一种基于音频特征形状匹配的乐器演奏质量评价方法与流程
- 国知局
- 2024-06-21 11:32:30
本发明属于计算机,具体涉及一种基于音频特征形状匹配的乐器演奏质量评价方法。
背景技术:
1、乐器演奏从节奏感、音准、技术难度、表现力、音色等多个方面来考核学生的乐器演奏功底,目前乐器演奏的好坏大多通过人为的方式进行判断,其判断结果受人为因素的影响较大;同时乐器随着演奏的时间变化会产生音准的偏差以及评分人员的状态,对于评分的准确性会降低。
2、为进一步提高乐器演奏考级的科学性和权威性,建立公正公平的考评机制,开发智能音乐演奏评价系统势在必行,该系统可以客观分析学员的演奏录音,通过对音频数据的处理分析评判演奏的节奏、音准、音色、谱子阅读、表达力等多个维度,并自动生成打分结果和考级建议,辅助教师更加准确地进行评价,提高评价效率,最大限度地减少主观因素对评分结果的影响,保证考级结果的公正公平,使每位学员都能获得公平对待、获得合理的学习评价和考核反馈。
技术实现思路
1、为解决现有技术中存在的上述问题,本发明提供了一种基于音频特征形状匹配的乐器演奏质量评价方法,通过评估音频的难度系数和音频节奏、旋律相似度获取整体评分,使得节奏和旋律提取更加稳定和鲁棒。
2、本发明的目的可以通过以下技术方案实现:
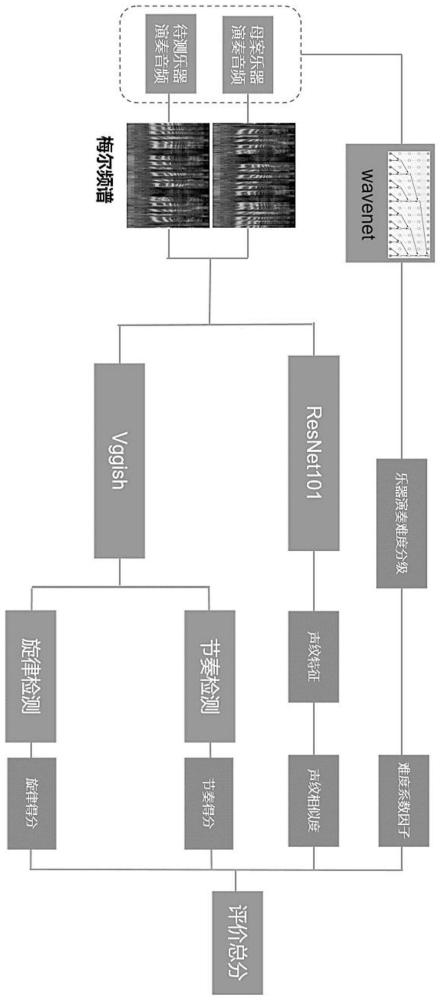
3、一种基于音频特征形状匹配的乐器演奏质量评价方法,包括以下步骤:
4、s1、评估乐器演奏难度:首先对乐器演奏的音频进行演奏难度评级,将评级的难度系数作为整体的基准系数;
5、s2、声纹提取和计算相似度,包括以下步骤:
6、s21、创建数据列表,收集乐器演奏的数据,通过aukit处理音频并进行降噪和去除静音;
7、s22、采用librosa对输入的乐器演奏音频进行短时傅里叶变换得到音频的梅尔频谱,其尺度为257*257;
8、s23、采用改进的resnet101自动学习关注音频的关键时频点提取音频特征时;
9、s24、采用形状匹配的方法计算音频特征灰度图的相似度;
10、s3、节奏检测和旋律检测:提取不同乐器的演奏节奏特征和旋律特征;
11、s4、获取试卷评分:根据条件评价和相似性对比融合,同时结合难度系数、整体相似度、乐器演奏的节奏和旋律的评价输出,获取整体分数。
12、进一步地,所述步骤s1中,评估乐器演奏难度,包括以下步骤:
13、s11、建立一个包括乐器演奏音频数据的数据集,根据演奏难度对数据按进行标注;构建wavenet模型,输入为乐器演奏音频波形,输出为对应的难度星级;
14、s12、模型通过编码器编码音频输入特征,然后输入到wavenet模型的膨胀因果卷积层堆叠中学习音频的时序相关信息;
15、s13、在卷积层之间加入条件化特征,提供有关演奏难度的额外信息,最终分类器输出预测的难度等级;
16、s14、通过训练模型,学习音频波形与演奏难度之间的对应关系。
17、进一步地,所述步骤s13中,wavenet模型额外信息添加方式包括:
18、构建条件化向量,包括代表难度的特征;
19、在wavenet模型的每个膨胀卷积层添加条件连接,将条件化向量输入到每个层;并将条件化向量映射到与膨胀卷积层输出相匹配的维度,然后加入到层输出中;
20、在模型训练时,除了音频输入和难度标签,还需同时提供对应的条件化特征作为模型输入;
21、引入线性投影层或多层感知器,将乐器演奏难度条件化特征转换成更抽象的表征。
