基于DW-Metaformer轻量级神经网络模型的说话人识别方法
- 国知局
- 2024-06-21 11:33:21
本发明属于声纹识别,具体涉及一种基于dw-metaformer轻量级神经网络模型的说话人识别方法。
背景技术:
1、说话人识别,又称声纹识别,其研究目标是根据每个说话人的独特发音进行身份认证。说话人识别作为生物识别中的一种远程认证方式,具有方便性、准确性、经济性等优势,引起了社会的广泛关注,在取证、监视、访问控制和家用电子产品中都有应用。
2、近年来,随着深度学习的发展,深度学习(deep learning)和深度神经网络(dnn)在不同领域中得到了成功的应用,语音识别技术取得了极大的发展,但说话人识别技术仍然是一项具有挑战性的任务。现代说话人识别很大程度上依赖于基于低频倒谱系数(mfcc)特征训练的深度神经网络,mfcc是由特定时频表示的功率谱获得的短期傅里叶变换(stft),在提取中具有方差较大以及部分共振峰相关信息缺失的问题,直接应用于dnn模型中,参数中包含大量的语义信息会淹没了说话人的个性信息,无法获得更好的说话人识别性能。
3、因此,基于现实应用的需求,寻找一种能够代替mfcc特征提取、更好地代表说话人个性信息的特征参数,同时实现说话人识别模型的轻量化,成为亟待解决的问题。
技术实现思路
1、鉴于此,本发明的目的在于提供一种基于dw-metaformer轻量级神经网络模型的说话人识别方法,以实现更好的说话人识别性能。
2、本发明的技术方案是:一种基于dw-metaformer轻量级神经网络模型的说话人识别方法,包括如下步骤:
3、s1:采集语音信号,并对所述语音信号进行预处理操作;
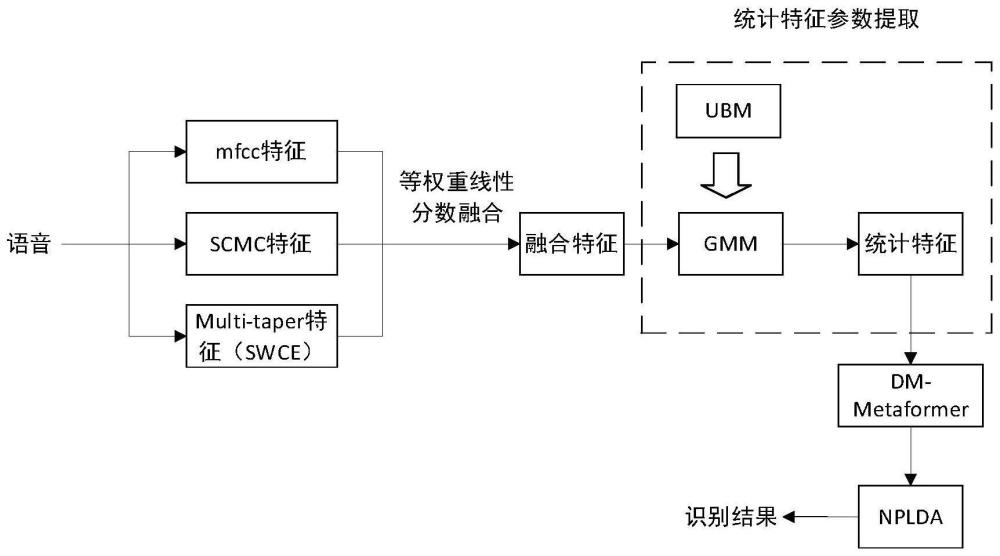
4、s2:针对预处理后的语音信号,提取短期幅度功率谱的语音特征并进行融合,其中,提取的语音特征包括梅尔倒谱系数特征、谱质心幅度系数特征和多锥谱估计特征;
5、s3:构建gmm模型,并输入所述融合特征,获取gmm统计特征;
6、s4:构建dw-metaformer轻量级神经网络模型,输入所述gmm统计特征,使用aam-softmax损失函数训练模型参数,并进行奇异值分解处理,得到低秩化dw-metaformer训练模型;
7、s5:构建虚拟教师知识蒸馏模型,并利用所述虚拟教师知识蒸馏模型对所述低秩化dw-metaformer训练模型进行知识迁移;
8、s6:使用基于软检测的代价函数训练nplda后端模型,得到训练好的nplda后端模型;
9、s7:利用训练好的低秩化dw-metaformer模型和训练好的nplda后端模型识别待识别的语音,得到识别结果。
10、优选,s1中,所述预处理包括采样、量化、预加重处理和加窗四个部分。
11、进一步优选,s2中,所述融合使用等权重线性分数融合方式。
12、进一步优选,s3具体包括如下步骤:
13、s31:使用所述融合特征训练得到ubm模型;
14、s32:使用所述ubm模型并利用map算法构建gmm模型,获取gmm统计参数。
15、进一步优选,s4具体包括如下步骤:
16、s41:构建dw-metaformer轻量级神经网络模型,所述模型包含densenet模块、maxpoolformer模块、window-msa模块和池化全连接层;
17、其中,densenet模块由三层具有大卷积核的深度可分离卷积组成,采用densnet结构;
18、maxpoolformer模块包含两层metaformer模块,模块中使用最大池化作为池化算子替代transformer中的注意力模块;
19、window-msa模块由一层包含多头注意力的transformer构成,在transformer基础上添加了分窗处理以及去除了位置信息编码;
20、池化全连接层包含全局池化层和全连接层;
21、s42:将所述gmm统计特征输入到所述dw-metaformer轻量级神经网络模型,使用aam-softmax损失函数对所述dw-metaformer轻量级神经网络模型进行训练,得到dw-metaformer训练模型;
