基于语义相似度对齐的声音事件检测方法、系统及存储介质
- 国知局
- 2024-06-21 11:33:30
本发明属于人工智能和数字媒体信号处理,具体涉及一种基于语义相似度对齐的声音事件检测方法、系统及存储介质。
背景技术:
1、如图1所示,声音事件检测任务指的是识别在给定的音频记录中发生的声音事件,并使各种基于人工智能的系统能够区分不同的声音事件。音频分类是声学信号处理领域的一个活跃研究课题,在安防监控、噪声控制等方面有广泛的应用。
2、最大的公开可用的声音事件数据集audioset通常用于训练声音事件检测模型。作为一个多标签分类任务,audioset上的最先进模型都是在经典的监督设置下进行训练的,采用独热标签作为优化目标,二元交叉熵作为损失函数。
3、如[1]所讨论的,这种设置存在两个问题。首先,已知audioset存在许多错误或缺失的标签,这意味着即使模型的预测是可接受的,它也不总能得到正确的引导。其次,不同类别的声音事件之间并不完全是天然互斥的,这意味着音频类别会存在相似关系(例如笑声和咯咯声)或包含关系(例如语音和男性语音)。为了解决这些问题,[2,3]采用了图卷积网络(gcn)来利用audioset的结构信息,直接对audioset中声音事件的树形结构进行建模,从而学习其中的事件包含关系。
4、然而,尽管上述方法尝试整合了audioset中事件间的层次信息,但其中的监督信息仍然仅通过one-hot标签提供,这种方法将所有声音类别视为平等,并忽略了声音事件之间的语义层次和接近关系(相似和包含关系),导致声音事件的识别检测出错。
5、例如,1.相似关系:“shout”和“yell”都是audioset中的声音事件,然而它们的区别是很难用语言明确定义的。对于人类而言,一段被标注为“shout”的音频,将其标注为“yell”也并非不可接受。
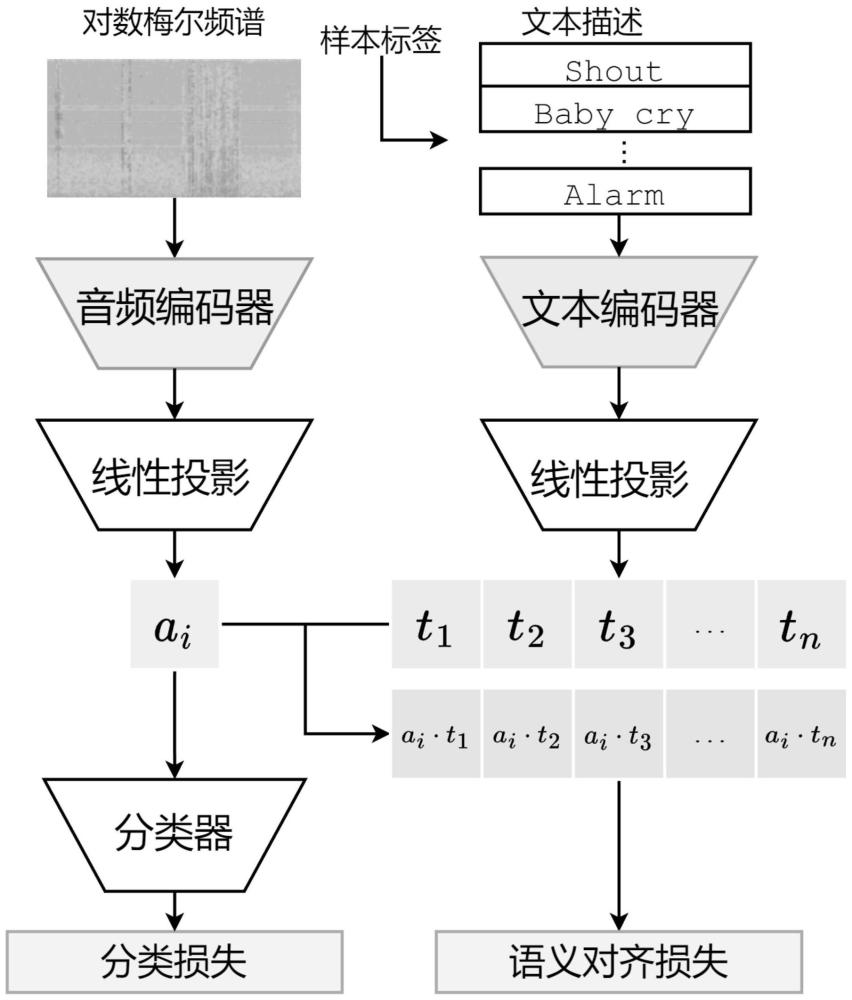
6、但现有的方法会将标签为“shout”的样本预测为“yell”——根据one-hot标签,这不仅是一项错误的预测,而且错误的程度与任何错误都一样。然而,这两个预测对于人类而言其实都是可以接受的。
7、2.包含关系:“speech”、“male speech”和“female speech”都是audioset中的声音事件。理论上来说,任意一段被标注为“male speech”或者“female speech”的音频,都应该同时属于“speech”的范畴。然而,正如[4]中所说,audioset存在大量的标注缺漏和错误。在audioset中随机选择4895个包含“speech”标签的样本,其中只有2.1%同时也包含了“male speech”或“female speech”的标签。
8、现有方法会将标签为“male speech”的样本预测为“speech”——如前所述,由于audioset标注的缺陷,这也将被判断为错误。然而,对于人类而言,这个预测只能称为不精确的预测,并不算错误。
9、引用文献:
10、[1]y.sun and s.ghaffarzadegan,“an ontology-aware framework for audioevent classification,”in icassp.ieee,2020,pp.321–325.
