语音识别方法、系统和存储介质与流程
- 国知局
- 2024-06-21 11:39:25
本公开涉及人机交互领域,尤其涉及一种语音识别方法、系统和存储介质。
背景技术:
1、语音审核是保障社交平台内容质量和安全的重要技术,针对平台的语音进行人工或自动的审核过滤,能够实现有效过滤违规或违法的内容,保障平台内容安全,抵御企业违规风险,营造绿色语音社交环境。
2、语音识别在语音审核中扮演着重要的角色,作为语音审核的入口至关重要,语音识别系统负责将语音转换为文字,以便进行后续的内容审核和分析。它的准确率和性能直接影响语音审核的效果。
技术实现思路
1、本公开要解决的一个技术问题是,提供一种语音识别方法、系统和存储介质,能够提高语音识别的准确性,进而提高语音审核的准确性。
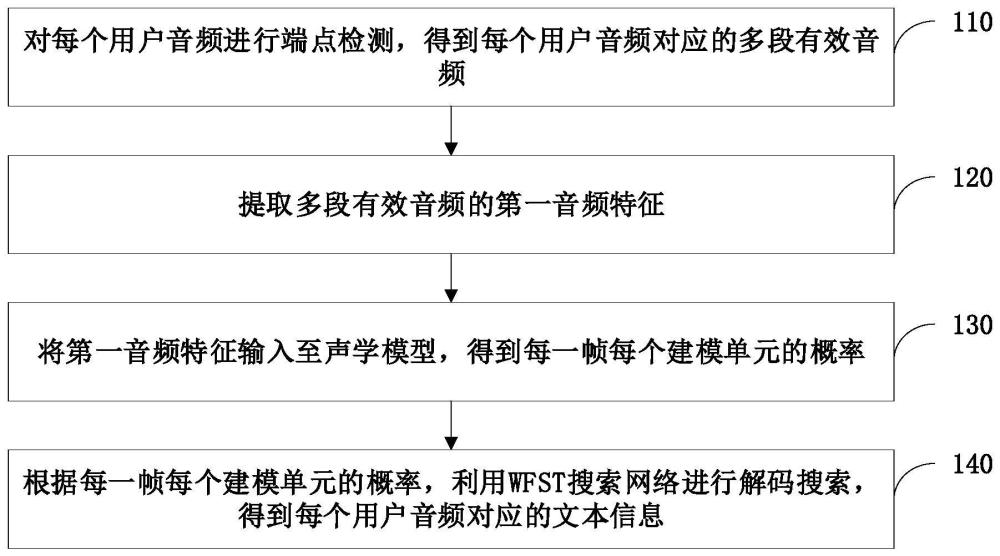
2、根据本公开一方面,提出一种语音识别方法,包括:对每个用户音频进行端点检测,得到每个用户音频对应的多段有效音频;提取多段有效音频的第一音频特征;将第一音频特征输入至声学模型,得到每一帧每个建模单元的概率;以及根据每一帧每个建模单元的概率,利用加权有限状态转换机wfst搜索网络进行解码搜索,得到每个用户音频对应的文本信息。
3、在一些实施例中,在图形处理器gpu并行对多个用户音频中每个用户音频进行端点检测,得到每个用户音频对应的多段有效音频;在gpu并行提取多段有效音频的第一音频特征;将第一音频特征输入至声学模型,利用gpu并行处理,得到每一帧每个建模单元的概率;以及在gpu,根据每一帧每个建模单元的概率,利用wfst搜索网络进行并行解码搜索,得到每个用户音频对应的文本信息。
4、在一些实施例中,对每个用户音频进行端点检测,得到多段有效音频包括:对所述每个用户音频进行第二音频特征提取;将每个用户音频对应的第二音频特征输入至神经网络模型进行端点检测;根据神经网络模型输出的二分类概率并进行平滑策略处理,确定用户音频对应的断句信息;以及根据断句信息,得到多段有效音频。
5、在一些实施例中,建模单元采用字级别建模单元。
6、在一些实施例中,wfst搜索网络基于语言模型利用fst处理工具构建得到,其中,语言模型基于文本语料使用统计语言建模方法训练得到。
7、在一些实施例中,语言模型为字级别的语言模型。
8、根据本公开的另一方面,还提出一种语音识别系统,包括:语音端点检测模块,被配置为对每个用户音频进行端点检测,得到每个用户音频对应的多段有效音频;音频特征提取模块,被配置为提取多段有效音频的第一音频特征;声学模型推理模块,被配置为将第一音频特征输入至声学模型,得到每一帧每个建模单元的概率;以及解码网络搜索模块,被配置为根据每一帧每个建模单元的概率,利用加权有限状态转换机wfst搜索网络进行解码搜索,得到每个用户音频对应的文本信息。
9、在一些实施例中,语音端点检测模块、音频特征提取模块、声学模型推理模块和解码网络搜索模块,在图形处理器gpu上运行。
10、根据本公开的另一方面,还提出一种语音识别系统,包括:存储器;以及耦接至存储器的处理器,处理器被配置为基于存储在存储器的指令执行如上述的语音识别方法。
11、根据本公开的另一方面,还提出一种计算机可读存储介质,其上存储有计算机程序指令,该指令被处理器执行时实现如上述的语音识别方法。
12、本公开实施例中,对用户音频进行端点检测,将长音频切断为多个有效音频,进而进行特征提取,以及声学模型推理,最后利用wfst搜索网络进行解码搜索,得到每个用户音频对应的文本信息,提高了语音识别的准确性,进而提高了后续语音审核的准确性。
13、通过以下参照附图对本公开的示例性实施例的详细描述,本公开的其它特征及其优点将会变得清楚。
技术特征:1.一种语音识别方法,包括:
2.根据权利要求1所述的语音识别方法,其中,
3.根据权利要求1所述的语音识别方法,其中,对每个用户音频进行端点检测,得到多段有效音频包括:
4.根据权利要求1所述的语音识别方法,其中,所述建模单元采用字级别建模单元。
5.根据权利要求1至4任一所述的语音识别方法,其中,
6.根据权利要求5所述的语音识别方法,其中,
7.一种语音识别系统,包括:
8.根据权利要求7所述的语音识别系统,其中,
9.一种语音识别系统,包括:
10.一种计算机可读存储介质,其上存储有计算机程序指令,该指令被处理器执行时实现如权利要求1至6任一项所述的语音识别方法。
技术总结本公开提供了一种语音识别方法、系统和存储介质,涉及人机交互领域。该方法包括:对每个用户音频进行端点检测,得到每个用户音频对应的多段有效音频;提取多段有效音频的第一音频特征;将第一音频特征输入至声学模型,得到每一帧每个建模单元的概率;以及根据每一帧每个建模单元的概率,利用WFST搜索网络进行解码搜索,得到每个用户音频对应的文本信息。本公开提高了语音识别的准确性,进而提高了后续语音审核的准确性。另外,将各个步骤在GPU上运行,提高了语音识别系统的吞吐,降低了语音识别延迟,解决了语音审核及时性问题,同时降低了资源消耗。技术研发人员:吴军,刘忠亮,张璐,陶明受保护的技术使用者:上海任意门科技有限公司技术研发日:技术公布日:2024/3/27本文地址:https://www.jishuxx.com/zhuanli/20240618/22708.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。