语音合成方法和装置与流程
- 国知局
- 2024-06-21 11:32:29
本公开涉及人工智能领域,并且更具体地涉及一种语音合成方法、语音合成装置和设备以及计算机可读存储介质。
背景技术:
1、人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
2、人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、预训练模型技术、操作/交互系统、机电一体化等技术。其中,预训练模型又称大模型、基础模型,经过微调后可以广泛应用于人工智能各大方向下游任务。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
3、在现今生活中,语音技术(speech technology)已被广泛应用。语音技术的关键技术有自动语音识别技术(automatic speech recognition,asr)、语音合成技术(text tospeech,tts)以及声纹识别技术。让计算机能听、能看、能说、能感觉,是未来人机交互的发展方向,其中语音成为未来最被看好的人机交互方式之一。歌唱语音合成(singing voicesynthesis,svs)是语音合成的一个分支,旨在根据包含不同类型音乐特征(例如音符和节拍信息)的歌词和乐谱来构造歌唱声音。相比于tts使机器“开口说话”,歌唱语音合成则是让机器唱歌。在人机交互更加频繁和智能的互联网时代,歌唱语音合成为人机交互增添了趣味性,逐渐受到工业界和学术界的关注。相比于tts,歌唱语音合成需要更多的输入信息,例如乐谱中的音高信息、节拍信息等等,其模型构建、模型训练等也更为复杂。
4、通常,语音合成系统可以包括声学模型和声码器两个部分,其中,声学模型的目的是将文本映射为声学特征,例如梅尔谱,声码器的目的则是基于声学特征来合成语音。目前,出现了一些端到端的歌唱语音合成方法,例如visinger、visinger2等,其可以在给定输入乐谱的情况下直接生成歌声波形。然而,诸如visinger、visinger2等的现有端到端歌唱语音合成方法没有很好地考虑人类语音合成机制,对于音高信息的建模也有所欠缺,使得最终的合成歌声质量仍有很大的改善空间。
技术实现思路
1、针对以上问题,本公开提出了一种语音合成方法、语音合成装置和设备、计算机可读存储介质以及计算机程序产品。
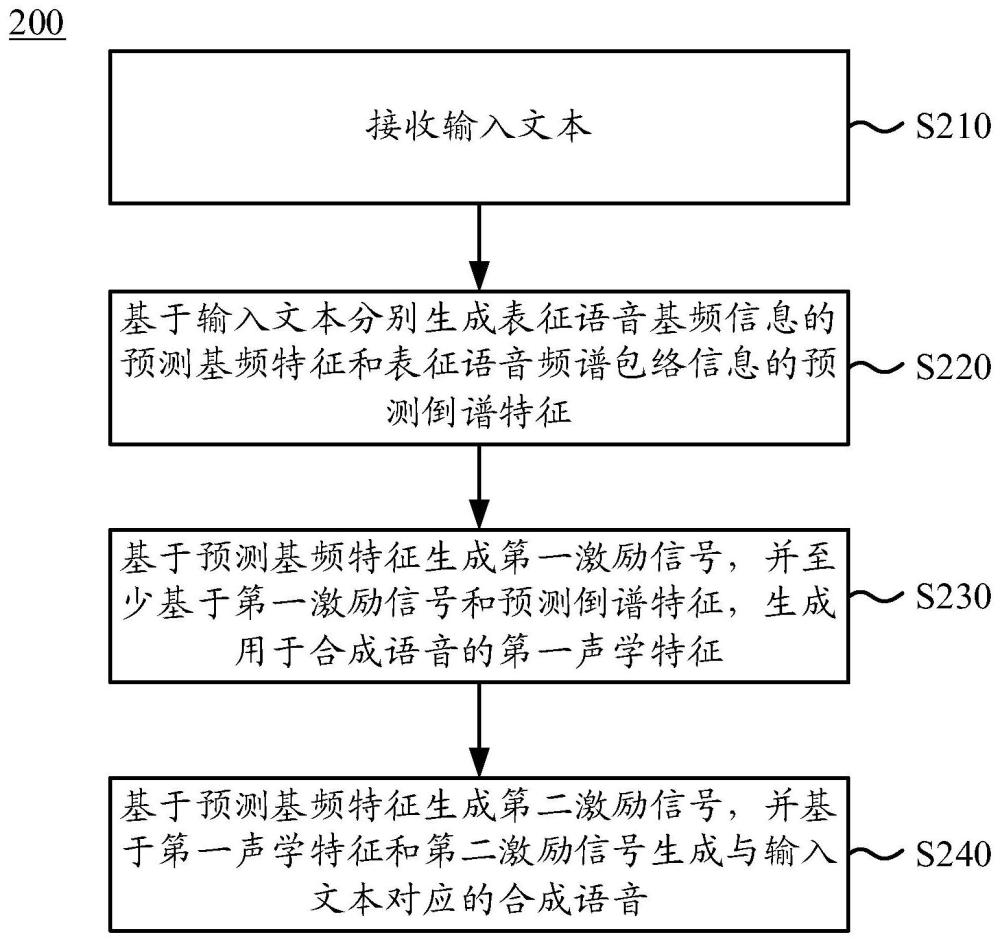
2、根据本公开实施例的一个方面,提供了一种利用语音合成系统的语音合成方法,所述方法包括:接收输入文本;基于所述输入文本分别生成表征语音基频信息的预测基频特征和表征语音频谱包络信息的预测倒谱特征;基于所述预测基频特征生成第一激励信号,并至少基于所述第一激励信号和所述预测倒谱特征,生成用于合成语音的第一声学特征;以及基于所述预测基频特征生成第二激励信号,并基于所述第一声学特征和所述第二激励信号生成与所述输入文本对应的合成语音。
3、根据本公开实施例的示例,其中,所述第一激励信号和所述第二激励信号是由非周期性分量和基于所述预测基频特征生成的周期性分量组成的。
4、根据本公开实施例的示例,其中,基于所述第一声学特征和所述第二激励信号生成与所述输入文本对应的合成语音包括:对所述第一声学特征进行逐层上采样以生成多个上采样的第一声学特征;对所述第二激励信号进行逐层下采样以生成多个下采样的第二激励信号;将所述多个上采样的第一声学特征中的每个上采样的第一声学特征与所述多个下采样的第二激励信号中对应的下采样的第二激励信号进行拼接,并基于拼接结果生成与所述输入文本对应的所述合成语音。
5、根据本公开实施例的示例,所述语音合成方法还包括基于所述输入文本生成所述输入文本中的每个音素的预测时长特征,并且其中,至少基于所述第一激励信号和所述预测倒谱特征,生成用于合成语音的第一声学特征包括:基于所述预测时长特征、所述第一激励信号和所述预测倒谱特征,生成用于合成语音的第一声学特征。