11、[2]c.aironi,s.cornell,e.principi,and s.squartini,“graph nodeembeddings for ontology-aware sound event classification:an evaluationstudy,”in 2022 30th european signal processing conference(eusipco).ieee,2022,pp.414–418.
12、[3]h.liu,q.kong,x.liu,x.mei,w.wang,and m.d.plumbley,“ontology-awarelearning and evaluation for audio tagging,”in proc.interspeech 2023,2023,pp.3799–3803.
13、[4]y.gong,y.-a.chung,and j.glass,“psla:improving audio tagging withpretraining,sampling,labeling,and aggregation,”ieee/acm transactions onaudio,speech,and language processing,vol.29,pp.3292–3306,2021.
技术实现思路
1、本发明是为了解决上述问题而进行的,目的在于提供基于语义相似度对齐的声音事件检测方法、系统及存储介质,能够对自然语言中天然存在着相似和包含的关系进行建模,从而将相近的类别转化为相近的文本特征,利用文本特征的远近关系来指导声音事件检测模型的训练,将one-hot标签无法表示的语义关联注入模型,提升模型对声音事件的识别和检测性能。
2、本发明为了实现上述目的,采用了以下方案:
3、<方法>
4、本发明提供了基于语义相似度对齐的声音事件检测方法,包括以下步骤:
5、步骤1,构建数据集中的各标签的文本描述;
6、对于有标签(有标注)声音事件数据集中的每个以声音事件类别作为标签的音频,均按照desc和concat两种方式中任意一种,构建每个声音事件类别的文本描述;
7、1)desc:为每个类别提供一段描述性的语言,用于说明某个标签具体指代的声音事件;
8、2)concat:将每个类别的所有父级类别的标签跟它本身的标签拼接起来;
9、步骤2,基于文本描述中的语义远近关系进行建模;
10、使用两个预训练的编码器和投影层来连接音频片段和文本描述,提取音频特征和文本特征,并分别通过两个独立的线性投影层,将音频特征和文本特征投影到同一个特征空间;
11、步骤3,模型训练和检测;
12、计算损失、训练模型,投影后的音频特征被输入到线性分类器中,以获得对所有目标类别的预测,投影音频特征除了用于计算语义对齐损失,还用于计算分类损失;并且计算投影音频特征与其正标签的投影文本特征之间的余弦相似度;模型整体优化目标是最小化分类损失,同时最大化投影音频特征与相应投影文本特征之间的平均余弦相似度;采用训练好的模型进行声音事件检测。
13、优选地,本发明提供的基于语义相似度对齐的声音事件检测方法,在步骤1中,按照concat方式构建每个声音事件类别的文本描述。
14、优选地,本发明提供的基于语义相似度对齐的声音事件检测方法,步骤2包括如下子步骤:
15、2-1,从训练数据集中随机选择一个音频样本;
16、2-2,提取音频样本的对数梅尔频谱;
17、2-3,通过音频编码器,从对数梅尔频谱中提取音频特征;
18、2-4,根据样本的真实标签,从预先定义的文本描述列表中选择对应的文本描述;对于有多个标签的样本,则选中的文本描述也为多条;
19、2-5,通过文本编码器,从一条或多条文本描述中提取一条或多条文本特征,每条文本描述提取一条文本特征;
20、2-6,通过两个独立的线性投影层,分别将2-3中提取的音频特征和2-5中提取的一条或多条文本特征投影到同一个特征空间。
21、优选地,本发明提供的基于语义相似度对齐的声音事件检测方法,步骤3包括如下子步骤:
22、3-1,计算投影音频特征和投影文本特征之间的余弦相似度;如果有多条投影文本特征,则分别计算每条投影文本特征与投影音频特征的余弦相似度;
23、3-2,所有余弦相似度的均值将用于计算语义对齐损失;模型的优化目标是最大化投影音频特征和投影文本特征的平均余弦相似度,而在模型的训练过程中,损失函数越小越好,语义对齐损失其中指代平均余弦相似度;
24、3-3,投影音频特征除了用于计算语义对齐损失,还将用于计算分类损失;经过线性分类器投影后,投影音频特征被转化为对各个类别的预测概率值,并使用二值交叉熵函数计算分类损失;
25、3-4,两个损失函数的和将作为整体的损失函数,用于训练整个模型;
26、3-5,采用训练好的模型进行声音事件检测。
27、<系统>
28、进一步,本发明还提供了能够自动实现上述<方法>的基于语义相似度对齐的声音事件检测系统,其特征在于,包括:
