一种基于D-CNN和KNN技术的环境声音分类识别方法与流程
- 国知局
- 2024-06-21 11:32:49
本发明涉及声纹数据识别,具体来说是一种基于d-cnn和knn技术的环境声音分类识别方法。
背景技术:
1、关于环境声音分类(esc)技术的研究相对语音识别技术起步较晚,尽管已经取得了一定的研究成果,并为一些相关领域的应用提供了许多机会,但仍然面临着诸多挑战。
2、近几年来,深度学习在解决语音识别、说话人识别与音乐识别等声学相关领域的问题上都展现出了极大的优势。esc任务虽与语音识别技术存在一定的差距,但二者是息息相关的。
3、因此,深度学习方法应用到esc任务上也是非常适宜的,并且能够更好地解决esc技术中面临的一些问题,但当前卷积神经网络在esc任务上存在难以扩展模型深度问题,此外,esc任务的标记数据相对稀缺也是卷积神经网络难以在较简单模型上改进的重要原因,虽然近年来已经发布了一些新的数据集,但它们仍然比可供研究的数据集要小得多,制约了esc技术的发展。综上所述,esc技术隐藏着巨大的发展潜力,如何提高分类的准确率和效率,是该领域内亟待解决的问题,对于改善人们的生活质量具有极其深远的研究意义。
技术实现思路
1、本发明的目的是为了解决现有技术中环境声音分类(esc)特征提取困难、识别率低、鲁棒性差的缺陷,提供一种基于d-cnn和knn技术的环境声音分类识别方法来解决上述问题。
2、为了实现上述目的,本发明的技术方案如下:
3、一种基于d-cnn和knn技术的环境声音分类识别方法,包括以下步骤:
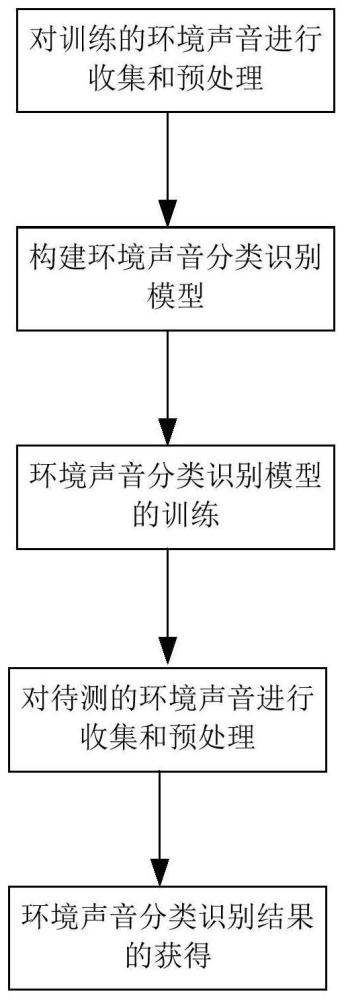
4、11)对训练的环境声音进行收集和预处理:收集若干时长环境声音音频作为训练数据集,对所有环境声音音频进行分段并转化为语谱图像,对所有语谱图像进行大小归一化处理,将其处理为256×256像素,得到若干个训练样本;
5、12)构建环境声音分类识别模型:基于d-cnn网络模型和随机子空间集成knn模型,构造出环境声音分类识别模型;
6、13)环境声音分类识别模型的训练:将若干个训练样本输入环境声音分类识别模型进行训练;
7、14)对待测的环境声音进行收集和预处理:对所有待测的环境声音音频进行分段并转化为语谱图像,并对待测的环境声音语谱图像按256×256像素进行归一化处理,得到测试样本;
8、15)环境声音分类识别结果的获得:将测试样本输入经过训练后的环境声音分类识别模型,进行环境声音的自动分类识别。
9、所述构建环境声音分类识别模型包括以下步骤:
10、21)设定环境声音分类识别模型包括d-cnn网络模型和随机子空间集成knn模型,d-cnn网络模型用于输出特征向量,随机子空间集成knn模型用于利用特征向量输出环境声音类别;
11、22)构造d-cnn网络模型:
12、设置网络层数为13层,利用pytorch框架进行网络模型的训练,输入为归一化后的训练样本,输出为每层卷积层的max-pool的全连接输出,将每层卷积层的max-pool的全连接输出进行累加,得到最终的特征向量βn,其公式如下:
13、
14、其中,表示具有多个输入的输出,βi为第i层的特征向量输出分支;
15、23)构造随机子空间集成knn模型作为分类器:
16、将最终的特征向量βn作为随机子空间集成knn模型的输入,经过随机子空间集成knn模型输出环境声音类别。
17、所述环境声音分类识别模型的训练包括以下步骤:
18、31)设定d-cnn网络模型中,将过滤器和偏差初始化设置为初始训练值,使用标准正态分布初始化多尺度全连接层的权重;
19、32)设置d-cnn网络模型的13层网络层数中:w1…wk,wi为d-cnn第1-k层的参数,k=13;