6、根据本公开实施例的示例,其中,所述语音合成系统是通过以下方法训练的:获取多个训练语音及对应的多个训练输入文本,对于所述多个训练输入文本中的每个训练输入文本:基于所述训练输入文本分别生成训练基频特征和训练倒谱特征;基于从与所述训练输入文本对应的训练语音中提取的真实基频特征生成第一训练激励信号,并至少基于所述第一训练激励信号和所述训练倒谱特征,生成第一训练声学特征;基于所述真实基频特征和从所述训练语音中提取的真实倒谱特征生成第二训练声学特征;基于所述真实基频特征生成第二训练激励信号,并基于所述第二训练声学特征和所述第二训练激励信号生成与所述训练输入文本对应的训练合成语音;以及至少基于所述训练语音和所述训练合成语音确定损失函数,并利用所述损失函数对所述语音合成系统进行训练。
7、根据本公开实施例的示例,其中,所述损失函数包括基于所述真实基频特征、所述训练基频特征、所述真实倒谱特征和所述训练倒谱特征确定的预测损失函数。
8、根据本公开实施例的示例,其中,所述损失函数包括基于所述第一训练声学特征和所述第二训练声学特征确定的声学特征损失函数。
9、根据本公开实施例的示例,其中,所述损失函数包括重建基频损失函数和重建倒谱损失函数,所述重建基频损失函数是基于所述真实基频特征和从所述训练合成语音中提取的重建基频特征确定的,并且,所述重建倒谱损失函数是基于所述真实倒谱特征和从所述训练合成语音中提取的重建倒谱特征确定的。
10、根据本公开实施例的示例,其中,所述语音合成系统还包括判别器,并且所述损失函数还包括生成器损失函数和判别器损失函数,所述生成器损失函数包括基于所述判别器对所述训练合成语音的判别结果的对抗损失分量和基于所述判别器分别对所述训练合成语音和所述训练语音的判别结果的特征匹配损失分量,并且所述判别器损失函数包括基于所述判别器分别对所述训练合成语音和所述训练语音的判别结果的对抗损失分量。
11、根据本公开实施例的示例,其中,所述语音合成方法还包括基于所述训练输入文本生成所述训练输入文本中的每个音素的训练时长,并且所述损失函数还包括基于所述训练语音中的音素的真实时长和所述训练时长确定的时长损失函数。
12、根据本公开实施例的示例,其中所述输入文本为乐谱,并且所述合成语音为合成歌唱语音。
13、根据本公开实施例的另一方面,提供了一种语音合成装置,包括:接收单元,被配置为接收输入文本;编码单元,被配置为基于所述输入文本分别生成表征语音基频信息的预测基频特征和表征语音频谱包络信息的预测倒谱特征,基于所述预测基频特征生成第一激励信号,以及至少基于所述第一激励信号和所述预测倒谱特征,生成用于合成语音的第一声学特征;以及解码单元,被配置为基于所述预测基频特征生成第二激励信号,并基于所述第一声学特征和所述第二激励信号生成与所述输入文本对应的合成语音。
14、根据本公开实施例的另一方面,提供了一种语音合成设备,包括:一个或多个处理器;以及一个或多个存储器,其中所述存储器中存储有计算机可读指令,所述计算机可读指令在由所述一个或多个处理器运行时,使得所述一个或多个处理器执行上述各个方面中所述的方法。
15、根据本公开实施例的另一方面,提供了一种计算机可读存储介质,其上存储有计算机可读指令,所述计算机可读指令在被处理器执行时,使得所述处理器执行如本公开上述各个方面中任一项所述的方法。
16、根据本公开实施例的另一方面,提供了一种计算机程序产品,其中包括计算机可读指令,所述计算机可读指令在被处理器执行时,使得所述处理器执行如本公开上述各个方面中任一项所述的方法。
17、利用根据本公开上述各个方面的语音合成方法、语音合成装置和设备、计算机可读存储介质以及计算机程序产品,能够对语音的音高信息和频谱包络信息分别进行建模,以分别反映声带和声道的特征,从而更好地模拟人类语音发音机制,提高了合成语音的整体质量和自然度,其尤其适用于歌唱语音合成,能够更精确地控制合成歌声中的音高和音调。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22112.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表