一种基于Transformer的戏曲演唱音色转换方法
- 国知局
- 2024-06-21 11:47:48
本发明属于视频声音转换,具体是一种基于transformer的戏曲演唱音色转换方法。
背景技术:
1、在戏曲的多种表现手段中,音乐,特别是歌唱,始终是主导的因素,唱念做打中,唱始终占据首要位置。由于唱的存在,念白无法像生活语言那样自然,而是需要吟咏,强调语言音调的韵律和节奏的回环跌宕,形成独特的音乐美。散白、韵白、韵律性朗诵(如引子和诗、对)以及节奏性吟诵(如“干牌子”和数板)等各种念白形式,都代表了语言与音乐在不同层次上的巧妙融合,而汉字音调的高低、强弱和抑扬顿挫之美,则构成了戏曲念白音乐美的基石。通过迁移戏曲人物音色,可以为影视作品和娱乐节目创造更加生动、富有情感的声音表现,从而提升观众的听觉体验,同时,采用迁移戏曲人物音色到演唱音频,还有助于创造多样化的艺术形式,这种技术使得戏曲音色能够融入不同类型的音频创作,为音乐和表演艺术带来新的可能性,有望推动音乐和戏曲领域的交叉融合,促使艺术创作在多个层面上展现出更为丰富和独有的特色。
2、现有的歌唱声音转换模型主要采用编码器-解码器框架,其中编码器解除歌手的纠缠来自语言内容的音色信息,解码器利用不同的音色信息来重建歌唱音频,从而实现声音转换,由于将任意说话人的声音转换至任意演唱音频的过程中,涉及到将歌曲改编成看不见的目标说话者的声音,所以需要先概况各种声音特征,这是一个非常巨大的挑战。而且,当前的模型通常使用来自查找表或说话人验证模型的说话人嵌入向量来捕获说话人特定的特征,但是,自查表方法受到其预定义的说话人音色集的限制,并且难以处理未见过的说话人声音,此外,难以有效地从内容中分离出说话人音色的特征,会导致“音色泄漏”,即源音频的音色仍然保留在转换后的音频中,造成演唱音频质量较差。
技术实现思路
1、针对现有技术存在的不足,本发明的目的是提供一种基于transformer的戏曲演唱音色转换方法,能够将任意说话人的音色迁移至源演唱音频,并生成不含源音频演唱音色的戏曲演唱音频。
2、为了实现上述目的,本发明采用以下技术方案予以实现:
3、一种基于transformer的戏曲演唱音色转换方法,包括如下步骤:
4、步骤1、收集秦腔戏曲演唱音频,并将其添加至开源数据集opensinger,形成源音频数据集;
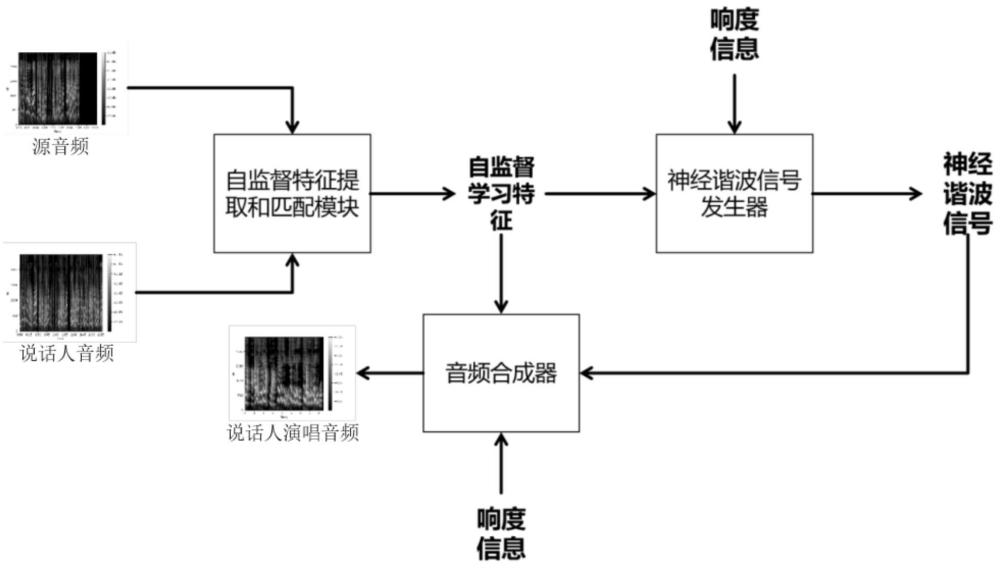
5、步骤2、先利用transformer编码器替换自监督学习模块的一个卷积特征编码器,构成自监督学习模块,再引入k邻近匹配策略,形成自监督学习特征匹配模块,接着将神经谐波信号发生器模块集成到自监督学习特征匹配模块,形成基于神经连接的唱歌声音转换系统;
6、步骤3、收集目标说话人日常说话音频,形成说话人音频数据集,并将其导入基于神经连接的唱歌声音转换系统;
7、步骤4、先利用自监督学习模块分别从源音频数据集和说话人音频数据集中提取音频特征,再利用k邻近匹配策略从源音频提取的音频特征替换为目标说话人音频的音频特征,生成自监督学习特征;
8、步骤5、神经谐波信号发生器模块接收生成自监督学习特征并导出正弦激励信号,采用线性时变滤波器对不同谐波分量的幅值进行调整从而得到滤波后的激励信号,然后将正弦激励信号与滤波后的激励信号相连接,形成用于表示音高信息的神经谐波信号,并送入音频合成器模块进行音高调节;
9、步骤6、音频合成器模块对生成的神经谐波信号和说话人音频的响度进行一维卷积,由下采样模块向上采样模块提供响度;
10、步骤7、音频合成器模块通过上采样模块逐步将自监督学习特征、响度和神经谐波信号合成为说话人音色演唱音频。
