声纹识别模型的训练方法、声纹识别方法及装置与流程
- 国知局
- 2024-06-21 11:54:29
本发明涉及声纹识别领域,具体涉及一种声纹识别模型的训练方法、声纹识别方法及装置。
背景技术:
1、每个人的声音都蕴涵着特有的生物特征,声纹识别是指利用说话人的声音来识别说话人的一种技术手段。声纹识别同指纹识别等技术一样具有高度的安全可靠性,可以应用在所有需要做身份识别的场合。如在刑侦、银行、证券、保险等领域。与传统的身份识别技术相比,声纹识别的优势在于,声纹提取过程简单,成本低,且具有唯一性,不易伪造和假冒。近几年,随着深度学习技术的发展,声纹识别技术也得到了较大的提升,已经成功应用在很多场景。但是目前深度学习方法训练模型存在一定的局限性,声纹识别模型的抗噪声能力比较差,在室外或者噪声比较大的场景下,声纹识别准确率会受到比较大影响,往往需要用户在比较安静的环境下做声纹比对。在有一些应用场合,由于模型抗噪声能力的弱点,给声纹识别系统的推广应用带来了一定的阻碍。
技术实现思路
1、针对上述提到的技术问题。本技术的实施例的目的在于提出了一种声纹识别模型的训练方法、声纹识别方法及装置,来解决以上背景技术部分提到的技术问题。
2、第一方面,本发明提供了一种声纹识别模型的训练方法,包括以下步骤:
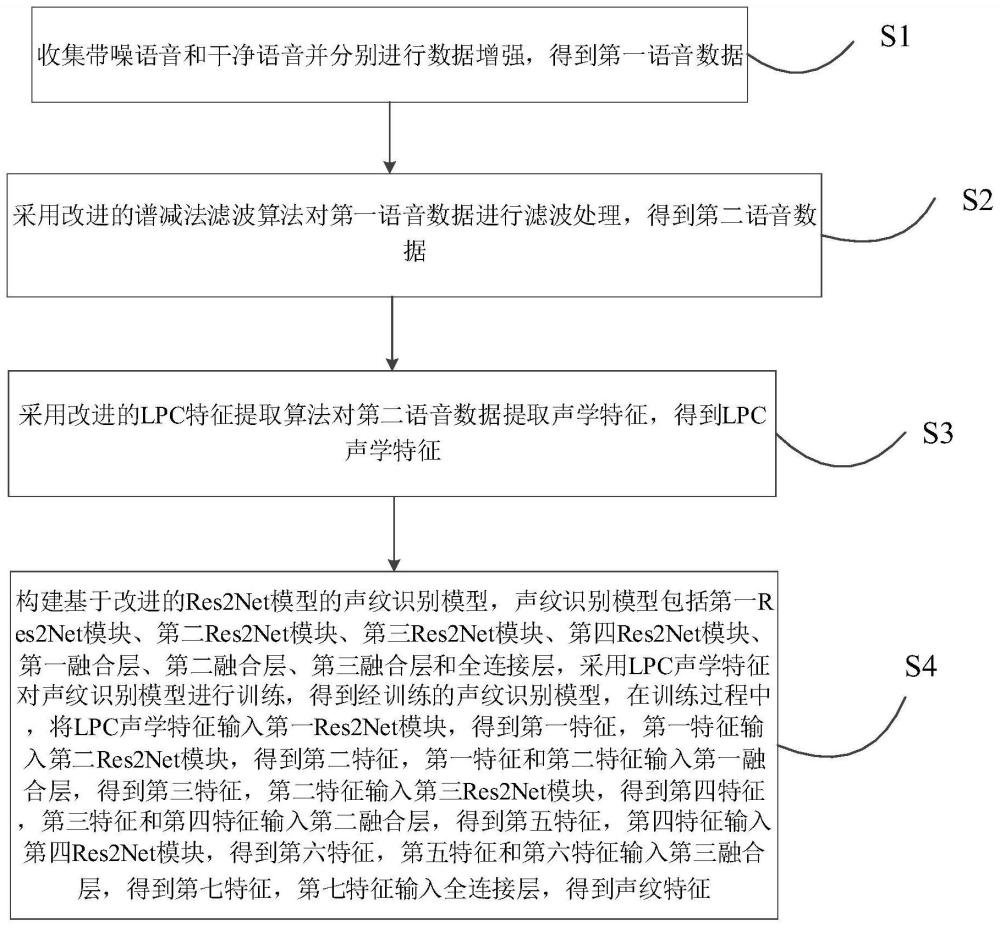
3、收集带噪语音和干净语音并分别进行数据增强,得到第一语音数据;
4、采用改进的谱减法滤波算法对第一语音数据进行滤波处理,得到第二语音数据;
5、采用改进的lpc特征提取算法对第二语音数据提取声学特征,得到lpc声学特征;
6、构建基于改进的res2net模型的声纹识别模型,声纹识别模型包括第一res2net模块、第二res2net模块、第三res2net模块、第四res2net模块、第一融合层、第二融合层、第三融合层和全连接层,采用lpc声学特征对声纹识别模型进行训练,得到经训练的声纹识别模型,在训练过程中,将lpc声学特征输入第一res2net模块,得到第一特征,第一特征输入第二res2net模块,得到第二特征,第一特征和第二特征输入第一融合层,得到第三特征,第二特征输入第三res2net模块,得到第四特征,第三特征和第四特征输入第二融合层,得到第五特征,第四特征输入第四res2net模块,得到第六特征,第五特征和第六特征输入第三融合层,得到第七特征,第七特征输入全连接层,得到声纹特征。
7、在具体的实施例中,第一融合层、第二融合层、第三融合层均采用融合模块,融合模块包括依次连接的加法器、卷积核大小为1×1的卷积层、第一平均池化层、relu激活函数层和第二平均池化层。
8、在具体的实施例中,采用改进的谱减法滤波算法对第一语音数据进行滤波处理,得到第二语音数据,具体包括:
9、建立干净语音、噪声和带噪语音之间的关系,并转换至频域,得到如下表达式:
10、
11、其中,y(w)为频域下的带噪信号,x(w)为频域下的干净信号,e(w)为频域下的噪声信号,γ和α为超参数,γ的取值范围为[1,4],α的取值范围为[0.5,1.0];
12、则干净信号的估计值如下式所示:
13、
14、其中,为干净信号的估计值,|y(w)|为带噪信号的幅度谱,为噪声谱,为信号相位。
15、在具体的实施例中,改进的lpc特征提取算法包括预加重、分帧、加窗、自相关分析、lpc分析和倒谱系数转换,其中对lpc分析过程进行改进,改进后的lpc分析过程如下:
16、当m=0时,e0=r(0),a0=1;
17、对于第m次的递归,存在:
18、
19、
20、对于j=1到m-1,存在:
21、
22、
23、其中,r为自相关系数,em为误差,km为反馈系数,a为lpc系数,p表示阶数,λ为滤波系数,取值范围为(0,1)。
24、在具体的实施例中,干净语音的数据增强方式包括:变速、加混响、加噪声和加音乐声,带噪语音的数据增强方式包括:变速、加混响和加音乐声。
25、第二方面,本发明提供了一种声纹识别模型的训练装置,包括:
26、数据增强模块,被配置为收集带噪语音和干净语音并分别进行数据增强,得到第一语音数据;
27、滤波处理模块,被配置为采用改进的谱减法滤波算法对第一语音数据进行滤波处理,得到第二语音数据;
