基于帧级别情感状态对齐的语音情感识别方法和系统
- 国知局
- 2024-06-21 11:32:36
本发明涉及语音情感识别,尤其涉及一种基于帧级别情感状态对齐的语音情感识别方法和系统。
背景技术:
1、语音情感识别是人机交互系统的重要组成部分,它的功能是识别当前说话人在人机交互过程中语音所包含的情感状态。在人机交互中,主要有两个方法让机器理解人类的情感。第一种是将人的说话内容通过语音识别系统先转录为文本,再通过自然语言处理技术进行文本层面的语意情感分析。但是文本表现出来的内容很多情况下和语音表达出来的真实情感是不一致的,例如生气的时候说出的“好的”,其实说话人是处在生气状态的,但是文本语意中的“好的”,会被机器理解为人类同意或赞成它的反馈。这样整个交互体验就会很差。第二种就是引入语音情感识别,可以让机器直接通过语音情感识别说话人的情感状态,再结合文本语意的内容,可以减少机器对用户意图的误解,提高人机交互体验。所以说语音情感识别是智能感知体必不可少的组成部分。
2、语音情感识别技术在近十年取得了飞速的发展。早期的语音情感识别系统由高维的手工语音特征和机器学习算法构成,常用机器学习算法有支持向量机、随机森林和隐马尔可夫等。但这些方法性能低,鲁棒性差。这是因为手工特征的维度过高容易过拟合并且在提取手工特征时会有信息损失,其次是机器学习算法不能或不擅长建模帧级别特征,导致其性能低。因为情感信息具有长时性,从帧级别上建模更适合此项任务。
3、目前所有标注的语音情感数据都是只有句子级别的标签,没有帧级别的情感标注。因为将主观的情感标注到帧级别成本太高,并且非常耗时。所以目前所有的语音情感识别系统都是基于句子级别标签实现的。但是一条语音中并不是所有的帧的情感状态都与这条语音的句子标签一致,这会出现与句子级别情感标签无关的帧会干扰模型识别这条语音真正的情感标签的现象,从而导致语音情感识别模型性能差。
4、举个容易理解的例子,假设一条语音的情感标签是“开心”并且它共有100帧,其中50帧是“开心”,50帧是其他情感,这时候就会给模型识别真实情感造成困扰。因为前提是我们假设50%的语音是“开心”,但是模型并不知道有50%的语音表示是开心,在学习的过程中没有帧级别标签的引导,在只有50%的概率是“开心”的情况下模型很容易出现误判。
技术实现思路
1、鉴于此,本发明实施例提供了一种基于帧级别情感状态对齐的语音情感识别方法和系统,以消除或改善现有技术中存在的一个或更多个缺陷。
2、本发明的一个方面提供了一种基于帧级别情感状态对齐的语音情感识别方法,该方法包括以下步骤:
3、利用预训练的语音情感识别模型对输入的语音数据进行语音情感识别,得到句子级别语音情感识别结果;
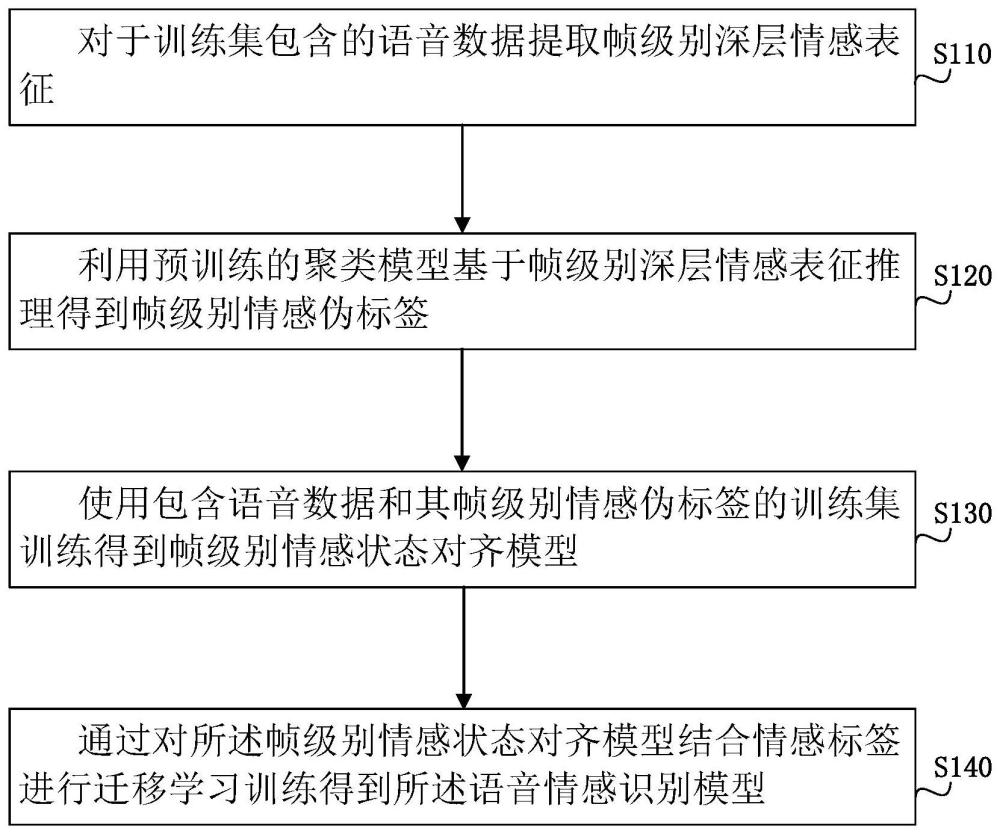
4、其中,在所述语音情感识别模型的预训练过程中,对于训练集包含的语音数据提取帧级别深层情感表征,利用预训练的聚类模型基于帧级别深层情感表征推理得到帧级别情感伪标签,使用包含语音数据和其帧级别情感伪标签的训练集训练得到帧级别情感状态对齐模型,通过对所述帧级别情感状态对齐模型结合情感标签进行迁移学习训练得到所述语音情感识别模型。
5、在本发明的一些实施例中,该方法还包括预训练得到语音情感识别模型的步骤,具体包括:
6、对于训练集包含的语音数据提取帧级别深层情感表征;
7、利用预训练的聚类模型基于帧级别深层情感表征推理得到帧级别情感伪标签;
8、使用包含语音数据和其帧级别情感伪标签的训练集训练得到帧级别情感状态对齐模型;
9、通过对所述帧级别情感状态对齐模型结合情感标签进行迁移学习训练得到所述语音情感识别模型。
10、在本发明的一些实施例中,该方法还包括:
11、对训练集包含的语音数据预先进行重采样和归一化处理。
12、在本发明的一些实施例中,所述对于训练集包含的语音数据提取帧级别深层情感表征的步骤包括:
13、输入语音数据到用于语音情感识别的预训练模型中,所述预训练模型包含的预设数量的transformer层依次对语音数据进行特征提取,提取得到语音数据的帧级别深层情感表征。
14、在本发明的一些实施例中,该方法还包括预先训练基于帧级别深层情感表征得到帧级别情感伪标签的聚类模型步骤,包括:
15、预设聚类模型的聚类数量;
16、输入用于训练聚类模型的包含帧级别深层情感表征的训练集,并进行聚类模型训练。
17、在本发明的一些实施例中,所述使用包含语音数据和其帧级别情感伪标签的训练集训练得到帧级别情感状态对齐模型的步骤,包括:
18、将包含语音数据和其帧级别情感伪标签的训练集输入到预训练模型中;
