一种高保真的语音转换系统及方法与流程
- 国知局
- 2024-06-21 11:48:41
本发明涉及语音识别与语音合成,更具体的说是涉及一种高保真的语音转换系统及方法。
背景技术:
1、语音转换是指将一个人说的话以另外一个人的口吻说出来并保持所说内容不变的技术,一个生动的例子便是柯南的变声蝴蝶结。语音转换的应用场景有很多,在电影配音中,配音员和演员本人音色有明显差异,而观众总是期望能有演员本人的说话效果,此时应用语音转换技术就能将配音员说的话转换成具有演员本人音色的语音,从而增强了电影的观赏效果;在某些通话场景中,说话人不方便透露自己身份信息时可以通过语音转换技术将语音转换成另一个人说的从而达到匿名的目的;在直播领域中,某些主播由于声带的问题不具备一副好嗓子,利用语音转换技术将主播的声音转换至其他悦耳的人声上去,达到美化声音和提升直播效果的目的。
2、语音转换已有相当长的发展历史。传统的语音转换方法通过改变音频的基频、共振峰等信号处理的方式改变原始音频的音色,能达到特定的变声目的,但需要占用较多的时间去优化参数并且效果不稳定。基于深度学习的语音转换技术无论从变声场景的丰富度,亦或是转换后音频的自然度都极大的提升了语音转换的效果。现有语音转换技术仍有诸多问题亟待解决。基于语音识别和语音合成的语音转换虽能取得较好的转换音质及音色,原始音频的韵律及内容难以保证;基于生成对抗网络或者变分自编码器的语音转换能完整的保留原始音频的内容及韵律,原色音色难以消除且音质往往失真。
3、因此,如何提高语音转换的保真效果是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种高保真的语音转换系统及方法,提供参考音频即可定制转换音色,将任何输入音频转换至目标音色,完整保留输入音频的内容及韵律且转换后具有高保真的音质,能极大地满足各个场景的变声场景。
2、为了实现上述目的,本发明采用如下技术方案:
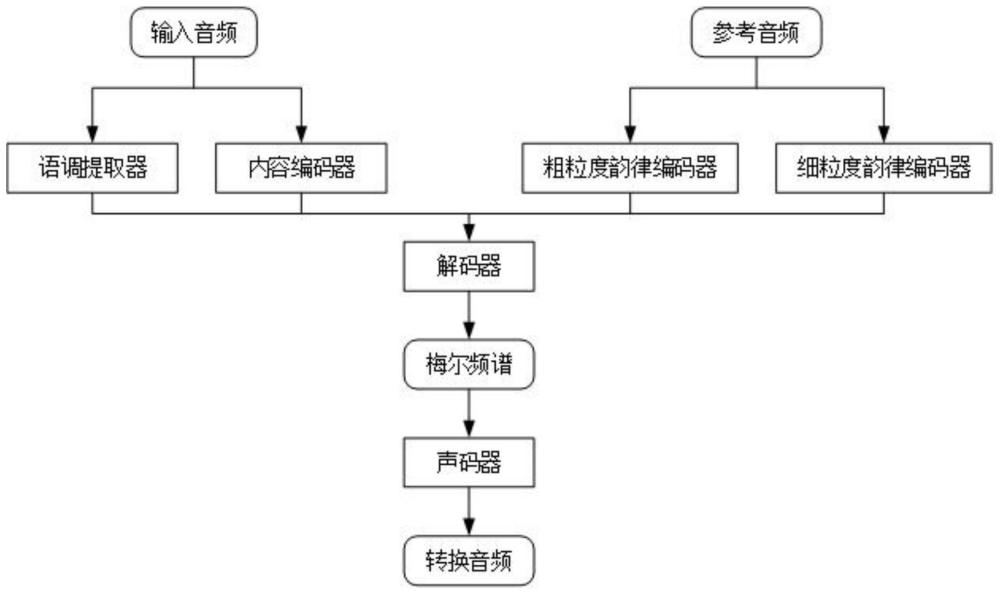
3、一种高保真的语音转换系统,包括音频采集模块、语音识别模块、韵律编码器、解码器和声码器;
4、音频采集模块,采集源说话人的输入音频和目标说话人的参考音频;
5、语音识别模块,提取输入音频中的内容信息和语调信息;
6、韵律编码器,提取参考音频的韵律信息;
7、解码器,根据内容信息、语调信息和韵律信息生成梅尔频谱图;
8、声码器,将梅尔频谱图转换成音频。
9、优选的,语音识别模块包括内容编码器和语调提取器;采用wenet算法模型作为内容编码器,采集大规模语音识别数据集训练内容编码器,训练收敛之后将输入音频输入至内容编码器获得音素后验概率,音素后验概率即作为该音频的内容信息;语调提取器采用praat-parselmouth提取输入音频中的基频信息并进行量化获得语调信息。
10、优选的,韵律信息包括整体韵律信息和隐特征韵律信息;韵律编码器包括粗粒度韵律编码器和细粒度韵律编码器;粗粒度韵律编码器包括多层卷积层和多层池化层,从参考音频中获取目标说话人整体的韵律和音色信息,即通过多层卷积和池化层从参考音频中得到一个一维向量,作为整体韵律信息;细粒度韵律编码器包括多层卷积层和多层池化层,从参考音频中得到多维隐特征,作为隐特征韵律信息;所述粗粒度韵律编码器的池化层数量大于所述细粒度韵律编码器的池化层数量。整体韵律信息包括目标说话人的韵律和音色,隐特征韵律信息则具体到类似于目标说话人每个字的发音和重音等细节特点。
11、优选的,将内容信息、语调信息、整体韵律信息和隐特征韵律信息在解码器进行求和或者拼接后生成梅尔频谱图;隐特征韵律信息作为注意力机制的query,与内容信息进行attention送入解码器。
12、优选的,解码器采用transformer结构。
13、优选的,声码器采用hifi-gan模型将梅尔频谱图映射为音频。
14、优选的,内容编码器包括transformer encoder层,将输入音频输入至transformer encoder层,获得音素后验概率作为内容信息。
