一种利用非平行语料提升语音识别系统性能的方法与流程
- 国知局
- 2024-06-21 11:54:49
本发明涉及语音识别领域,具体涉及一种利用非平行语料提升语音识别系统性能的方法。
背景技术:
1、语音识别技术是一种将人类语音转换为文字的技术,允许计算机识别和理解人类语言的口头表达,近年来广泛地应用在各种实际场景之中。
2、语音识别系统在训练时往往需要大量成对的语音-文本形式的标注训练数据,标注数据的获取成本十分高昂。语音识别模型接触的语音数据不足,就会导致其对语音特征的提取能力受到限制,语音分类准确率下降;语音识别模型接触的文本数据不足,就会导致其文本生成能力不足,识别结果不满足人类的语法规则。
3、近年来,自监督学习技术得到了飞速的发展,相比于有监督学习需要大量的标注数据,自监督学习旨在从未标记的数据中学习信息表示。利用海量无标注数据进行自监督预训练,利用少量有标注数据进行有监督微调训练表征学习,在语音识别领域有着非常好的效果。
4、为了解决语音识别领域存在的问题,本专利利用自监督学习技术,提出了一种新颖的方法,利用非平行语料提升语音识别系统性能。
技术实现思路
1、本申请提出一种利用非平行语料语音提升语音识别系统性能的方法,为了提升识别准确性,通过使用无标注的语音预训练语音识别编码器,利用语音信号的自相关特性,提升识别模型的特征提取能力;通过使用非成对的文本预训练语音识别解码器,利用文本的先验分布提升识别模型的文本建模能力以及编码器-解码器联合微调技术。本申请提供了一种通过充分利用非平行语料,提升语音识别准确性,从而可以为语音识别应用带来更为可靠和高效的解决方案。为了实现上述目的,本发明采用了如下技术方案:
2、一种利用非平行语料提升语音系统识别性能的方法,步骤包括:
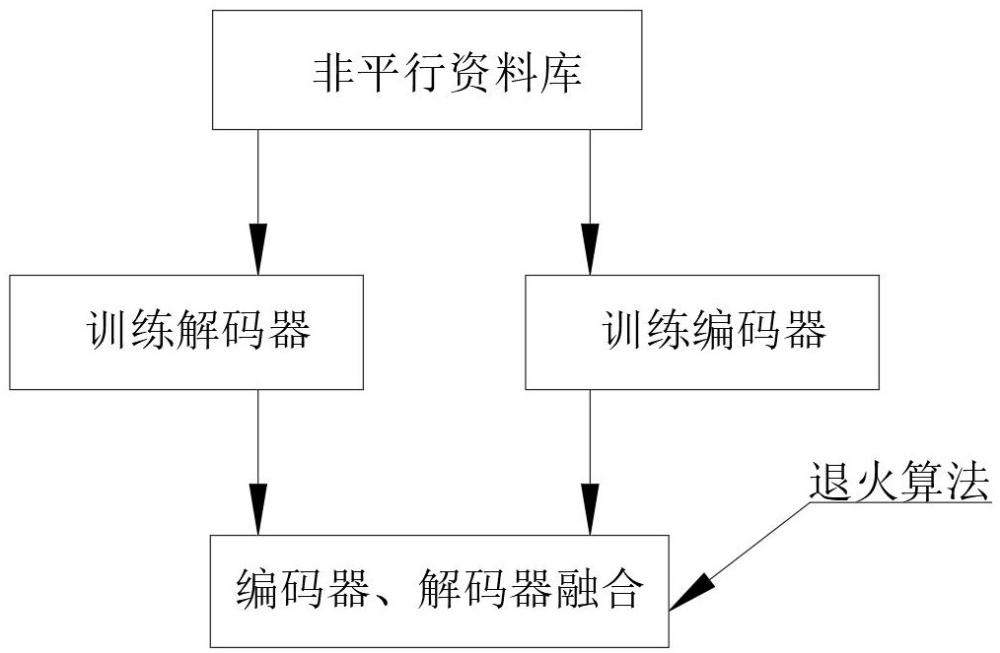
3、s1:收集包含大量语音和文本的非平行语料,这些语料获取来源包括互联网、社交媒体、广播节目等,建立非平行资源库;
4、s2:基于无标注语音预训练编码器;
5、s3:基于非平行文本库训练语音识别解码器;
6、s4:将步骤s2和步骤s3中训练得到的模型进行融合,实现编码器、解码器联合微调,在解码器的输入端增加一定能量的噪声,并在其输出端的标注的标签上增加了一定比例语言模型的软标签,且噪声与软标签的比例会随训练的迭代数逐渐降低,随着训练迭代数的增加,解码器逐渐转换为一个给定音频表征的语音识别器;
7、s5:将s4得到的模型应用到语音识别系统,最终提升语音识别系统的性能。
8、优选的,步骤s2中的编码器基于非平行资源库训练,训练方法包括以下步骤:
9、首先,使用一维卷积对非平行语料库中的原始语音进行特征提取,原始语音信号经过fbank特征提取后得到特征矩阵x;
10、然后,通过transformer模型提取上下文特征。
11、优选的,提取特征矩阵中,引入了非线性特征,应用非线性激活函数来引入非线性特征。
12、优选的,训练transformer模型之前在序列中添加了位置信息,并且对于上下文特征h进行掩蔽操作,将掩蔽后的上下文特征送入量化模块q,得到量化后的特征矩阵。
13、优选的,在训练transformer模型时还会判断上下文特征与量化特征的时序关系,在极大化相同时刻特征的相似度的同时极小化其他时刻特征间的相似度,用于平衡相同时刻特征的相似度和不同时刻特征的差异性,定义损失函数如下;
14、;
15、其中,t是帧长,表示上下文特征h和量化特征之间的相似度度量,是权衡因子。
16、优选的,步骤s3中,首先构建语音识别系统的信道模型,之后解码器根据音频特征h对文本数据y进行恢复;其中,提出了噪声条件语言模型,放弃对p的模拟,直接使用噪声来代替语音特征h。
