一种提升语音对话系统响应速度的方法与流程
- 国知局
- 2024-06-21 11:36:14
本发明涉及一种提升语音对话系统响应速度的方法,属于人机对话。
背景技术:
1、随着人工智能技术的发展,具有语音交互的对话系统近些年随处可见,包括智能手机终端预装的语音助手、基于电话线路的对话机器人以及各种在线对话机器人等,这类语音对话机器人接收和输出的数据都是语音形式,其核心系统组件主要包括语音活动检测(voice activity detection)、语音识别(automatic speech recognition)、对话引擎、语音合成(text to speech)等,在一轮人机对话的过程中,用户说完话之后,典型的处理方式是依次执行一连串的步骤。由于处理流程太长,经过系统多个环节处理后用户才能听到机器人回应的声音,系统整体延迟往往会大幅度超过人与人对话的正常范围。
2、对用户说完到听到机器人回应的各环节用时进行分析,首先,为了保证系统的健壮性,避免频繁打断用户说话,vad组件需要等待一段时间(约0.8~1.3秒)确认用户说完了;其次,vad截断之后的语音需要经过语音识别系统转换为文字(约0.3~0.5秒),送入对话引擎并获取到应答文本(约0.1~0.5秒);随后,应答文本被送入语音合成系统输出为语音流(约0.3~0.5秒),才能进行播放,用户就听到声音了。为了计算简单,暂时忽略网络传输延迟,只考虑模型推理或计算用时,基本上对话响应时间的典型值就达到2秒左右,给用户带来的对话感觉是明显卡顿,不够顺畅。
3、在上述过程中,语音识别与语音合成的首段延迟取决于模型推理的速度,在计算软硬件不变的前提下难以显著压缩,而对话引擎的应答时间由于需经历自然语言理解、知识库查询、答案召回、精细排序等诸多环节,尤其是基于大语言模型(llm)的问答经常需要1~3秒的推理时间,也不易缩减。减小vad的等待阈值是一个立竿见影的举措,但由于不同人的说话习惯、思考间隔不同,减小vad阈值会造成机器人意外抢答。因此,语音对话机器人系统中经常面临高延迟和高抢话率的两难取舍问题。
技术实现思路
1、本发明的目的是克服现有技术存在的不足,提供一种提升语音对话系统响应速度的方法。
2、本发明的目的通过以下技术方案来实现:
3、一种提升语音对话系统响应速度的方法,特点是:包括以下步骤:
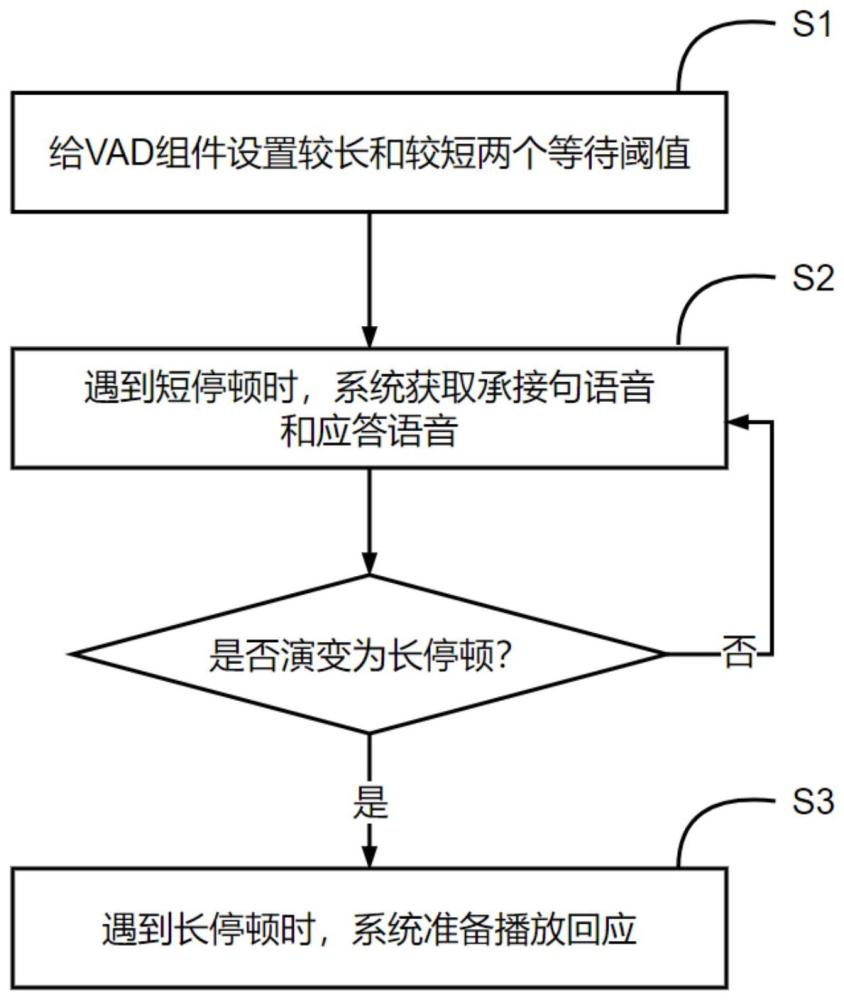
4、s1)对vad组件设定较长和较短两个等待阈值;
5、以一个较长阈值(截断阈值)作为长停顿信号,一个较短阈值作为短停顿信号,较短的阈值用于识别用户连续说话中因换气或梳理思路引起的正常停顿信号,较长的阈值用于识别用户说话的休止信号;
6、s2)遇到短停顿时,系统获取承接句语音v1和应答语音v2;
7、为对话系统引入承接句,承接句用于尽快给用户一个简短的反馈信息,用户听到后就会知道机器人已经准备回答了,改善人机对话的流畅性;在接到短停顿信号时,系统进行如下操作:
8、1)获取承接句语音v1;
9、承接句可直接播放预先准备的语音文件,跳过问答引擎和语音合成,提前准备一些常用承接语句的语音文件编号存档,在需要时随机选择一个备用;或者,经过问答引擎获取文字再由语音合成组件实时生成语音;