22、进一步地,所述步骤s23中,resnet101的改进包括以下步骤:
23、时域注意力:在residual块之间添加时域注意力模块,通过时域注意力模块对时域上的输入特征生成一组权重,对时域上不同时间步的特征进行校准,时域权重通过时间步上特征的全局平均池化并dense层获得,权重与residual块的输入特征做点积,实现时域上的动态特征选择;
24、频域注意力:对每个频带生成权重,然后与输入做点积操作,频域权重通过对频带上特征做自注意力机制来学习;
25、时频注意力:同时加入时域和频域的双向注意力模块,实现对时域和频域的动态特征选择,提供时间和频率上的上下文,生成二维权重矩阵,选择关注的时频点;
26、层次式注意力:在网络的多个层次添加注意力模块,形成层次化的时频注意力,分级关注音频特征,最后提取出1024*n的音频特征,其中n为音乐的切片序列,并将1024*n的音频特征进行尺寸变换,归一成512*512的灰度图。
27、进一步地,所述步骤s24中,计算音频特征灰度图的相似度包括以下步骤:
28、边界匹配:检测灰度图的边界,使用距离变换计算两个边界的距离,距离越近相似度越高;
29、区域匹配:提取像素值较暗的声纹区域,计算两图重叠区域的面积,重叠面积占比越大则相似度越高;
30、轮廓匹配:提取声纹灰度图的轮廓线,计算两图轮廓线之间的关联性,确定匹配对数,匹配对数越多相似度越高。
31、进一步地,所述步骤s3中,节奏检测和旋律检测包括以下步骤:
32、s31、在vggish输入层前加入预处理模块,提取音频的节拍、拍号信息以及旋律midi信息,提供节奏特征和旋律特征;
33、s32、在卷积块之间加入循环神经网络或者时序卷积层,学习音频的节奏时序模式;
34、s33、调整卷积核大小,使用跨度更长的7*7的空洞卷积核,捕捉较长的音乐节奏模式和旋律模式;
35、s34、在模型输出端,加入基于强化学习的节奏评估模块,设置节奏和旋律预测作为环境、错误预测作为负反馈,训练模型优化节奏评估;
36、s35、构建多任务学习框架,同时进行音乐时序建模、节奏预测和音乐风格分类,共享底层特征;
37、s36、收集包括拍号、速度变化丰富的数据集,并应用数据增强技术扩充训练数据;
38、s37、在训练目标中加入对抽节奏特征的一致性约束损失,增强特征的鉴别性。
39、进一步地,所述步骤s4中,获取试卷评分的整体评价公式为:
40、s=τ*(0.5*m+0.25*k+0.25*l)
41、其中,τ为待检测音频相对母案音频的难度系数比值,m为待检测音频与母案音频的相似度,k为待检测的音频的节奏与母案音频的相似度,l为待检测音频的旋律与母案的相似度。
42、本发明的有益效果为:
43、本发明改进了wavenet来针对多种类型的乐器演奏音频进行难度系数评估,具有广泛的适应性和鲁棒性;通过采用改进的resnet结构,专门适应乐器音频进行特征提取,并利用二维的灰度形状匹配评价方法来对特征图进行多维评价,真实反应了乐器演奏的客观评价指标。
44、本发明改进了vggish方法,专门针对多种类型的乐器演奏音频进行节奏和旋律提取,使得节奏和旋律提取更加稳定和鲁棒,在考虑量化的同时又对其本身的艺术性进行更大程度的考量和还原。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22114.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表