一种基于边缘计算的城市声景智慧数字孪生系统的制作方法
- 国知局
- 2024-06-21 11:33:34
本发明涉及数字孪生,特别是涉及一种基于边缘计算的城市声景智慧数字孪生系统。
背景技术:
1、目前,城市环境中的声音对居民生活质量和社会经济发展有着重要影响。对于噪声问题,传统的解决方法是降低其声级,目前国内外城市规划及环境保护的标准法规均以声级限值为基础。但是,降噪往往成本过高且并不总是可行,更重要的是不一定会改善生活品质。以城市开放空间为例,研究表明,当声压级低于65~70分贝时,人们的声舒适度评价与声压级并不密切相关,而声音的种类、使用者的特点及其它非声学因素却起着重要作用。研究还发现,环境噪声的烦恼度只取决于大约30%的声能量等物理层面因素。正因为如此,许多城市有关部门尽管严格执行所有的环境噪声规范,但社区投诉仍然不断。
2、在声学领域,研究者多关注从人类感知的视角(如愉悦感、自然感、烦躁感)来评估声环境的特性。这类评估多涉及跨感官感知,特别是听觉-视觉的相互作用。视听的交互可以带来更为舒适的感知体验,并唤醒与声环境相关的感觉。然而,传统的声景静态建模方法存在缺乏智能化、实时性以及可扩展性差等问题。因此,亟需一种方案解决上述问题。
技术实现思路
1、本发明提供一种基于边缘计算的城市声景智慧数字孪生系统,解决传统的声景静态建模方法存在缺乏智能化、实时性以及可扩展性差的问题。
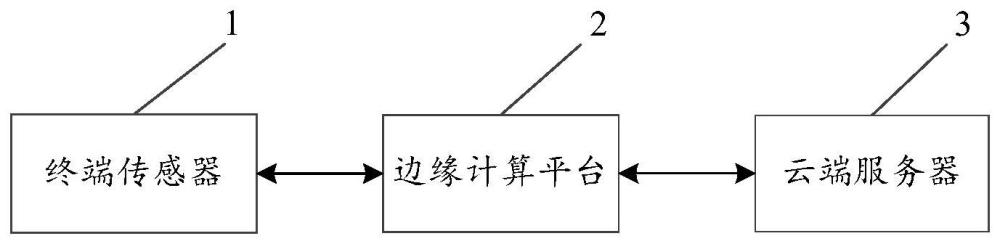
2、为解决上述技术问题,本发明提供一种基于边缘计算的城市声景智慧数字孪生系统,包括终端传感器、边缘计算平台和云端服务器;其中,
3、所述终端传感器,用于实时采集声景数据;所述声景数据至少包括声音数据和视频数据;
4、所述边缘计算平台,用于将所述声景数据输入至多模态卷积神经网络中进行分析,得到声景评价数据和声景营造音频;所述多模态卷积神经网络包括声音模态分支网络、视频模态分支网络、多模态融合层和输出层;所述声景评价数据用于反映所述声景数据采集地内声环境的优劣状态;所述声景营造音频是与所述声景数据采集地的景观相适配的音频数据;
5、所述云端服务器,用于通过数字孪生模型对所述声景营造音频进行模拟并进行可视化展示,使所述声景数据采集地内的声环境达到所述声景评价数据对应的状态。
6、进一步地,边缘计算平台,用于通过所述声音模态分支网络对所述声音数据进行处理,得到声音模态信息;通过所述视频模态分支网络对所述视频数据进行处理,得到视频模态信息;通过所述多模态融合层对所述声音模态信息和视频模态信息进行融合,得到融合模态信息;通过所述输出层对所述融合模态信息进行处理,得到声景评价数据和声景营造音频。
7、进一步地,声音模态分支网络包括第一输入层、第一卷积层、第一池化层、第一循环层、第一全连接层和第一注意力层;其中,
8、所述声音模态分支网络,用于通过所述第一输入层对所述声音数据进行特征提取,得到声音特征;通过所述第一卷积层对所述声音特征进行局部特征提取,得到声音局部特征;通过所述第一池化层对所述声音局部特征进行降维,得到声音降维特征;通过所述第一循环层处理所述声音降维特征中的时间序列信息,得到时序声音特征;通过所述第一全连接层对所述时序声音特征进行处理,得到声音模态信息;通过所述第一注意力层将所述声音模态信息的权重转移至环境自然声中。
9、进一步地,视频模态分支网络包括第二输入层、第二卷积层、第二池化层、第二循环层、第二全连接层和第二注意力层;其中,
10、所述视频模态分支网络,用于通过所述第二输入层对所述视频数据进行特征提取,得到视频特征;通过所述第二卷积层对所述视频特征进行局部特征提取,得到视频局部特征;通过所述第二池化层对所述视频特征进行全局特征提取,得到视频全局特征;通过所述第二循环层处理所述视频全局特征中的时间序列信息,得到时序视频特征;通过所述第二全连接层对所述时序视频特征进行处理,得到视频模态信息;通过所述第二注意力层将所述视频模态信息的权重转移至所述视频数据内的声音源或发声物体中。
11、进一步地,输出层包括评价模块和营造模块;所述评价模块用于预测所述融合模态信息内声音场景的类别状态,得到声景评价数据;所述营造模块用于将所述融合模态信息内具有声音源或发声物体的图像转换为频谱图,并对所述频谱图进行处理,得到声景营造音频;所述评价模块为具有预定数量神经元的第三全连接层;所述营造模块为具有预定尺寸的转换层。
12、进一步地,所述云端服务器包括服务管理系统,所述服务管理系统包括质量监控模块和请求响应模块;其中,
13、所述质量监控模块用于根据预设时间段内所述声景评价数据和声景营造音频的质量,生成模型训练控制指令,并发送至所述边缘计算平台,以使所述边缘计算平台根据所述训练控制指令生成模型训练请求;
14、所述请求响应模块,用于响应所述边缘计算平台的所述模型训练请求,并对所述多模态卷积神经网络进行再训练。
15、进一步地,所述云端服务器包括自主训练系统,所述自主训练系统包括数据获取模块和模型训练模块;其中,
16、所述数据获取模块,用于获取训练数据集,所述训练数据集中的声音数据标注有对应的声景评价数据标签,所述训练数据集中的视频数据标注有对应的标签频谱图;