17、优选的,在融合编码器、解码器模型中,在解码器的输入端增加了能量噪声,并在其输出端的标注的标签上增加了一定比例语言模型的软标签,且噪声与软标签的比例会随训练的迭代数逐渐降低,随着训练迭代数的增加,解码器逐渐转换为一个给定音频表征的语音识别器,使用模拟退火算法优化语音识别系统模型,避免陷入局部最优解。
18、本发明与现有技术相比具有以下优点:
19、1、收集了大量非平行语料库,利用无标注语音预训练编码器和非平行文本库训练语音识别解码器,提高了语音识别系统的性能和泛化能力。
20、2、通过编码器、解码器的联合微调,在训练过程中逐步减小噪声和软标签的比例,平衡模型的训练过程,提升模型的准确性和鲁棒性。
21、3、在特征提取中引入非线性特征,通过非线性激活函数来增强模型的表现和特征的多样性,提高了语音识别的准确性。
22、4、通过判断上下文特征和量化特征的时序关系,更好地捕捉音频表征到文本数据的映射关系,提高模型的学习能力和泛化能力。
23、5、使用了模拟退火算法优化模型,在解码器训练中引入能量噪声和语言模型的软标签,通过逐渐降低噪声和软标签的比例,避免模型陷入局部最优解,提高模型的稳定性和性能。
技术特征:1.一种利用非平行语料提升语音系统识别性能的方法,其特征在于,步骤包括:
2.根据权利要求1所述的利用非平行语料提升语音系统识别性能的方法,其特征在于,步骤s2中的编码器基于非平行资源库训练,训练方法包括以下步骤:
3.根据权利要求2所述的利用非平行语料提升语音系统识别性能的方法,其特征在于,提取特征矩阵中,引入了非线性特征,应用非线性激活函数来引入非线性特征。
4.根据权利要求3所述的利用非平行语料提升语音系统识别性能的方法,其特征在于,训练transformer模型之前在序列中添加了位置信息,并且对于上下文特征h进行掩蔽操作,将掩蔽后的上下文特征送入量化模块q,得到量化后的特征矩阵。
5.根据权利要求2所述的利用非平行语料提升语音系统识别性能的方法,其特征在于,在训练transformer模型时还会判断上下文特征与量化特征的时序关系,在极大化相同时刻特征的相似度的同时极小化其他时刻特征间的相似度,用于平衡相同时刻特征的相似度和不同时刻特征的差异性,定义损失函数如下;
6.根据权利要求1所述的利用非平行语料提升语音系统识别性能的方法,其特征在于,步骤s3中,首先构建语音识别系统的信道模型,之后解码器根据音频特征h对文本数据y进行恢复;其中,提出了噪声条件语言模型,放弃对p的模拟,直接使用噪声来代替语音特征h。
7.根据权利要求1所述的利用非平行语料提升语音系统识别性能的方法,其特征在于,在融合编码器、解码器模型中,在解码器的输入端增加了能量噪声,并在其输出端的标注的标签上增加了软标签,且噪声与软标签的比例会随训练的迭代数逐渐降低,随着训练迭代数的增加,解码器逐渐转换为一个给定音频表征的语音识别器,使用模拟退火算法优化语音识别系统模型,避免陷入局部最优解。
技术总结本发明公开了一种利用非平行语料提升语音识别系统性能的方法,涉及语音识别技术领域,步骤包括:收集包含大量语音和文本的非平行语料,这些语料获取来源包括互联网、社交媒体、广播节目等,建立非平行资源库;基于无标注语音预训练编码器;基于非平行文本库训练语音识别解码器;将训练得到的模型进行融合,实现编码器、解码器联合微调,在解码器的输入端增加一定能量的噪声,并在其输出端的标注的标签上增加了一定比例语言模型的软标签,且噪声与软标签的比例会随训练的迭代数逐渐降低,随着训练迭代数的增加,解码器逐渐转换为一个给定音频表征的语音识别器;将模型应用到语音识别系统,最终提升语音识别系统的性能。技术研发人员:严宇平,阮伟聪,林嘉鑫,林浩,邵彦宁,卫潮冰,陈泽鸿,胡波,吴文远,吴石松受保护的技术使用者:广东电网有限责任公司技术研发日:技术公布日:2024/5/29本文地址:https://www.jishuxx.com/zhuanli/20240618/24434.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表