15、一种高保真的语音转换方法,包括以下步骤:
16、步骤1:获取源说话人的输入音频和目标说话人的参考音频;
17、步骤2:从输入音频提取出内容信息和语调信息,从参考音频中提取出目标说话人的韵律信息;
18、步骤3:根据内容信息、语调信息和韵律信息生成梅尔频谱图;
19、步骤4:将梅尔频谱图转换成音频。
20、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种高保真的语音转换系统及方法,利用语音识别中音素后验概率(ppg)解决源说话人身份信息泄露的问题,同时设计不同粒度的韵律提取模块,尽可能地保证转换音频和目标说话人的音色相似度,并且,为了转换后语调的稳定,从输入音频提取出基频作为额外信息引导转换,从而实现学习目标说话人的参考音频,将作为待转换音频的输入音频转换至具有目标说话人音色的音频。本发明所涉及的语音转换系统和方法解决了当前语音转换技术音色相似度不高,音质不自然的问题,能更好地满足各个场景的语音变声需求。
技术特征:1.一种高保真的语音转换系统,其特征在于,包括音频采集模块、语音识别模块、韵律编码器、解码器和声码器;
2.根据权利要求1所述的一种高保真的语音转换系统,其特征在于,语音识别模块包括内容编码器和语调提取器;采用wenet算法模型作为内容编码器,采集大规模语音识别数据集训练内容编码器,训练收敛之后将输入音频输入至内容编码器获得音素后验概率,音素后验概率作为内容信息;语调提取器采用praat-parselmouth提取输入音频中的基频信息并进行量化获得语调信息。
3.根据权利要求1所述的一种高保真的语音转换系统,其特征在于,韵律信息包括整体韵律信息和隐特征韵律信息;韵律编码器包括粗粒度韵律编码器和细粒度韵律编码器;粗粒度韵律编码器包括多层卷积层和多层池化层,从参考音频中获取目标说话人整体的韵律和音色信息,作为整体韵律信息;细粒度韵律编码器包括多层卷积层和多层池化层,从参考音频中得到多维隐特征,作为隐特征韵律信息;所述粗粒度韵律编码器的池化层数量大于所述细粒度韵律编码器的池化层数量。
4.根据权利要求3所述的一种高保真的语音转换系统,其特征在于,将内容信息、语调信息、整体韵律信息和隐特征韵律信息在解码器进行求和或者拼接后生成梅尔频谱图;隐特征韵律信息作为注意力机制的query,与内容信息进行attention送入解码器。
5.根据权利要求3所述的一种高保真的语音转换系统,其特征在于,解码器采用transformer结构。
6.根据权利要求1所述的一种高保真的语音转换系统,其特征在于,声码器采用hifi-gan模型将梅尔频谱图映射为音频。
7.根据权利要求2所述的一种高保真的语音转换系统,其特征在于,内容编码器包括transformer encoder层,将输入音频输入至transformer encoder层,获得音素后验概率作为内容信息。
8.一种高保真的语音转换方法,其特征在于,应用于权利要求1-7任一项所述的一种高保真的语音转换系统,包括以下步骤:
技术总结本发明公开了一种高保真的语音转换系统及方法,涉及语音识别与语音合成技术领域,系统包括音频采集模块、语音识别模块、韵律编码器、解码器和声码器;音频采集模块,采集源说话人的输入音频和目标说话人的参考音频;语音识别模块,提取输入音频中的内容信息和语调信息;韵律编码器,提取参考音频的韵律信息;解码器,根据内容信息、语调信息和韵律信息生成梅尔频谱图;声码器,将梅尔频谱图转换成音频。本发明能够将任何输入音频转换至目标音色,完整保留输入音频的内容及韵律且转换后具有高保真的音质,能极大地满足各个场景的变声场景。技术研发人员:刘刚,苏江受保护的技术使用者:暗物质(北京)智能科技有限公司技术研发日:技术公布日:2024/5/6本文地址:https://www.jishuxx.com/zhuanli/20240618/23701.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表