粤剧音频修复方法、装置、设备及介质
- 国知局
- 2024-06-21 11:54:51
本技术涉及音频修复领域,尤其涉及一种粤剧音频修复方法、相应的装置、电子设备及计算机可读存储介质。
背景技术:
1、受到历史条件和科学技术的限制,中国的传统音乐曾经只能通过师徒教授、乐谱记载的方式进行传播,这在文化的传承与传播上有很大的阻碍,容易发生粤剧曲目的失传。在二十世纪,黑胶唱片以及磁带的出现使得大量珍贵的粤剧大师的名篇的得以流传。由于存储介质的理化性质,在其长时间的储存过程中会出现不同程度的磨损、老化,若存放不当,则存储介质上也可能出现霉变、污渍或手印等痕迹,以及因早期录音技术、设备、环境等条件的限制,使得音频出现内容缺失、底噪大、清晰度低、分辨率低等问题。
2、目前,对于粤剧音频的修复,没有通用的自动化方法,普遍的修复流程是先将各种存储介质的进行数字化的转化,然后导入到音频处理软件中进行人工修复,如izotope、sonnox等。这种方式对修复人员的专业素质的要求特别高,不仅要对粤剧人声唱腔和背景配乐的特点非常熟悉,还要熟练掌握各种音频处理软件的使用,以应对复杂的音频损伤情况。在进行修复时也需要逐帧对音频进行音调恢复或降噪等调整,所消耗的时间也特别长。这样的修复方式不仅耗费大量的人力物力,而且效率低下,无法同时进行大量的修复工作,不能满足当下对粤剧文化保护的迫切需求。
3、综上,适应现有技术中对于粤剧音频的修复,没有通用的自动化方法,其修复消耗时间过长,效率低下以及消耗大量的人力物力等问题,本技术人出于解决该问题的考虑作出相应的探索。
技术实现思路
1、本技术的目的在于解决上述问题而提供一种粤剧音频修复方法、相应的装置、电子设备及计算机可读存储介质。
2、为满足本技术的各个目的,本技术采用如下技术方案:
3、适应本技术的目的之一而提出的一种粤剧音频修复方法,包括如下步骤:
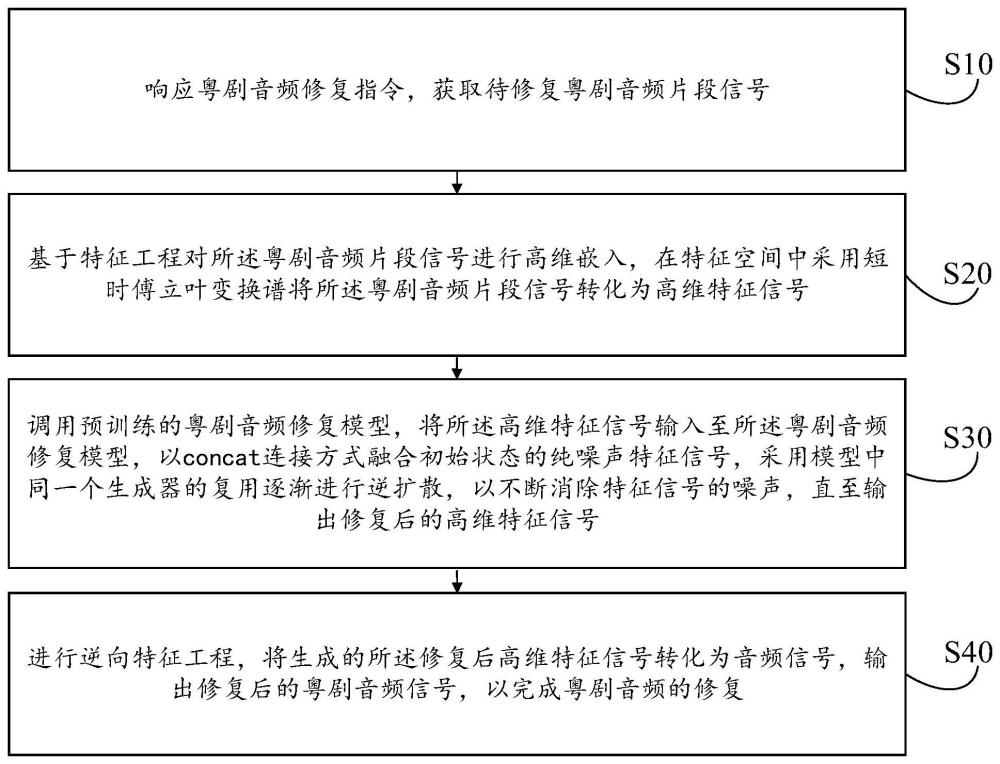
4、响应粤剧音频修复指令,获取待修复粤剧音频片段信号;
5、基于特征工程对所述粤剧音频片段信号进行高维嵌入,在特征空间中采用短时傅立叶变换谱将所述粤剧音频片段信号转化为高维特征信号;
6、调用预训练的粤剧音频修复模型,将所述高维特征信号输入至所述粤剧音频修复模型,以concat连接方式融合初始状态的纯噪声特征信号,采用模型中同一个生成器的复用逐渐进行逆扩散,以不断消除特征信号的噪声,直至输出修复后的高维特征信号;
7、进行逆向特征工程,将生成的所述修复后高维特征信号转化为音频信号,输出修复后的粤剧音频信号,以完成粤剧音频的修复。
8、可选的,调用预训练的粤剧音频修复模型,将所述高维特征信号输入至所述粤剧音频修复模型,以concat连接方式融合初始状态的纯噪声特征信号,采用模型中同一个生成器的复用逐渐进行逆扩散,以不断消除特征信号的噪声,直至输出修复后的高维特征信号的步骤之前,包括如下步骤:
9、将u-net结构的变分自编码器作为所述粤剧音频修复模型中的生成器,确定参数t作为扩散的总状态数,确定schedule函数s(t)以控制扩散和逆扩散过程中单步添加和消除的噪声程度,并确定随机数种子seed,以生成逆扩散的初始状态噪声。
10、可选的,调用预训练的粤剧音频修复模型,将所述高维特征信号输入至所述粤剧音频修复模型,以concat连接方式融合初始状态的纯噪声特征信号,采用模型中同一个生成器的复用逐渐进行逆扩散,以不断消除特征信号的噪声,直至输出修复后的高维特征信号的步骤,包括如下步骤:
11、采用schedule函数s(t)确定粤剧音频片段信号的每步噪声等级,将所述生成器进行复用,逐级生成最终的修复特征信号;
12、将第t步的中间特征输入至所述生成器,所述生成器输出同维度尺寸的第t-1步的中间特征,其中,第t步为初始状态,第0步为最终状态。
13、可选的,调用预训练的粤剧音频修复模型,将所述高维特征信号输入至所述粤剧音频修复模型,以concat连接方式融合初始状态的纯噪声特征信号,采用模型中同一个生成器的复用逐渐进行逆扩散,以不断消除特征信号的噪声,直至输出修复后的高维特征信号的步骤,包括如下步骤:
