口语化方言合成方法、系统、终端及存储介质与流程
- 国知局
- 2024-06-21 11:54:07
本发明涉及语音处理,尤其涉及一种口语化方言合成方法、系统、终端及存储介质。
背景技术:
1、中国方言是汉语的分支,中国地域广阔,汉语的方言众多。汉族社会在发展过程中出现过程度不同的分化和统一,因而使汉语逐渐产生了方言。现代汉语各方言之间的差异表现在语音、词汇、语法各个方面,语音方面尤为突出。随着人口流动性增大,由于每个地区都有自己独特的语言发音,不同地区的人互相之间听不懂,因此,方言合成的问题越来越受人们所重视。
2、目前具有翻译功能的产品都是不同语种语音之间的转换,而没有涉及标准书面语与方言口语语音之间转换,因此,如何实现标准书面语与方言口语语音之间转换是目前亟需解决的问题。
技术实现思路
1、本发明实施例的目的在于提供一种口语化方言合成方法、系统、终端及存储介质,旨在解决如何实现标准书面语与方言口语语音之间转换的问题。
2、本发明实施例是这样实现的,一种口语化方言合成方法,所述方法包括:
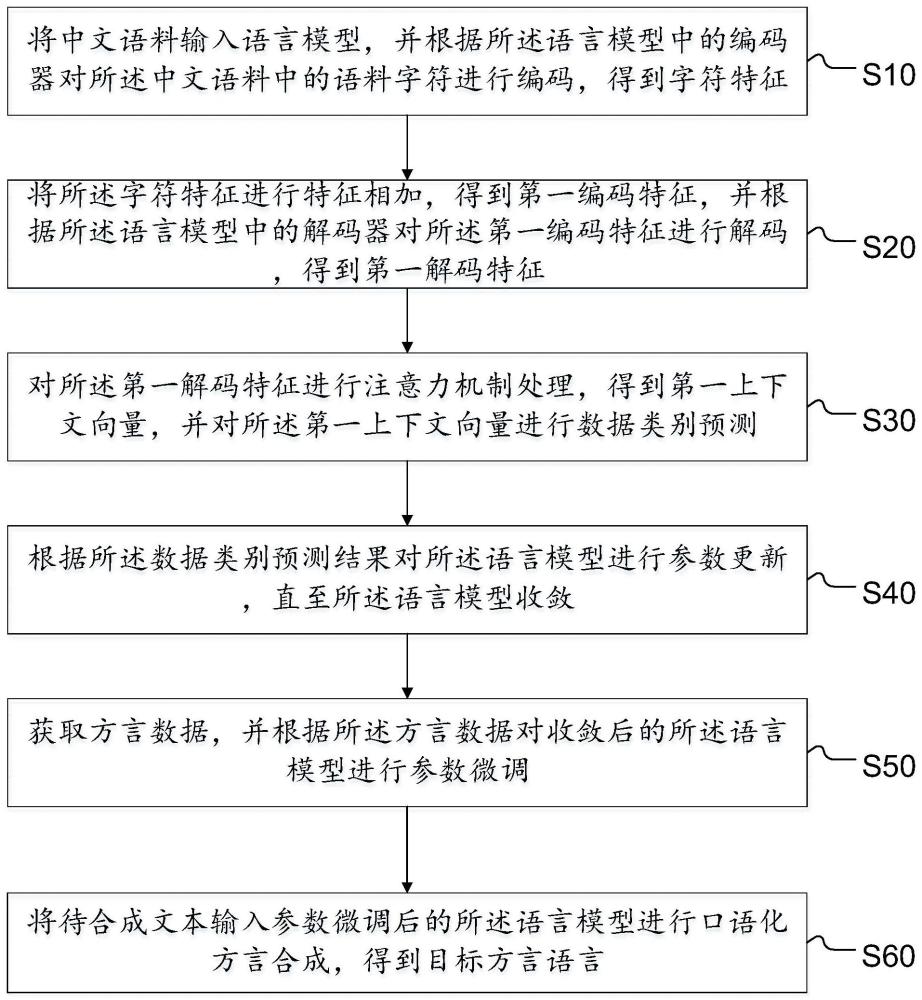
3、将中文语料输入语言模型,并根据所述语言模型中的编码器对所述中文语料中的语料字符进行编码,得到字符特征;
4、将所述字符特征进行特征相加,得到第一编码特征,并根据所述语言模型中的解码器对所述第一编码特征进行解码,得到第一解码特征;
5、对所述第一解码特征进行注意力机制处理,得到第一上下文向量,并对所述第一上下文向量进行数据类别预测;
6、根据所述数据类别预测结果对所述语言模型进行参数更新,直至所述语言模型收敛;
7、获取方言数据,并根据所述方言数据对收敛后的所述语言模型进行参数微调,参数微调过程中解码器解码每一步输出时所使用的查询向量为限制长度的序列;
8、将待合成文本输入参数微调后的所述语言模型进行口语化方言合成,得到目标方言语言。
9、优选的,根据所述方言数据对收敛后的所述语言模型进行参数微调,包括:
10、将所述方言数据输入收敛后的所述语言模型中的编码器进行编码,得到方言特征,并将所述方言特征进行特征相加,得到第二编码特征;
11、根据预设长度分别确定所述第二编码特征中各字符特征对应的目标查询矩阵;
12、根据收敛后的所述语言模型中的解码器和所述目标查询矩阵对所述第二编码特征进行解码,得到第二解码特征;
13、对所述第二解码特征进行注意力机制处理,得到第二上下文向量,并对所述第二上下文向量进行数据类别预测;
14、根据所述第二上下文向量的数据类别预测结果对收敛后的所述语言模型进行参数微调。
15、优选的,对所述第一解码特征进行注意力机制处理,得到第一上下文向量,包括:
16、根据所述第一解码特征确定查询矩阵,并根据所述查询矩阵确定对齐向量;
17、根据所述对齐向量进行特征加权融合,得到所述第一上下文向量。
18、优选的,所述语言模型中的解码器正向采用删除了遗忘门线路的长短期记忆网络结构,反向采用gru结构。
19、优选的,根据所述方言数据对收敛后的所述语言模型进行参数微调之后,还包括:
20、将参数微调后的所述语言模型与tts模块进行组合。
21、优选的,所述语言模型采用字进行建模,所述语言模型中的编码器和解码器的词嵌入之间共享参数。
22、本发明实施例的另一目的在于提供一种口语化方言合成系统,所述系统包括:
23、编码模块,用于将中文语料输入语言模型,并根据所述语言模型中的编码器对所述中文语料中的语料字符进行编码,得到字符特征;
24、解码模块,用于将所述字符特征进行特征相加,得到第一编码特征,并根据所述语言模型中的解码器对所述第一编码特征进行解码,得到第一解码特征;
25、注意力模块,用于对所述第一解码特征进行注意力机制处理,得到第一上下文向量,并对所述第一上下文向量进行数据类别预测;
26、参数更新模块,用于根据所述数据类别预测结果对所述语言模型进行参数更新,直至所述语言模型收敛;
27、参数微调模块,用于获取方言数据,并根据所述方言数据对收敛后的所述语言模型进行参数微调,参数微调过程中解码器解码每一步输出时所使用的查询向量为限制长度的序列;