11、进一步地,所述步骤2的自监督学习特征匹配模块包括一个卷积特征编码器和一个transformer编码器;
12、所述卷积特征编码器包括七个时间卷积块、归一化层和一个gelu激活层,时间卷积块具有512个通道,通道的步长为(5,2,2,2,2,2),内核宽度为(10,3,3,3,3,2,2);
13、所述transformer编码器配备了基于卷积的相对位置嵌入层,嵌入层具有128个内核大小,且其底部有16个组,卷积编码器的卷积输出和偏移量作为transformer编码器的输入。
14、进一步地,所述步骤2的k邻近匹配策略包括一个编码器、一个转换器和一个声码器;
15、所述编码器提取附近特征具有相似语音内容的表示,转换器将源音频的音色转换为目标说话人的音色,生成自监督学习特征,声码器将自监督学习特征转换成音频波形。
16、进一步地,所述步骤3还包括将说话人音频数据集划分为训练集、验证集和测试集。
17、进一步地,所述步骤5的具体过程为:
18、步骤5.1、神经谐波信号发生器模块将帧级的自监督学习特征f0上采样为高频级f0[n],通过公式(1)和公式(2)从f0中导出正弦激励信号p[n],表示为:
19、
20、
21、式中,k是对应于f0[n]所能达到的最大谐波数,fs为音频采样率,n为时间;
22、步骤5.2、采用线性时变滤波器,根据每次上采样时的状态特征,对不同谐波分量的幅值进行调整,得到滤波后的激励信号表示为:
23、
24、式中,h1[n]和h2[n]分别是作用于p[n]和z[n]的线性时变滤波器,且h1[n]和h2[n]的系数是通过将自监督学习特征和响度连接后,由神经滤波器估计器估计而得;*是卷积运算,z[n]是由高斯分布随机产生的信号序列;
25、步骤5.3、将正弦激励信号与滤波后的激励信号相连接,形成神经谐波信号,并送入音频合成器模块进行音高调节,表示为:
26、
27、式中,表示连接操作。
28、进一步地,所述步骤6的下采样块分别对可听正弦激励信号和响度特征的时间维度进行下采样,下样块共有三个,膨胀率分别为1、2和4,下样块的leakyrelu激活函数的斜率为负0.2。
29、进一步地,所述步骤7的上采样模块共有四个,膨胀率分别为1、3、9和27,分别以192、96、48、24个通道数对时间维度进行4、4、4、5个因子的逐步上采样。
30、本发明与现有技术相比,具有如下技术效果:
31、本发明构建的基于神经连接的唱歌声音转换系统整体架构完整,在说话人音色与源音频合成说话人音色戏曲演唱音频中表现出了优异的性能,体现在:先通过自监督学习模块分别从源音频和说话人音频中提取音频特征,再使用k邻近匹配策略用说话人音频特征替换源音频的音频特征,生成自监督学习特征,神经谐波信号发生器模块采用线性时变滤波器对不同谐波分量的幅值进行调整从而得到滤波后的激励信号,然后将正弦激励信号与滤波后的激励信号相连接,形成用于表示音高信息的神经谐波信号,音频合成器模块通过一维卷积以及上采样和下采样操作,最终生成说话人音色戏曲演唱音频,解决了现有歌唱声音转换模型不能将任意说话人的音色的迁移到源演唱音频以及生成的音频依然保留源音频音色的问题,为中华非物质文化遗产的传承和发扬具有积极的意义。
32、本发明通过神经谐波信号发生器模块将自监督学习特征和响度一同生成为滤波系数,再将生成的滤波系数和激励信号通过线性时变滤波器以及连接操作,生成神经谐波信号,能够有效消除“音色泄露”问题,从而生成不含源音频演唱音色的戏曲演唱音频。
本文地址:https://www.jishuxx.com/zhuanli/20240618/23610.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表