29、文本描述构建部,构建数据集中的各标签的文本描述;对于有标签声音事件数据集中的每个以声音事件类别作为标签的音频,均按照desc和concat两种方式中任意一种,构建每个声音事件类别的文本描述;
30、1)desc:为每个类别提供一段描述性的语言,用于说明某个标签具体指代的声音事件;
31、2)concat:将每个类别的所有父级类别的标签跟它本身的标签拼接起来;
32、语义关系建模部,基于文本描述中的语义远近关系进行建模;使用两个预训练的编码器和投影层来连接音频片段和文本描述,提取音频特征和文本特征,并分别通过两个独立的线性投影层,将音频特征和文本特征投影到同一个特征空间;
33、训练检测部,计算损失、训练模型,投影后的音频特征被输入到线性分类器中,以获得对所有目标类别的预测,投影音频特征除了用于计算语义对齐损失,还用于计算分类损失;并且计算投影音频特征与其正标签的投影文本特征之间的余弦相似度;模型整体优化目标是最小化分类损失,同时最大化投影音频特征与相应投影文本特征之间的平均余弦相似度;采用训练好的模型进行声音事件检测;
34、控制部,与文本描述构建部、语义关系建模部、训练检测部均通信相连,控制它们的运行。
35、优选地,本发明提供的基于语义相似度对齐的声音事件检测系统,还可以包括:输入显示部,与控制部通信相连,让用户输入操作指令,并根据操作指令对相应部的输入、输出和中间处理数据以文字、表格、图形、静态或动态模型方式进行显示。
36、优选地,本发明提供的基于语义相似度对齐的声音事件检测系统,在文本描述构建部中,按照concat方式构建每个声音事件类别的文本描述。
37、优选地,本发明提供的基于语义相似度对齐的声音事件检测系统,语义关系建模部采用以下步骤2-1~2-6基于文本描述中的语义远近关系进行建模:
38、2-1,从训练数据集中随机选择一个音频样本;
39、2-2,提取音频样本的对数梅尔频谱;
40、2-3,通过音频编码器,从对数梅尔频谱中提取音频特征;
41、2-4,根据样本的真实标签,从预先定义的文本描述列表中选择对应的文本描述;对于有多个标签的样本,则选中的文本描述也为多条;
42、2-5,通过文本编码器,从一条或多条文本描述中提取一条或多条文本特征,每条文本描述提取一条文本特征;
43、2-6,通过两个独立的线性投影层,分别将2-3中提取的音频特征和2-5中提取的一条或多条文本特征投影到同一个特征空间。
44、优选地,本发明提供的基于语义相似度对齐的声音事件检测系统,训练检测部采用以下步骤3-1~3-5计算训练模型进行检测:
45、3-1,计算投影音频特征和投影文本特征之间的余弦相似度;如果有多条投影文本特征,则分别计算每条投影文本特征与投影音频特征的余弦相似度;
46、3-2,所有余弦相似度的均值将用于计算语义对齐损失;模型的优化目标是最大化投影音频特征和投影文本特征的平均余弦相似度,而在模型的训练过程中,损失函数越小越好,语义对齐损失其中指代平均余弦相似度;
47、3-3,投影音频特征除了用于计算语义对齐损失,还将用于计算分类损失;经过线性分类器投影后,投影音频特征被转化为对各个类别的预测概率值,并使用二值交叉熵函数计算分类损失;
48、3-4,两个损失函数的和将作为整体的损失函数,用于训练整个模型;
49、3-5,采用训练好的模型进行声音事件检测。
50、<存储介质>
51、另外,本发明还提供了存储介质,存储有用于实现如权利要求1至4中任意一项所述的基于语义相似度对齐的声音事件检测系统方法的程序。该存储介质可以是任何包含或存储程序的有形计算机可读介质,该存储介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
52、发明的作用与效果
53、本发明中,针对每一个声音事件均存在标签、且标签标注了声音事件类别的声音事件数据集,首先通过desc或concat方式构建每个声音事件类别的文本描述,针对不同声音事件之间存在的包含关系和相似关系进行建模,将相近的类别转化为相近的文本特征,有多少个音频类别,就有多少条文本描述,相应就有多少个文本特征,分别通过两个独立的线性投影层,将音频特征和文本特征投影到同一个特征空间,然后进行相似度计算,最大化音频特征与文本特征之间的余弦相似度,利用文本特征的远近关系来指导声音事件检测模型的训练,使模型能够更好地学习音频事件的特征,将one-hot标签无法表示的语义关联注入模型,从而将音频映射到具体的类别上,使得声音事件检测模型预测结果与人类感知结果更接近,实现模型对声音事件检测性能的提升。
54、实验结果表明,基于本方法训练的声音事件检测模型的omap(ontology-awaremean average precision,本体全类平均精度)比现有技术更高(+1.8omap)。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22230.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。