一种隐私保护的语音识别方法
- 国知局
- 2024-06-21 11:53:31
本发明涉及云计算和隐私计算的,尤其是指一种隐私保护的语音识别方法。
背景技术:
1、同态加密是一类具有特殊自然属性的加密方法,具有经过同态加密的数据进行处理后解密的结果与用同一方法处理未加密的原始数据的结果一致的特点。同态加密不仅具有安全性,还一定程度上保证了密态数据的可用性。
2、语音识别技术在多种应用场景中得到了广泛的应用,尤其是在智能助手、语音搜索和语音指令控制等领域。然而,语音识别过程中涉及到的用户语音数据可能包含个体的隐私信息。若这些数据被泄露,可能对个人带来不小的麻烦,并可能违反相关的隐私法规。使用高安全性的加密算法对这些语音数据进行加密确实可以增加其安全性。但是,加密后的语音数据可能无法直接进行语音识别或者进一步的语义分析,从而影响其实用性和功能性。目前,尚缺乏一种既能确保语音数据的安全,又能保持其识别和应用的可用性的有效解决方案。
技术实现思路
1、本发明的目的在于克服现有技术的缺点与不足,提出了一种隐私保护的语音识别方法,可以根据动态规划dtw算法实现孤立词识别与说话人识别等语音识别功能,可以对加密后的语音数据进行分析等计算操作,具有安全性和可用性。
2、为实现上述目的,本发明所提供的技术方案为:一种隐私保护的语音识别方法,包括以下步骤:
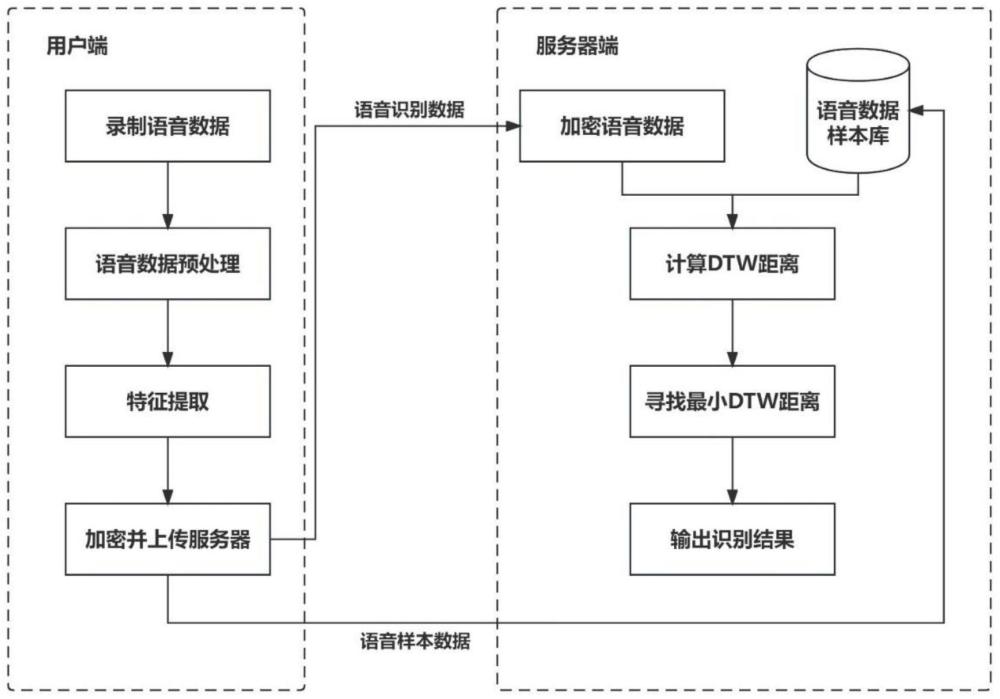
3、s1:通过用户端设备收集用户的语音数据,将语音数据进行预处理得到语音内容清晰、完整的语音数据;
4、s2:对预处理后的语音数据进行特征提取,得到重新编码后的语音数据;
5、s3:将编码后的语音数据进行加密并上传至服务器;
6、s4:基于动态规划dtw算法,服务器计算并查找服务器中语音数据样本与用户上传的加密语音数据的dtw距离最小值,并将该语音数据样本的标签作为语音识别结果。
7、进一步,在步骤s1中,将语音数据进行预处理,包括:语音分帧、语音预加重和语音端点检测,其中,所述语音预加重是通过一个一阶高通滤波器滤除低频干扰,所述语音端点检测是采用双门限法进行端点检测,截取出音频的起始点与终止点。
8、进一步,在步骤s2中,对预处理后的语音数据进行特征提取,采用以下操作:快速傅里叶变换、mel滤波器、对数运算、离散余弦变换和mfcc动态特征提取,得到重新编码后的语音数据;重新编码后的语音数据形式上表示为:x=(x1,x2,...,xi,...,x|x|),其中向量xi的维度与mfcc动态特征所提取的特征数相关,|x|表示语音数据x的长度。
9、进一步,在步骤s3中,将编码后的语音数据进行加密并上传至服务器,具体操作是:采用paillier加密算法对每个向量xi的每个维度的特征值进行加密,构成加密后的语音数据,并将其上传至服务器;其中,paillier加密算法表示为:
10、
11、式中,m表示待加密的数字,r为随机生成的随机数,g、n为公开的公钥,为两个超大整数,公钥由服务器端公开获取。
12、进一步,步骤s4的具体操作步骤如下:
13、s4.1:随机选取服务器中的一个语音数据样本并计算其与用户上传的加密语音数据的dtw距离最小值作为当前最优值best。密文dtw距离的计算过程,形式上表示为:
14、
15、式中,best为服务器中的语音数据样本与用户上传的加密语音数据的dtw距离最小值,即当前最优值,为语音数据所选取的服务器中的语音数据样本与用户上传的加密语音数据的dtw距离,|x0|、|y|分别表示语音数据x0和语音数据y的长度,为dtw计算过程中产生的二维矩阵,δi,j为计算过程的中间值,f3cmp(mdist[i,j])为对于mdist[i,j]所表示值的比较协议,mdist[i,j]为存储欧几里得距离的二维矩阵,为计算加密向量与加密向量的欧几里得距离,和分别表示服务器中的语音数据样本的第i个向量与用户上传的加密语音数据的第j个向量;
16、s4.2:服务器计算并查找服务器中语音数据样本与用户上传的加密语音数据的dtw距离最小值,具体操作是:逐个计算语音数据样本与用户上传的加密语音数据keogh’slower bound距离,与当前最优值best进行比较。若大于当前最优值best,则计算下一个语音数据样本与用户上传的加密语音数据keogh’s lower bound距离,若小于当前最优值best,则计算该语音数据样本与用户上传的加密语音数据dtw距离,若该距离仍小于当前最优值best,则利用该距离更新当前最优值best,反之继续执行;