10、2)将短停顿前的全部语音发给下一环节处理;
11、为减小用户体验的延迟,在遇到短停顿信号时就开始处理该信号前的全部语音,经由asr识别为文字、送入对话引擎、答案文本再经过tts合成语音,将合成的应答语音v2送入缓冲区备用;
12、如果此次不是本轮会话第一次遇到短停顿,则丢弃上次获取的承接句语音v1和应答语音v2,并重新获取;
13、s3)遇到长停顿时,系统准备播放回应;
14、在接到长停顿信号时,已经确认用户说话完毕,但最临近的短停顿对应的应答语音v2可能还没有接到;如果此时已收到应答语音v2,则忽略承接句语音v1,只播放应答语音v2;如果没收到应答语音v2,则先播放承接句语音v1,并将应答语音v2加入播放队列清单。
15、进一步地,上述的一种提升语音对话系统响应速度的方法,其中,步骤s1),长阈值、短阈值的取值根据实际场景中说话间隔的统计特征确定;
16、设定后,在一轮对话中接收用户语音输入的过程中,会遇到至少1个短停顿与1个长停顿信号,因在vad组件检测到用户不再说话持续一段时间达到短停顿阈值后,就触发短停顿信号;如果继续保持静音,稍后就触发长停顿信号,表明这句话说完了,可进行后续处理;如果用户在长停顿阈值之前又继续说话,则表明用户没有说完,应该将前后的语音连接起来,直到最后遇到长停顿信号进行整体处理。
17、进一步地,上述的一种提升语音对话系统响应速度的方法,其中,短停顿短阈值取0.5秒,长停顿长阈值取1秒。
18、进一步地,上述的一种提升语音对话系统响应速度的方法,其中,步骤s2),如果追求更快的响应速度,承接句直接播放预先准备的语音文件,跳过问答引擎和语音合成;如果追求承接句的灵活多样,经过问答引擎获取文字再由语音合成组件实时生成语音;优选地,选择承接句直接播放预先准备的语音文件的形式。
19、进一步地,上述的一种提升语音对话系统响应速度的方法,其中,步骤s2),接到短停顿信号,获取承接句语音v1和应答语音v2;再次接到短停顿信号,丢弃缓存的承接句语音v1和应答语音v2并重新获取;再次接到短停顿信号,再次丢弃缓存的承接句语音v1和应答语音v2并重新获取;如此循环直至长停顿信号到来。
20、进一步地,上述的一种提升语音对话系统响应速度的方法,其中,步骤s3),系统接到长停顿信号,如果应答语音v2还在生成过程中,此时可直接播放承接句语音v1,在播放承接句语音v1的过程中,会收到应答语音v2,顺序播放达到流畅对话的效果;即使承接句语音v1播放完还未收到应答语音v2,在系统正常运行的状态下能预期应答语音v2在很短的时间就绪。
21、本发明与现有技术相比具有显著的优点和有益效果,具体体现在以下方面:
22、本发明为解决语音对话系统处理步骤繁多、等待时间长等问题,引入长短两种停顿阈值,用来处理不同类型的静音间隔,并对两种停顿信号的系统行为进行重新设计;本发明还引入了承接句,以便在用户说完之后立刻给用户快速回应;采用了流水线的思路,利用短停顿到长停顿的间隔以及承接句前台播放的时间在后台处理获取应答语音,缩短了用户等待时间。可以使语音对话系统在听用户说完之后1秒左右极速响应、顺畅应答,对话延迟接近人与人对话的水平。在语音交互的对话系统中具有广泛的应用价值。