19、所述预训练模型基于mlm预训练方法通过训练集进行迭代训练,使得训练完成的帧级别情感状态对齐模型能够对齐帧级别情感伪标签和帧级别深层情感表征。
20、在本发明的一些实施例中,训练集在经过预训练模型处理后经过标签embedding层、全连接层和softmax层。
21、在本发明的一些实施例中,所述通过对所述帧级别情感状态对齐模型结合情感标签进行迁移学习训练得到所述语音情感识别模型的步骤,包括:
22、在所述帧级别情感对齐模型上添加一层注意力机制层,所述注意力机制的类型包含自注意力机制、加性注意力机制和硬注意力机制中的任一种;
23、使用包含语音数据和情感标签的训练集对添加了注意力机制层的帧级别情感对齐模型进行迁移学习训练,获得训练完成的语音情感识别模型。
24、本发明的另一方面提供了一种基于帧级别情感状态对齐的语音情感识别系统,包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该系统实现如上实施例中任一项所述方法的步骤。
25、本发明的另一方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上实施例中任一项所述方法的步骤。
26、本发明的基于帧级别情感状态对齐的语音情感识别方法和系统,能够基于预训练的帧级别情感状态对齐模型对齐深层情感表征和伪标签,又通过语音情感识别模型基于帧级别情感伪标签得到句子级别语音情感识别结果,一方面,基于帧级别情感状态对齐模型迁移学习训练得到的语音情感识别模型,能够细粒度的学习情感特征,弱化情感不一致的语音帧的干扰,另一方面,避免了帧级别情感标签标注而采用帧级别情感状态对齐的策略,也避免了成本的大幅提升。
27、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
28、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
技术特征:1.一种基于帧级别情感状态对齐的语音情感识别方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,该方法还包括预训练得到语音情感识别模型的步骤,具体包括:
3.根据权利要求2所述的方法,其特征在于,该方法还包括:
4.根据权利要求2所述的方法,其特征在于,所述对于训练集包含的语音数据提取帧级别深层情感表征的步骤包括:
5.根据权利要求2所述的方法,其特征在于,该方法还包括预先训练基于帧级别深层情感表征得到帧级别情感伪标签的聚类模型步骤,包括:
6.根据权利要求2所述的方法,其特征在于,所述使用包含语音数据和其帧级别情感伪标签的训练集训练得到帧级别情感状态对齐模型的步骤,包括:
7.根据权利要求6所述的方法,其特征在于,训练集在经过预训练模型处理后经过标签embedding层、全连接层和softmax层。
8.根据权利要求2所述的方法,其特征在于,所述通过对所述帧级别情感状态对齐模型结合情感标签进行迁移学习训练得到所述语音情感识别模型的步骤,包括:
9.一种基于帧级别情感状态对齐的语音情感识别系统,包括处理器和存储器,其特征在于,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该系统实现如权利要求1至8中任一项所述方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1至8中任一项所述方法的步骤。
技术总结本发明提供一种基于帧级别情感状态对齐的语音情感识别方法和系统,所述方法包括:利用预训练的语音情感识别模型对输入的语音数据进行语音情感识别,得到句子级别语音情感识别结果。其中,在所述语音情感识别模型的预训练过程中,对于训练集包含的语音数据提取帧级别深层情感表征,利用预训练的聚类模型基于帧级别深层情感表征推理得到帧级别情感伪标签,使用包含语音数据和其帧级别情感伪标签的训练集训练得到帧级别情感状态对齐模型,通过对所述帧级别情感状态对齐模型结合情感标签进行迁移学习训练得到所述语音情感识别模型。本发明能够解决语音样本中不一致帧的干扰,并避免成本昂贵的问题。技术研发人员:李雅,李启飞,高迎明,王聪受保护的技术使用者:北京邮电大学技术研发日:技术公布日:2024/3/5本文地址:https://www.jishuxx.com/zhuanli/20240618/22124.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。