14、所述粤剧音频修复模型采用u-net结构的变分自编码器作为生成器,输入的高维特征信号经过所述粤剧音频修复模型的下采样块逐级将维度压缩降低,并对称地从支路将每级的输出输入相应的上采样块;
15、在所述粤剧音频修复模型的瓶颈块中进行同维度的特征变换,在所述粤剧音频修复模型的上采样块中结合支路与前一级的输入,逐级扩大高维特征信号的维度,以输出与输入同维度尺寸的特征信号。
16、可选的,训练所述粤剧音频修复模型的步骤,包括如下步骤:
17、确定粤剧音频修复模型的训练集,所述训练集由预先切片好的粤剧音频片段对组成,每个音频片段对包含一段高音质粤剧音频片段以及将其经过人为损伤处理后的音频片段;
18、确定预设的损失函数以及各个超参数,从所述训练集中取出一个音频片段对,将其中所含音频经特征工程转化为高维的特征信号对,并随机选择一个中间状态t;
19、以高音质音频对应的特征信号为目标最终状态,根据schedule函数计算出中间状态t和t-1的目标特征信号;
20、根据随机数种子seed生成一个合适维度的高斯噪声作为初始状态的特征信号;
21、将中间状态t的目标特征信号与受损音频的特征信号采用concat连接融合后,输入模型的生成器生成中间状态t-1的特征信号;
22、计算中间状态t-1的特征信号与目标特征信号的损失函数值,并通过合适的梯度下降方法进行一次对模型生成器参数的优化;
23、重复上述步骤,直至所述预设的损失函数的值逐渐降低并达到收敛状态,以完成所述粤剧音频修复模型的训练。
24、可选的,所述粤剧音频修复模型的基础网络架构为条件扩散模型。
25、可选的,所述粤剧音频修复模型的生成器采用u-net结构的变分自编码器,所述粤剧音频修复模型中的上采样块以及下采样块采用transformer模型进行深度特征提取,所述粤剧音频修复模型中的瓶颈块采用two-stage conformer模型。
26、适应本技术的另一目的而提供的一种粤剧音频修复装置,包括:
27、音频信号获取模块,设置为响应粤剧音频修复指令,获取待修复粤剧音频片段信号;
28、音频信号转化模块,设置为基于特征工程对所述粤剧音频片段信号进行高维嵌入,在特征空间中采用短时傅立叶变换谱将所述粤剧音频片段信号转化为高维特征信号;
29、逆扩散模块,设置为调用预训练的粤剧音频修复模型,将所述高维特征信号输入至所述粤剧音频修复模型,以concat连接方式融合初始状态的纯噪声特征信号,采用模型中同一个生成器的复用逐渐进行逆扩散,以不断消除特征信号的噪声,直至输出修复后的高维特征信号;
30、音频修复模块,设置为进行逆向特征工程,将生成的所述修复后高维特征信号转化为音频信号,输出修复后的粤剧音频信号,以完成粤剧音频的修复。
31、适应本技术的另一目的而提供的一种电子设备,包括中央处理器和存储器,所述中央处理器用于调用运行存储于所述存储器中的计算机程序以执行本技术所述粤剧音频修复方法的步骤。
32、适应本技术的另一目的而提供的一种计算机可读存储介质,其以计算机可读指令的形式存储有依据所述粤剧音频修复方法所实现的计算机程序,该计算机程序被计算机调用运行时,执行相应的方法所包括的步骤。
33、相对于现有技术,本技术针对现有技术中对于粤剧音频的修复,没有通用的自动化方法,其修复消耗时间过长,效率低下以及消耗大量的人力物力等问题,本技术包括但不限于如下有益效果:
34、其一,通过深度学习的方法可以将粤剧音频的修复工作实现了自动化,节约了大量的人力资源成本,大大提高了粤剧音频修复的工作效率,而在自动化音频修复的领域内,与结构简单的语音音频相比,本技术克服了成分复杂、深层信息多、隐特征高度结构化的特点,提供了一种高精度、高鲁棒性的修复方法,修复的准确度更高,这将为听众带来更好更便捷的听曲体验,进一步推动粤剧文化的传承;
35、其二,深度学习的方法被引入到音频的数字化修复当中,为粤剧音频的修复打开了新的思路,通过训练神经网络模型来实现粤剧音频修复的自动化,可以大大减少人力,提高修复的效率。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24438.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表