23、本发明的其他特征和优点将在随后的说明书阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明具体实施方式了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
技术特征:1.一种提升语音对话系统响应速度的方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的一种提升语音对话系统响应速度的方法,其特征在于:步骤s1),长阈值、短阈值的取值根据实际场景中说话间隔的统计特征确定;
3.根据权利要求2所述的一种提升语音对话系统响应速度的方法,其特征在于:短停顿短阈值取0.5秒,长停顿长阈值取1秒。
4.根据权利要求1所述的一种提升语音对话系统响应速度的方法,其特征在于:步骤s2),如果追求更快的响应速度,承接句直接播放预先准备的语音文件,跳过问答引擎和语音合成;如果追求承接句的灵活多样,经过问答引擎获取文字再由语音合成组件实时生成语音。
5.根据权利要求1所述的一种提升语音对话系统响应速度的方法,其特征在于:步骤s2),接到短停顿信号,获取承接句语音v1和应答语音v2;再次接到短停顿信号,丢弃缓存的承接句语音v1和应答语音v2并重新获取;再次接到短停顿信号,再次丢弃缓存的承接句语音v1和应答语音v2并重新获取;如此循环直至长停顿信号到来。
6.根据权利要求1所述的一种提升语音对话系统响应速度的方法,其特征在于:步骤s3),系统接到长停顿信号,如果应答语音v2还在生成过程中,此时可直接播放承接句语音v1,在播放承接句语音v1的过程中,会收到应答语音v2,顺序播放达到流畅对话的效果;即使承接句语音v1播放完还未收到应答语音v2,在系统正常运行的状态下能预期应答语音v2在很短的时间就绪。
技术总结本发明涉及一种提升语音对话系统响应速度的方法,给VAD组件设定较长和较短两个等待阈值,较短的阈值用于识别用户连续说话中因换气或梳理思路引起的正常停顿信号,较长的阈值用于识别用户说话的休止信号;遇到短停顿时,系统获取承接句语音和应答语音,承接句用于尽快给用户一个简短的反馈信息,用户听到后就会知道机器人已经准备回答了;遇到长停顿时,系统准备播放回应。引入长短两种停顿阈值,用来处理不同类型的静音间隔,并对两种停顿信号的系统行为进行重新设计;引入承接句,以便在用户说完之后立刻给用户快速回应;采用了流水线的思路,利用短停顿到长停顿的间隔以及承接句前台播放的时间在后台处理获取应答语音,缩短用户等待时间。技术研发人员:孟亚磊,袁学青,刘继明,金宁,刘松受保护的技术使用者:网经科技(苏州)有限公司技术研发日:技术公布日:2024/3/12本文地址:https://www.jishuxx.com/zhuanli/20240618/22323.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表