基于变分自编码器和特征重构的肺音识别方法
- 国知局
- 2024-06-21 11:51:49
本发明属于医学图像处理中的肺音识别,具体是一种基于变分自编码器和特征重构的肺音识别方法。
背景技术:
1、肺部疾病主要包括哮喘、慢性阻塞性肺病(chronic obstructive pulmonarydisease,copd)和肺炎等,肺音是人体在呼吸过程中产生的一种声学信号,包含着丰富的生理和病理信息,因此通过肺音信号可以诊断肺部疾病。与胸部x光、肺动脉造影和动脉血气分析等技术相比,肺音听诊更经济、无创,但是因为肺音的频率范围超出了人耳的可接受范围,会增加医生漏诊的概率。同时,肺音听诊受医生主观因素的影响较大,例如个人经验、专业知识水平等,故可能导致误诊。通过肺音信号进行计算机辅助诊断可以一定程度上减轻医疗系统的负担,并减少漏诊和误诊。
2、在肺音识别领域,对已知类别的数据进行分类和识别,即闭集识别任务作为关键问题已经得到了长足发展。然而,随着现实场景中新类别的不断涌现以及数据分布的多样性,传统的闭集识别方法在处理未知类别时显得力不从心,因此开集识别应运而生,旨在解决传统闭集识别无法解决的未知类识别问题。开集识别不仅要求模型能够对已知类别做出准确的预测,还要求对新出现的未知类别进行有效地处理和区分。在实际的临床应用场景中,可能会包含更多的噪声、干扰和其他不可控制的因素,尤其是很难保证识别目标均为已知类别,因此对于开集肺音识别任务,不仅要求模型能够识别已知类别,还要准确地将未知类别标记为“未知”或“其他”,以便及时发现新型肺部疾病模式和异常情况,这对模型的真实性、可靠性、泛化性和鲁棒性有着更高的要求,同时还需要精准划分已知类别和未知类别的判定边界。为此,本发明提出一种基于变分自编码器和特征重构的肺音识别方法。
技术实现思路
1、针对现有技术的不足,本发明拟解决的技术问题是,提供一种基于变分自编码器和特征重构的肺音识别方法。
2、本发明解决所述技术问题采用如下的技术方案:
3、一种基于变分自编码器和特征重构的肺音识别方法,其特征在于,该方法包括如下步骤:
4、第一步、获取肺音信号,并对肺音信号进行降噪;将降噪后的肺音信号划分片段,肺音信号片段转换为梅尔语谱图,作为肺音识别模型的输入图像;
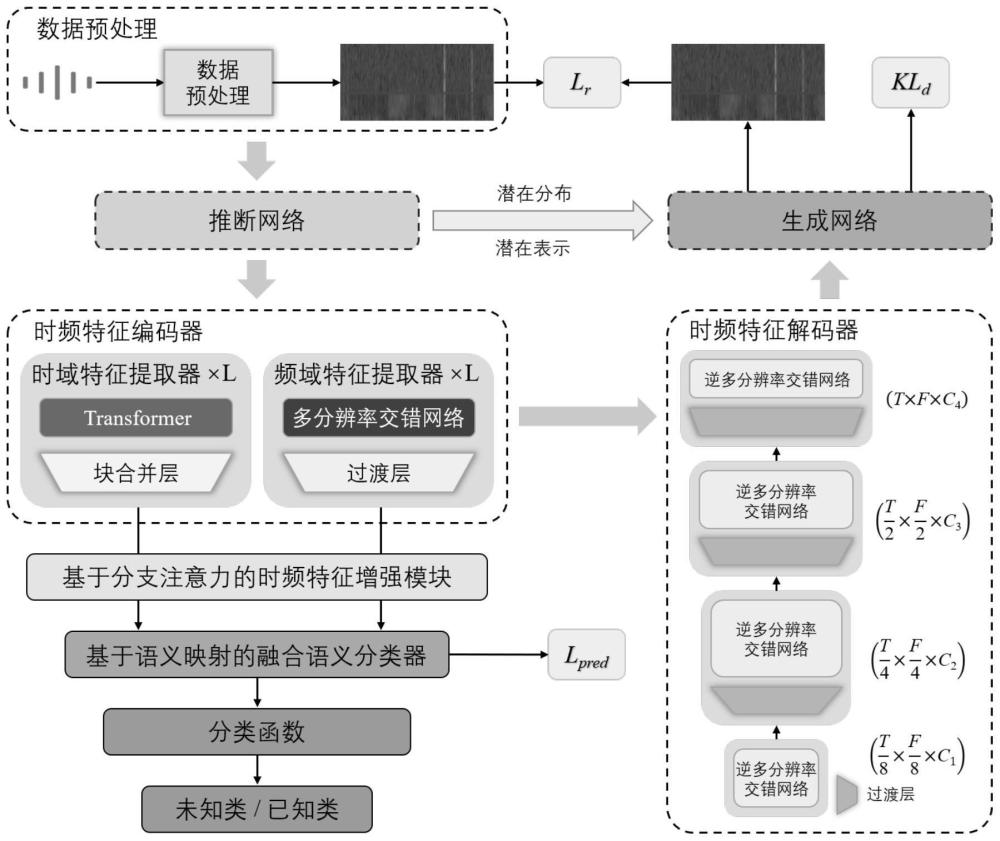
5、第二步、构建肺音识别模型;肺音识别模型包括潜在表示推断与生成网络、时频特征编码与解码器以及分类模块;其中,潜在表示推断与生成网络包括推断网络和生成网络,时频特征编码与解码器包括时频特征编码器和时频特征解码器,分类模块包括基于分支注意力的时频特征增强模块和基于语义映射的融合语义分类器;
6、推断网络包括推断模块和胶囊网络,生成网络包括胶囊网络和生成模块;输入图像经过推断模块得到特征xi,推断网络的胶囊网络对特征xi的潜在分布进行建模,得到特征xi的潜在分布的均值μi和方差σi2;特征xi经过时频特征编码器,得到编码特征;时频特征解码器对编码特征进行解码,得到解码特征;
7、生成网络的胶囊网络对解码特征的潜在分布进行建模,得到解码特征的潜在分布的均值μg和方差σg2;对解码特征xd的潜在分布与特征xi的潜在分布进行融合,得到融合分布,融合分布的均值μr和方差σr2表示为:
8、
9、根据式(5)对融合分布进行采样,得到重构特征xr;重构特征xr经过生成模块进行解码,得到重构图像;
10、xr=μr+σr2⊙ε (5)
11、式中,⊙代表逐元素相乘,ε服从正态分布n(0,i);
12、在分类模块中,编码特征经过基于分支注意力的时频特征增强模块后,再经过基于语义映射的融合语义分类器,得到预测标签;
13、在训练阶段,通过输入图像和重构图像计算重构损失,根据重构损失的均值和标准差设置判定阈值τ;
14、
15、
16、
17、其中,n为样本数量,为第i个样本的重构损失,和分别为重构损失的均值和标准差;
