稳健的直接语音到语音翻译的制作方法
- 国知局
- 2024-06-21 11:32:31
本公开涉及稳健的直接语音到语音翻译。
背景技术:
1、语音到语音翻译(s2st)对于分解不共享共同语言的人之间的通信障碍非常有益。常规地,s2st系统由三个组件的级联组成:自动语音识别(asr);文本到文本机器翻译(mt)、以及文本到语音(tts)合成。最近,直接语音到文本翻译(st)的进步已经超过了asr和mt的级联,从而使st和tts作为s2st的两个组件级联是可行的。
技术实现思路
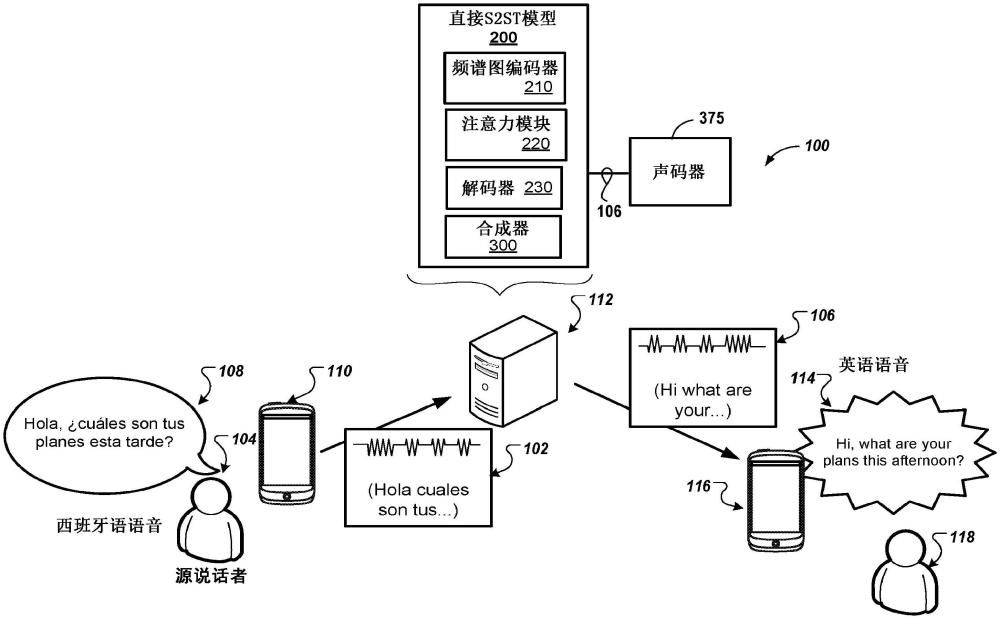
1、本公开的一个方面提供了一种直接语音到语音翻译(s2st)模型,其包括编码器,该编码器被配置成接收与由源说话者以第一语言说出的话语相对应的输入语音表示并且将输入语音表示编码为隐藏特征表示。s2st模型还包括注意力模块,该注意力模块被配置成生成注意到(attend to)由编码器编码的隐藏表示的上下文向量。s2st模型还包括解码器,该解码器被配置成接收由注意力模块生成的上下文向量并且预测以第二不同语言的与话语的翻译相对应的音素表示。s2st模型还包括合成器,该合成器被配置成接收上下文向量和音素表示并且生成以不同的第二语言说出的与话语的翻译相对应的经翻译的合成语音表示。
2、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,编码器包括conformer块的堆叠。在其它实施方式中,编码器包括transformer块或轻量卷积块中的一个的堆叠。在一些示例中,合成器包括持续时间模型网络,该持续时间模型网络被配置成预测由音素表示表示的音素序列中的每个音素的持续时间。在这些示例中,合成器可以被配置成通过基于每个音素的预测持续时间对音素序列进行上采样来生成经翻译的合成语音表示。经翻译的合成语音表示可以被配置成源说话者的说话风格/韵律(prosody)。
3、在一些实施方式中,s2st模型是在并行源语言话语和目标语言话语对上进行训练的,每个对包括以源话语说出的话音。在这些实施方式中,源语言话语或目标语言话语中的至少一个包括由经训练以生成以源话语的话音的合成语音的文本到语音模型合成的语音。在一些示例中,s2st模块进一步包括声码器,该声码器被配置成接收经翻译的合成语音表示并且将经翻译的合成语音表示合成到经翻译的合成语音表示的可听输出。可选地,音素表示可以包括与经翻译的合成语音表示相对应的音素序列中的可能音素的概率分布。
4、本公开的另一方面提供了一种计算机实现的方法,该方法在数据处理硬件上施行时使数据处理硬件执行用于直接语音到语音翻译的操作。操作包括接收与由源说话者以第一语言说出的话语相对应的输入语音表示作为对直接语音到语音翻译(s2st)模型的输入。操作还包括由s2st模型的编码器将输入语音表示编码为隐藏特征表示。操作还包括由s2st模型的解码器生成注意到由编码器编码的隐藏特征表示的上下文向量。操作还包括在s2st模型的解码器处接收由注意力模块生成的上下文向量。操作还包括由解码器预测以第二不同语言的与话语的翻译相对应的音素表示。操作还包括在s2st模型的合成器处接收上下文向量和音素表示。操作还包括由合成器生成以不同的第二语言说出的与话语的翻译相对应的经翻译的合成语音表示。
5、本公开的实施方式可以包括以下可选特征中的一个或多个。在一些实施方式中,编码器包括conformer块的堆叠。在其它实施方式中,编码器包括transformer块或轻量卷积块中的一个的堆叠。在一些示例中,合成器包括持续时间模型网络,该持续时间模型网络被配置成预测由音素表示表示的音素序列中的每个音素的持续时间。在这些示例中,生成经翻译的合成语音表示可以包括基于每个音素的预测持续时间对音素序列进行上采样。
6、经翻译的合成语音表示可以被配置成源说话者的说话风格/韵律。在一些实施方式中,s2st模型是在并行源语言话语和目标语言话语对上进行训练的,每个对包括以源话语说出的话音。在这些实施方式中,源语言话语或目标语言话语中的至少一个可以包括由经训练以生成以源话语的话音的合成语音的文本到语音模型合成的语音。在一些实例中,操作进一步包括在s2st模型的声码器处接收经翻译的合成话音表示并且通过声码器将经翻译的合成话音表示合成到经翻译的合成话音表示的可听输出中。可选地,音素表示可以包括与经翻译的合成语音表示相对应的音素序列中的可能音素的概率分布。
7、在附图和以下描述中阐述了本公开的一个或多个实施方式的细节。根据说明书和附图以及权利要求,其他方面、特征和优点将是显而易见的。
技术特征:1.一种直接语音到语音翻译(s2st)模型(200),包括:
2.根据权利要求1所述的s2st模型(200),其中,所述编码器(210)包括conformer块(400)的堆叠。