22、s43:对所述dw-metaformer训练模型的权值矩阵进行奇异值分解,权重矩阵由式(8)分解为式(9):
23、y=φ(wxt) (8)
24、y=φ((wawb)xt) (9)
25、式中,φ为非线性激活函数,wa和wb为w的低秩表示;
26、s44:对奇异值分解后的dw-metaformer训练模型进行调参与优化,直到收敛,得到低秩化dw-metaformer训练模型。
27、进一步优选,s5具体包括如下步骤:
28、s51:手动设计一个有百分之百正确率的tf_dw-metaformer虚拟教师模型,将aam-softmax加入交叉熵函数,输出类别的概率分布设置为:
29、
30、式中,c代表正确的标签,α为类比正确的概率,z表示总类别数,通过软知识蒸馏,pd分布通过t软化为
31、虚拟教师知识蒸馏模型总的损失函数表示为式(11),其中,h(q,p)表示原始损失函数,表示为式(12):
32、
33、h(q,p)=ce+aam (12)
34、式中,q为真实事件类别的概率分布,p为输出类别的概率分布,dkl为kl散度损失函数;
35、s52:通过学习虚拟教师知识蒸馏模型,进行知识迁移,对低秩化dw-metaformer训练模型进一步训练。
36、进一步优选,s6具体包括如下步骤:
37、s61:构建nplda后端模型:将lda的预处理步骤构造为第一仿射层,将单位长度归一化构造为非线性激活,将plda的定心和对角化构造为另一种仿射变换,计分时,使用一对x向量,一个来自记录ηe的注册者,一个来自记录ηt的测试者,与预先训练的plda模型一起计算对数似然比,得分可由式(13)计算得到,其中,q由式(14)计算得到,p由式(15)计算得到。
38、
39、
40、
41、式中,∑tot=φφt+∑,∑ac=φφt,φ表示说话人(注册者/测试者)的子空间矩阵。
42、s62:训练nplda后端模型进行说话人识别:对代表目标和非目标假设的dw-metaformer模型输出向量进行采样,将软检测代价作为代价函数,使用随机抽样的方法来训练所述nplda后端模型,损失函数为:
43、
44、式中,θ是作为模型参数时使lprimary最小化的阈值,β是一个基于应用程序的权重,定义为:
45、
46、式中,cmiss和cfa是漏报和误报的成本,ptarget是目标试验的先验概率,pmiss和pfa分别是漏报概率和误报概率,通过将θ的检测阈值应用于对数似然比计算得到;
47、和表示为:
48、
49、
50、式中,si表示第i个系统得分,ti表示第i个测试记录的基本事实标签,σ表示sigmoid函数,α表示变形因子,θ表示阈值,为可学习参数。
51、进一步优选,s7具体包括如下步骤:
52、s71:通过说话人的融合特征和gmm统计特征,使用训练好的低秩化dw-metaformer模型,进行非线性映射,得到说话人嵌入向量;
53、s72:将所述说话人嵌入向量输入到所述nplda后端模型中,使用对数似然比计算得分,获得相似程度及识别结果。
54、该基于dw-metaformer轻量级神经网络模型的说话人识别方法,通过说话人语音的mfcc、scmc、multi-taper融合特征获取gmm统计特征,使用dw-metaformer轻量级神经网络模型,用较小的计算成本,即可有效实现说话人识别,具体地,首先提取说话人语音的mfcc、scmc、multi-taper三项短期幅度功率谱特征,三项特征进行融合得到音频的声学特征,利用gmm模型获取语音的统计特征,使用dw-metaformer轻量级神经网络模型进行非线性映射,最终比对注册库对说话人进行识别。该说话人识别方法,弥补了梅尔倒谱系数(mfcc)特征部分信息的缺失和估计方差大的问题,通过更好的表示说话人的个性信息,使用更低的计算成本,更准确更高性能地实现说话人识别任务。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22212.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。