18、在训练阶段,预测标签用于计算预测损失;在测试阶段,若测试样本的重构损失大于等于判定阈值τ,则判定该样本为未知类别,若测试样本的重构损失小于判定阈值τ,则输出的预测标签;
19、第三步,对肺音识别模型进行训练,并将训练后的肺音识别模型用于肺音识别,得到预测标签。
20、与现有技术相比,本发明的优点和有益效果是:
21、(1)传统的开集识别模型通常基于分类器,区分已知类别和未知类别通常通过阈值或异常检测等方式,然而阈值的选择通常依赖于经验或手动调整,难以适应不同数据分布下的未知类别。异常检测通过检测数据中的异常点或者离群点来识别未知类别,但该方法对于未知类数据的分布和特性的假设通常是比较严格的,难以检测复杂环境产生的未知类别。因此,本发明采用生成网络辅助的方式,基于变分自编码器的思想设计构建了肺音识别模型,通过精准划分已知类和未知类的判定边界,能够准确地将未知类别标记为“未知”或“其他”,实现开集肺音识别。
22、(2)潜在表示推断与生成网络通过推断网络学习数据的潜在表示和生成数据的浅层特征,并由生成网络根据潜在表示和时频特征解码器输出的解码特征来重构肺音的原始特征,增强了模型的表示学习和特征重构能力,帮助划定已知类别和未知类别的判定边界。
23、(3)在分类模块中,首先通过基于分支注意力的时频特征增强模块对时频特征编码器输出的编码特征进行增强,再通过基于语义映射的融合语义分类器进行已知类识别。在测试阶段,通过分类函数结合重构损失对未知类样本的预测标签进行修正,输出模型对已知类和未知类的预测结果。
技术特征:1.一种基于变分自编码器和特征重构的肺音识别方法,其特征在于,该方法包括如下步骤:
2.根据权利要求1所述的基于变分自编码器和特征重构的肺音识别方法,其特征在于,所述推断模块包括多个推断层,层间穿插过渡层,每个推断层由多个多分辨率交错网络层堆叠而成;生成模块为推断模块的逆网络,包括多个生成层,层间穿插过渡层,当前生成层的输出特征与对应位置的推断层的输出特征相加后输入到下一个生成层中。
3.根据权利要求1或2所述的基于变分自编码器和特征重构的肺音识别方法,其特征在于,第一步中,首先使用高通滤波器去除肺音信号中的环境噪声,得到滤波后的肺音信号;然后,对滤波后的肺音信号进行分解与重构,得到重构后的心音信号;最后,从滤波后的肺音信号中减去重构后的心音信号,得到降噪后的肺音信号。
4.根据权利要求1所述的基于变分自编码器和特征重构的肺音识别方法,其特征在于,所述时频特征编码器基于多分辨率交错网络和transformer构建,时频特征解码器基于逆多分辨率交错网络构建;时频特征解码器由多个多分辨率交错网络层堆叠而成,层间穿插过渡层,过渡层的具体操作为:
5.根据权利要求1或4所述的基于变分自编码器和特征重构的肺音识别方法,其特征在于,在肺音识别模型训练阶段,通过式(10)的加权损失函数计算模型损失;
技术总结本发明为一种基于变分自编码器和特征重构的肺音识别方法,首先获取肺音信号,并对肺音信号进行降噪;将降噪后的肺音信号划分片段,肺音信号片段转换为梅尔语谱图,作为肺音识别模型的输入图像;然后,构建肺音识别模型;肺音识别模型包括潜在表示推断与生成网络、时频特征编码与解码器以及分类模块;其中,潜在表示推断与生成网络包括推断网络和生成网络,时频特征编码与解码器包括时频特征编码器和时频特征解码器,分类模块包括基于分支注意力的时频特征增强模块和基于语义映射的融合语义分类器;最后,对肺音识别模型进行训练,并将训练后的肺音识别模型用于肺音识别,得到预测标签。在分类模块中,通过通过精准划分已知类和未知类的判定边界,能够准确地将未知类别标记为“未知”或“其他”,实现开集肺音识别。技术研发人员:张敬业,石陆魁,司称勇,段声旺,赖沁本,高乙轩,苗春睿受保护的技术使用者:河北工业大学技术研发日:技术公布日:2024/5/12本文地址:https://www.jishuxx.com/zhuanli/20240618/24065.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。