20、设(x(i),y(i))是训练数据,x(i)为第i幅输入图像,y(i)为第i幅输入图像的类别,最小化目标函数,目标函数公式如下:
21、
22、33)将归一化后的训练样本作为d-cnn网络模型的输入,设置卷积核大小为3×3像素,利用卷积核对图像进行卷积操作,加上偏置参数,得到13层的卷积层图像αi;
23、34)每层的卷积层图像αi均采用线性修正单元relu作为激活函数,公式如下:
24、g(z)=max(0,z);
25、其中,z为输入的特征向量,max(0,z)表示选择0和z中的较大值;
26、35)线性修正单元在d-cnn网络模型中的计算,
27、d-cnn网络模型将每个线性修正单元链接到最大池化层max-pool,再链接到l2归一化层进行归一化,最后将归一化结果送到产生n个输出的全连接层,进行全连接输出并作为每层的输出特征向量。
28、所述构造d-cnn网络模型包括以下步骤:
29、41)设置网络层数为13层,其中包含3个卷积层、3个最大池化或3个l2归一化及4个全连接层组成;
30、42)设定每个卷积层包含一个最大池化层、一个l2归一化层以及一个全连接层,卷积核大小设置为3×3,用以提取输入的特征;最大池化层用于减小特征图的空间维度,提取最显著的特征并保留主要信息,降低计算量;l2归一化层通过对权重进行归一化,即缩放权重向量使其l2范数等于1,有助于防止权重过大;全连接层用于将l2归一化层归一化后的结果映射到最终的输出空间;
31、43)最后一个全连接层在输出层之前,与上一个全连接层相连,用于加深网络深度和模型的复杂性,使其适应多种类的数据模式。
32、所述构造随机子空间集成knn模型作为分类器的方法为:将训练数据集细分为随机子空间,利用由随机子空间构成的训练集上的测试样本进行欧氏距离和切比雪夫距离的计算;根据最近邻的个数k,由距离和多数投票确定最合适的子空间类成员;然后,将每个子空间集合所带来的类隶属关系组合到一个类向量d中,以d中平均分最高的方式进行分类;
33、具体步骤如下:
34、51)从训练数据集中选择一个大小为m的随机集,不做任何改变;
35、52)只使用选定的预测器训练一个knn学习者(b);
36、53)重复51)和52)步骤,直到有l名knn学习者;
37、54)平均knn学习者的预测值构成;
38、55)对平均值最高的测试数据集进行分类。
39、所述线性修正单元在d-cnn网络模型中的计算包括以下步骤:
40、61)将线性修正单元应用在dag模型上,
41、相对于第i个线性修正单元的输入,z的梯度表示为
42、
43、其中,为第j个输出分支,z为最终输出,为最终输出z相对于每层节点的梯度;
44、62)恢复标准反向传播z的梯度方程,
45、设置c=1,单个反馈信号到达线性修正单元i,乘以局部梯度并向下传递到下一层;
46、多个支路信号均从每个分支j到达每个分支j都乘以分支j特定的梯度并且它们的总和向下传递到下一层;
47、63)得到输出为i个β(j)。
48、有益效果
49、本发明的一种基于d-cnn和knn技术的环境声音分类识别方法,与现有技术相比构造的深度卷积神经网络具有多个隐含层,能够自动提取特征,同时拥有比浅层网络更加优异的特征表达能力,从多空间角度描述图像信息,对于不同分辨率的图像能够从多个尺度进行特征提取,且通过随机子空间集成knn器进行分类预测。
50、本发明不仅解决了环境声音数据特征提取困难,提高了环境声音识别的准确率,而且增强了环境声音分类识别算法的鲁棒性,达到了实际应用水平。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22149.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。