3.根据权利要求1或2所述的s2st模型(200),其中,所述编码器(210)包括transformer块或轻量卷积块中的一个的堆叠。
4.根据权利要求1至3中的任一项所述的s2st模型(200),其中,所述合成器(300)包括持续时间模型网络(310),所述持续时间模型网络被配置成预测由所述音素表示(235)表示的音素序列中的每个音素的持续时间(315)。
5.根据权利要求4所述的s2st模型(200),其中,所述合成器(300)被配置成通过基于每个音素的预测持续时间(315)对所述音素序列进行上采样来生成所述经翻译的合成语音表示(102)。
6.根据权利要求1至5中的任一项所述的s2st模型(200),其中,所述经翻译的合成语音表示(102)被配置成所述源说话者(104)的说话风格/韵律。
7.根据权利要求1至6中的任一项所述的s2st模型(200),其中,所述s2st模型(200)是在并行源语言话语和目标语言话语对上进行训练的,每个对包括以源话语说出的话音。
8.根据权利要求7所述的s2st模型(200),其中,所述源语言话语(108)或所述目标语言话语中的至少一个包括由文本到语音模型合成的语音,所述文本到语音模型被训练以生成以所述源话语(108)的所述话音的合成语音。
9.根据权利要求1至8中的任一项所述的s2st模型(200),其中,声码器(375)被配置成:
10.根据权利要求1至9中的任一项所述的s2st模型(200),其中,所述音素表示(235)包括与所述经翻译的合成语音表示(355)相对应的音素序列中的可能音素的概率分布。
11.一种计算机实现的方法(500),当在数据处理硬件上施行时,所述计算机实现的方法(500)使所述数据处理硬件(610)执行包括以下各项的操作:
12.根据权利要求11所述的计算机实现的方法(500),其中,所述编码器(210)包括conformer块(400)的堆叠。
13.根据权利要求11或12所述的计算机实现的方法(500),其中,所述编码器(210)包括transformer块或轻量卷积块中的一个的堆叠。
14.根据权利要求11至13中的任一项所述的计算机实现的方法(500),其中,所述合成器(300)包括持续时间模型网络(310),所述持续时间模型网络被配置成预测由所述音素表示(235)表示的音素序列中的每个音素的持续时间(315)。
15.根据权利要求14所述的计算机实现的方法(500),其中,生成所述经翻译的合成语音表示(355)包括基于每个音素的预测持续时间(315)对所述音素序列进行上采样。
16.根据权利要求11至15中的任一项所述的计算机实现的方法(500),其中,所述经翻译的合成语音表示(355)被配置成所述源说话者(104)的说话风格/韵律。
17.根据权利要求11至16中的任一项所述的计算机实现的方法(500),其中,所述s2st模型(200)是在并行源语言话语和目标语言话语对上进行训练的,每个对包括以源话语说出的话音。
18.根据权利要求17所述的计算机实现的方法(500),其中,所述源语言话语(108)或所述目标语言话语中的至少一个包括由文本到语音模型合成的语音,所述文本到语音模型被训练以生成以所述源话语(108)的所述话音的合成语音。
19.根据权利要求11至18中的任一项所述的计算机实现的方法(500),其中,所述操作进一步包括:
20.根据权利要求11至19中的任一项所述的计算机实现的方法(500),其中,所述音素表示(235)包括与所述经翻译的合成语音表示(355)相对应的音素序列中的可能音素的概率分布。
技术总结一种直接语音到语音翻译(S2ST)模型(200)包括编码器(210),该编码器(210)被配置成接收由源说话者(104)以第一语言说出的话语(108)的输入语音表示(102)并且将输入语音表示编码成隐藏特征表示(215)。S2ST模型还包括被配置成生成注意到被编码的隐藏表示的上下文向量(225)的注意力模块(220)。S2ST模型还包括解码器(230),该解码器(230)被配置成接收由注意力模块生成的上下文向量并且预测以第二不同语言的与话语的翻译相对应的音素表示(235)。S2ST模型还包括合成器(300),该合成器(300)被配置成接收上下文向量和音素表示并且生成以不同的第二语言说出的与话语的翻译相对应的经翻译的合成语音表示(355)。技术研发人员:贾晔,米歇尔·塔德莫尔·拉曼诺维奇,泰尔·雷米兹,罗伊·波梅兰茨受保护的技术使用者:谷歌有限责任公司技术研发日:技术公布日:2024/3/4本文地址:https://www.jishuxx.com/zhuanli/20240618/22116.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表