:
23、获取坐垫上的第一压力传感器阵列测得的压力值;
24、根据所述压力值查表确定坐垫下沉深度d。
25、作为进一步的改进,所述方法还包括:
26、当第一压力传感器阵列中压力值最大的压力传感器的压力值与其他所有被触发的压力传感器的差值均大于预设压力差值时,以压力最大的压力传感器的坐标点作为该用户坐姿下,坐垫平面上的第一压力传感器阵列中被用户触发的压力传感器组成的几何图形的重心点的坐标。
27、作为进一步的改进,所述智能家具包括坐垫和靠背、部署在坐垫上的第一压力传感器阵列以及部署在靠背上的第二压力传感器阵列,所述初始坐姿为坐垫平面上的第一压力传感器阵列和靠背上的第二压力传感器阵列二者同时被用户触发时的用户坐姿;
28、所述基于第一音区修正算法计算第一笔语音信号的声源坐标对应的空间范围,具体包括:
29、根据以下的公式二计算出第一笔语音信号的声源坐标对应的空间范围(x,y,z):
30、
31、其中,为初始坐姿状态下,第一笔语音信号的声源坐标,r为预设的颈部摆动长度,8cm≤r≤12cm,a,b,c是与靠背所在平面垂直的法向量的三个分量,d 是将靠背所在平面的坐标带入后求得的常数。
32、作为进一步的改进,所述方法还包括:
33、检测到用户坐姿发生第二类改变时,基于第四音区修正算法计算最新用户坐姿对应的响应音区;其中,用户坐姿发生第二类改变是指,用户坐姿改变前后,靠背上的第二压力传感器阵列均被用户触发并且坐垫平面上的第一压力传感器阵列均被用户触发;
34、所述基于第四音区修正算法计算最新用户坐姿对应的响应音区,具体包括:
35、获取在用户坐姿改变前,靠背平面上的第二压力传感器阵列中被用户触发的压力传感器组成的几何图形的重心点p2的坐标;
36、获取在用户坐姿改变后,靠背平面上的第二压力传感器阵列中被用户触发的压力传感器组成的几何图形的重心点p3的坐标;
37、用p3减去p2,得到平移偏移量;
38、将当前响应音区的所有坐标点加上平移偏移量,得到最新坐姿对应的响应音区的所有坐标点。
39、作为进一步的改进,所述方法还包括:
40、检测到用户坐姿发生第三类改变时,确定改变后最新的用户坐姿;第三类改变是指,用户坐姿改变前后,靠背上的第二压力传感器阵列分别处于被用户触发和不被用户触发的状态;
41、如果最新的用户坐姿为仅有坐垫平面上的第一压力传感器阵列被用户触发时的用户坐姿,则基于第二音区修正算法计算最新用户坐姿对应的响应音区;
42、如果最新的用户坐姿为坐垫平面上的第一压力传感器阵列和靠背上的第二压力传感器阵列二者同时被用户触发时的用户坐姿,则基于第四音区修正算法计算最新用户坐姿对应的响应音区。
43、作为进一步的改进,所述方法还包括:
44、检测到用户坐姿发生第四类改变时,基于第五音区修正算法计算最新用户坐姿对应的响应音区;其中,用户坐姿发生第四类改变是指,在靠背上的第二压力传感器阵列被用户触发的情况下,用户坐姿改变前后,靠背的倾斜角度发生变动;
45、所述基于第五音区修正算法计算最新用户坐姿对应的响应音区,具体包括:
46、基于靠背倾斜角度的变动,确定变动前后靠背所在平面的旋转矩阵;
47、基于所述旋转矩阵将当前响应音区的所有坐标点转换得到最新坐姿对应的响应音区的所有坐标点;
48、其中,所述旋转矩阵为:
49、α为靠背倾斜角度的变动值,0°≤α≤60°。
50、另一方面,本发明提供了一种智能家具控制器,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器执行所述计算机程序以实现上述方法的步骤。
51、有益效果:
52、本发明提供的一种智能家具控制器及控制方法,能够根据用户的坐姿动态调整智能家具的响应音区的范围与用户的嘴部位置相匹配,得到以声源为中心的范围更小的响应音区,降低非用户声源进入响应音区的几率,从而获得更高质量的语音信号,提升语音识别准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22105.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表