17、其中,逐个计算服务器中的第k个语音数据样本与用户上传的加密语音数据的keogh’s lower bound距离,计算过程形式上表示为:
18、
19、
20、
21、
22、
23、
24、
25、式中,分别表示语音数据样本中的第i-1个、i个、i+1个向量,表示加密语音数据中的第i个向量,表示中的最小值,表示中的最大值,αi表示比较与的大小,βi表示比较与的大小,表示计算与的欧几里得距离,表示计算与的欧几里得距离,lb(xk,y)表示服务器中的第k个语音数据样本与用户上传的加密语音数据的keogh’s lower bound距离,|xk|表示语音数据样本的长度;
26、s4.3:根据步骤s4.2中所计算的当前最优值best,当其值大于服务器所设置的阈值时,服务器输出识别结果为识别失败;当其值小于服务器所设置的阈值时,寻找当前最优值best所对应的语音数据样本,服务器输出识别结果为该语音数据样本的标签。
27、本发明与现有技术相比,具有如下优点和有益效果:
28、1、本发明能够实现安全且高效地语音识别功能。
29、2、本发明创新性地提出基于paillier加密算法的密文比较协议,实现了高效的密文比较方法与计算协议,攻克了密态语音数据计算复杂度高、计算开销大的难题。
30、3、本发明通过设计精妙的密文dtw距离计算协议,实现了对于密文语音数据的dtw距离计算,大幅减少了通信开销与计算时间。
31、4、本发明进一步设计了最小dtw距离查找算法,基于keogh’s lower bound距离,进一步优化了查找最小dtw距离的复杂度,提高服务器的运行效率。
32、5、本发明大幅减少了服务器与客户端的通信开销与密文语音数据计算的时间,为在广域网内使用隐私保护的语音识别技术奠定了理论基础,实现了高效的语音识别功能,同时兼具安全性与可用性。
技术特征:1.一种隐私保护的语音识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种隐私保护的语音识别方法,其特征在于,在步骤s1中,将语音数据进行预处理,包括:语音分帧、语音预加重和语音端点检测,其中,所述语音预加重是通过一个一阶高通滤波器滤除低频干扰,所述语音端点检测是采用双门限法进行端点检测,截取出音频的起始点与终止点。
3.根据权利要求2所述的一种隐私保护的语音识别方法,其特征在于,在步骤s2中,对预处理后的语音数据进行特征提取,采用以下操作:快速傅里叶变换、mel滤波器、对数运算、离散余弦变换和mfcc动态特征提取,得到重新编码后的语音数据;重新编码后的语音数据形式上表示为:x=(x1,x2,...,xi,...,x|x|),其中向量xi的维度与mfcc动态特征所提取的特征数相关,|x|表示语音数据x的长度。
4.根据权利要求3所述的一种隐私保护的语音识别方法,其特征在于,在步骤s3中,将编码后的语音数据进行加密并上传至服务器,具体操作是:采用paillier加密算法对每个向量xi的每个维度的特征值进行加密,构成加密后的语音数据,并将其上传至服务器;其中,paillier加密算法表示为:
5.根据权利要求4所述的一种隐私保护的语音识别方法,其特征在于,步骤s4的具体操作步骤如下:
技术总结本发明公开了一种隐私保护的语音识别方法,包括:通过用户端设备收集用户的语音数据,将语音数据进行预处理得到语音内容清晰、完整的语音数据;对预处理后的语音数据进行特征提取,得到重新编码后的语音数据;将编码后的语音数据进行加密并上传至服务器;基于动态规划DTW算法,服务器计算并查找服务器中语音数据样本与用户上传的加密语音数据的DTW距离最小值,并将该语音数据样本的标签作为语音识别结果。本发明可以根据动态规划DTW算法实现孤立词识别与说话人识别等语音识别功能,可以对加密后的语音数据进行分析等计算操作,具有安全性和可用性。技术研发人员:赵搏文,黄梓熙,汤冬儿,赵汝强,林霆枫,邓从健,祝遥,肖阳,裴庆祺受保护的技术使用者:西安电子科技大学技术研发日:技术公布日:2024/5/27本文地址:https://www.jishuxx.com/zhuanli/20240618/24304.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
乐器用螺母的制作方法
下一篇
返回列表