28、声学特征提取模块,被配置为采用改进的lpc特征提取算法对第二语音数据提取声学特征,得到lpc声学特征;
29、模型构造训练模块,被配置为构建基于改进的res2net模型的声纹识别模型,声纹识别模型包括第一res2net模块、第二res2net模块、第三res2net模块、第四res2net模块、第一融合层、第二融合层、第三融合层和全连接层,采用lpc声学特征对声纹识别模型进行训练,得到经训练的声纹识别模型,在训练过程中,将lpc声学特征输入第一res2net模块,得到第一特征,第一特征输入第二res2net模块,得到第二特征,第一特征和第二特征输入第一融合层,得到第三特征,第二特征输入第三res2net模块,得到第四特征,第三特征和第四特征输入第二融合层,得到第五特征,第四特征输入第四res2net模块,得到第六特征,第五特征和第六特征输入第三融合层,得到第七特征,第七特征输入全连接层,得到声纹特征。
30、第三方面,本发明提供了一种声纹识别方法,采用如第一方面中任一实现方式训练得到的经训练的声纹识别模型,包括以下步骤:
31、获取注册语音,采用改进的谱减法滤波算法对注册语音进行滤波处理,得到注册语音对应的第二语音数据,并采用改进的lpc特征提取算法对注册语音对应的第二语音数据进行声学特征提取,得到注册语音对应的lpc声学特征,将注册语音对应的lpc声学特征输入经训练的声纹识别模型,得到第一特征向量;
32、获取验证语音,采用改进的谱减法滤波算法对验证语音进行滤波处理,得到验证语音对应的第二语音数据,并采用改进的lpc特征提取算法对得到验证语音对应的第二语音数据进行声学特征提取,得到验证语音对应的lpc声学特征,将验证语音对应的lpc声学特征输入经训练的声纹识别模型,得到第二特征向量;
33、将第一特征向量和第二特征向量进行相似度比对,得到比对结果,根据比对结果判断验证语音和注册语音是否属于同一人。
34、第四方面,本发明提供了一种声纹识别装置,采用如第一方面中任一实现方式训练得到的经训练的声纹识别模型,包括:
35、注册模块,被配置为获取注册语音,采用改进的谱减法滤波算法对注册语音进行滤波处理,得到注册语音对应的第二语音数据,并采用改进的lpc特征提取算法对注册语音对应的第二语音数据进行声学特征提取,得到注册语音对应的lpc声学特征,将注册语音对应的lpc声学特征输入经训练的声纹识别模型,得到第一特征向量;
36、验证模块,被配置为获取验证语音,采用改进的谱减法滤波算法对验证语音进行滤波处理,得到验证语音对应的第二语音数据,并采用改进的lpc特征提取算法对得到验证语音对应的第二语音数据进行声学特征提取,得到验证语音对应的lpc声学特征,将验证语音对应的lpc声学特征输入经训练的声纹识别模型,得到第二特征向量;
37、比对模块,被配置为将第一特征向量和第二特征向量进行相似度比对,得到比对结果,根据比对结果判断验证语音和注册语音是否属于同一人。
38、第五方面,本发明提供了一种电子设备,包括一个或多个处理器;存储装置,用于存储一个或多个程序,当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现如第一方面中任一实现方式描述的方法。
39、第六方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面中任一实现方式描述的方法。
40、相比于现有技术,本发明具有以下有益效果:
41、(1)本发明提出的声纹识别模型的训练方法中采用改进的谱减法滤波算法,可以有效的过滤语音的噪声信号,最大程度保留说话人声学特征。
42、(2)本发明提出的声纹识别模型的训练方法中采用经过改进的lpc特征提取算法提取到的lpc声学特征训练声纹识别模型,可以提升声纹识别模型的抗噪声能力。
43、(3)本发明提出的声纹识别方法在错误接受率上可以由原来的70%提升至80%,提升在各种室内外场景下的声纹识别准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24403.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
水下吸声装置及其系统
下一篇
返回列表