28、方言合成模块,用于将待合成文本输入参数微调后的所述语言模型进行口语化方言合成,得到目标方言语言。
29、优选的,所述参数微调模块还用于:
30、将所述方言数据输入收敛后的所述语言模型中的编码器进行编码,得到方言特征,并将所述方言特征进行特征相加,得到第二编码特征;
31、根据预设长度分别确定所述第二编码特征中各字符特征对应的目标查询矩阵;
32、根据收敛后的所述语言模型中的解码器和所述目标查询矩阵对所述第二编码特征进行解码,得到第二解码特征;
33、对所述第二解码特征进行注意力机制处理,得到第二上下文向量,并对所述第二上下文向量进行数据类别预测;
34、根据所述第二上下文向量的数据类别预测结果对收敛后的所述语言模型进行参数微调。
35、本发明实施例的另一目的在于提供一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述方法的步骤。
36、本发明实施例的另一目的在于提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
37、本发明实施例,使用中文语料训练语言模型,能够从中文的训练集中得到合适的词向量映射,减小了词袋的大小,进而减小了语言模型的参数量,避免了方言词典的收集,通过将字符特征进行特征相加得到第一编码特征,有效地降低了语言模型中模块的参数量,基于方言数据对收敛后的语言模型进行参数微调,有效降低了语言模型中数据推理的运算量,加快了语言模型的数据处理效率,基于参数微调后的语言模型,能有效地将标准书面语转换为方言语言,有效解决了标准书面语与方言语言之间的转换问题。
技术特征:1.一种口语化方言合成方法,其特征在于,所述方法包括:
2.如权利要求1所述的口语化方言合成方法,其特征在于,根据所述方言数据对收敛后的所述语言模型进行参数微调,包括:
3.如权利要求1所述的口语化方言合成方法,其特征在于,对所述第一解码特征进行注意力机制处理,得到第一上下文向量,包括:
4.如权利要求1所述的口语化方言合成方法,其特征在于,所述语言模型中的解码器正向采用删除了遗忘门线路的长短期记忆网络结构,反向采用gru结构。
5.如权利要求1所述的口语化方言合成方法,其特征在于,根据所述方言数据对收敛后的所述语言模型进行参数微调之后,还包括:
6.如权利要求1至5任一所述的口语化方言合成方法,其特征在于,所述语言模型采用字进行建模,所述语言模型中的编码器和解码器的词嵌入之间共享参数。
7.一种口语化方言合成系统,其特征在于,所述系统包括:
8.如权利要求7所述的口语化方言合成系统,其特征在于,所述参数微调模块还用于:
9.一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至6任一项所述方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至6任一项所述方法的步骤。
技术总结本发明提供了一种口语化方言合成方法、系统、终端及存储介质,该方法包括:根据语言模型中的编码器对中文语料中的语料字符进行编码,得到字符特征;将字符特征进行特征相加,得到第一编码特征,根据语言模型中的解码器对第一编码特征进行解码,得到第一解码特征;对第一解码特征进行注意力机制处理,得到第一上下文向量,对第一上下文向量进行数据类别预测;根据数据类别预测结果对语言模型进行参数更新,直至语言模型收敛;根据方言数据对收敛后的语言模型进行参数微调;将待合成文本输入参数微调后的语言模型进行口语化方言合成,得到目标方言语言。本发明实施例,基于参数微调后的语言模型,有效解决了标准书面语与方言语言之间的转换问题。技术研发人员:郁祖达,孙见青,梁家恩,朱洪泽受保护的技术使用者:云知声(上海)智能科技有限公司技术研发日:技术公布日:2024/5/29本文地址:https://www.jishuxx.com/zhuanli/20240618/24366.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。