17、所述模型训练模块,用于通过所述训练数据集对所述多模态卷积神经网络进行再训练;具体为:通过独热编码,使所述声景评价数据标签对应所述第三全连接层中神经元的输出;将均方误差作为损失函数,计算所述训练数据集中的视频数据对应的频谱图与所述标签频谱图之间的差异,并对所述多模态卷积神经网络中的参数进行更新,直至所述差异达到预设范围。
18、进一步地,所述边缘计算平台包括请求生成模块和数据处理模块;其中,
19、所述请求生成模块,用于根据接收的所述实时声景数据,生成数据处理请求,并发送至所述云端服务器;
20、所述数据处理模块,用于根据数据处理指令对所述实时声景数据进行预处理。
21、进一步地,所述请求响应模块,还用于响应所述边缘计算平台发送的所述数据处理请求,并生成所述数据处理指令发送至所述边缘计算平台。
22、进一步地,所述数据处理模块,用于从所述视频数据中提取视频帧,并将所述声音数据转换为时频图,使所述时频图的数量与视频帧相同。
23、与现有技术相比,本发明实施例的有益效果在于:
24、本发明提供一种基于边缘计算的城市声景智慧数字孪生系统,能够提供一种全面、准确、高效的城市声景建模和仿真解决方案。该系统基于边缘计算架构,结合传感器网络、心理声学和人工智能技术,实现了对城市声景的实时分析。通过数字孪生技术,对城市声景进行高度可视化的模拟,并为城市规划、环境保护、噪音控制等领域提供有力支持。
技术特征:1.一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,包括终端传感器、边缘计算平台和云端服务器;其中,
2.根据权利要求1所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述边缘计算平台,用于通过所述声音模态分支网络对所述声音数据进行处理,得到声音模态信息;通过所述视频模态分支网络对所述视频数据进行处理,得到视频模态信息;通过所述多模态融合层对所述声音模态信息和视频模态信息进行融合,得到融合模态信息;通过所述输出层对所述融合模态信息进行处理,得到声景评价数据和声景营造音频。
3.根据权利要求2所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述声音模态分支网络包括第一输入层、第一卷积层、第一池化层、第一循环层、第一全连接层和第一注意力层;其中,
4.根据权利要求2所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述视频模态分支网络包括第二输入层、第二卷积层、第二池化层、第二循环层、第二全连接层和第二注意力层;其中,
5.根据权利要求2所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述输出层包括评价模块和营造模块;所述评价模块用于预测所述融合模态信息内声音场景的类别状态,得到声景评价数据;所述营造模块用于将所述融合模态信息内具有声音源或发声物体的图像转换为频谱图,并对所述频谱图进行处理,得到声景营造音频;所述评价模块为具有预定数量神经元的第三全连接层;所述营造模块为具有预定尺寸的转换层。
6.根据权利要求5所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述云端服务器包括服务管理系统,所述服务管理系统包括质量监控模块和请求响应模块;其中,
7.根据权利要求6所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述云端服务器包括自主训练系统,所述自主训练系统包括数据获取模块和模型训练模块;其中,
8.根据权利要求6所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述边缘计算平台包括请求生成模块和数据处理模块;其中,
9.根据权利要求8所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述请求响应模块,还用于响应所述边缘计算平台发送的所述数据处理请求,并生成所述数据处理指令发送至所述边缘计算平台。
10.根据权利要求8所述的一种基于边缘计算的城市声景智慧数字孪生系统,其特征在于,所述数据处理模块,用于从所述视频数据中提取视频帧,并将所述声音数据转换为时频图,使所述时频图的数量与视频帧相同。
技术总结本发明公开了一种基于边缘计算的城市声景智慧数字孪生系统,包括终端传感器,用于实时采集声景数据;声景数据包括声音数据和视频数据;边缘计算平台,用于将声景数据输入至多模态卷积神经网络中进行分析,得到声景评价数据和声景营造音频;多模态卷积神经网络包括声音模态分支网络、视频模态分支网络、多模态融合层和输出层;声景评价数据用于反映声景数据采集地内声环境的优劣状态;声景营造音频是与声景数据采集地的景观相适配的音频数据;云端服务器,用于通过数字孪生模型对声景营造音频进行模拟并进行可视化展示,使声景数据采集地内的声环境达到声景评价数据对应的状态;实时模拟分析城市环境中景观声音,以支持城市规划、管理和决策。技术研发人员:郑建辉,殷艺敏,盛勇,刘思维受保护的技术使用者:广州声博士声学技术有限公司技术研发日:技术公布日:2024/3/11本文地址:https://www.jishuxx.com/zhuanli/20240618/22239.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表