一种基于多模态的声音动态识别方法
- 国知局
- 2024-06-21 11:54:49
本发明涉及声音识别,具体涉及一种基于多模态的声音动态识别方法。
背景技术:
1、
2、现有的小蜜蜂扩音器存在着弊端,不能识别指定对象的声音从而仅对指定对象进行扩音,降低无效背景噪音的干扰,现有的声音识别方法多采用参照匹配算法,利用事先存储的声音作参照进行实时接收声音的识别,以实现在实时声音中标记出指定对象声音,但该种识别模式并不适用于指定对象声音样本未知或者指定对象声音样本数较少的情况,指定对象声音样本未知或者指定对象声音样本数较少的情况会导致设置为参照的指定对象声音的表征性不足,进而导致声音识别的精度效果较差。
技术实现思路
1、本发明的目的在于提供一种基于多模态的声音动态识别方法,以解决现有技术中指定对象声音样本未知或者指定对象声音样本数较少的情况会导致设置为参照的指定对象声音的表征性不足,导致声音识别的精度效果较差的技术问题。
2、为解决上述技术问题,本发明具体提供下述技术方案:
3、一种基于多模态的声音动态识别方法,包括以下步骤:
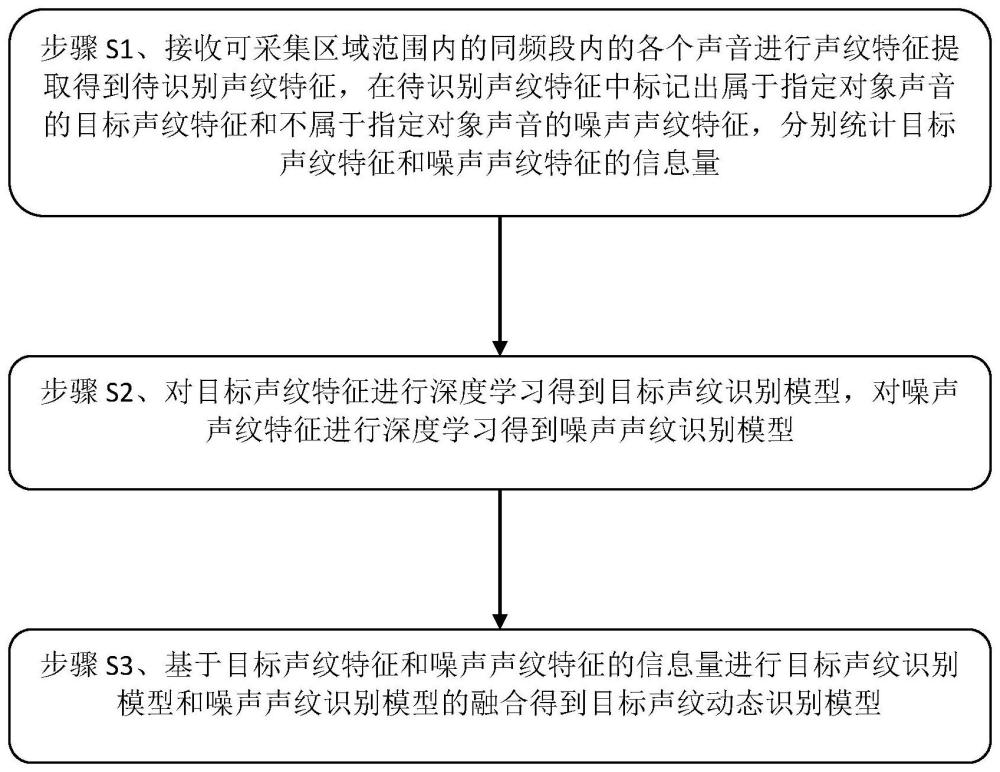
4、步骤s1、接收可采集区域范围内的同频段内的各个声音进行声纹特征提取得到待识别声纹特征,在待识别声纹特征中标记出属于指定对象声音的目标声纹特征和不属于指定对象声音的噪声声纹特征,分别统计目标声纹特征和噪声声纹特征的信息量;
5、步骤s2、对目标声纹特征进行深度学习得到目标声纹识别模型,对噪声声纹特征进行深度学习得到噪声声纹识别模型;
6、步骤s3、基于目标声纹特征和噪声声纹特征的信息量进行目标声纹识别模型和噪声声纹识别模型的融合得到目标声纹动态识别模型,以实现目标声纹的精准性与声音识别阶段的动态适配。
7、作为本发明的一种优选方案,分别利用lpcc特征提取算法和mfcc特征提取算法提取可采集区域范围内的同频段内的各个声音的lpcc特征和mfcc特征作为可采集区域范围内的同频段内的各个声音的待识别声纹特征。
8、作为本发明的一种优选方案,所述在待识别声纹特征中标记出属于指定对象声音的目标声纹特征和不属于指定对象声音的噪声声纹特征,包括:
9、将可采集区域范围内的同频段内的各个声音的待识别声纹特征进行聚类运算得到多个声纹特征簇,并在多个声纹特征簇中筛选出属于指定对象声音的声纹特征簇作为所述目标声纹特征;
10、将多个声纹特征簇中除表征目标声纹特征外的声纹特征簇作为所述噪声声纹特征。
11、作为本发明的一种优选方案,所述分别统计目标声纹特征和噪声声纹特征的信息量,包括:
12、统计目标声纹特征对应的声纹特征簇中待识别声纹特征的特征数量作为目标声纹特征的信息量;
13、统计噪声声纹特征对应的声纹特征簇中待识别声纹特征的特征数量作为噪声声纹特征的信息量。
14、作为本发明的一种优选方案,所述对目标声纹特征进行深度学习得到目标声纹识别模型,包括:
15、将目标声纹特征作为神经网络的第一输入项,将目标声纹标签作为神经网络的第一输出项,利用神经网络对所述第一输入项和第一输出项进行网络训练得到所述目标声纹识别模型;
16、所述目标声纹识别模型的模型表达式为:
17、goal_label=cnn(goal_s);
18、式中,goal_label为目标声纹标签,goal_s为目标声纹特征,cnn为神经网络。
19、作为本发明的一种优选方案,所述对噪声声纹特征进行深度学习得到噪声声纹识别模型,包括:
20、将噪声声纹特征作为神经网络的第二输入项,将噪声声纹标签作为神经网络的第二输出项,利用神经网络对所述第二输入项和第二输出项进行网络训练得到所述噪声声纹识别模型;
21、所述噪声声纹识别模型的模型表达式为:
22、background_label=cnn(background_s);
23、式中,background_label为噪声声纹标签,background_s为噪声声纹特征,cnn为神经网络。
24、作为本发明的一种优选方案,所述基于目标声纹特征和噪声声纹特征的信息量进行目标声纹识别模型和噪声声纹识别模型的融合得到目标声纹动态识别模型,包括:
25、对所述目标声纹和噪声声纹的信息量进行归一化处理作为目标声纹识别模型和噪声声纹识别模型的融合权重,所述融合权重的计算公式为:
26、wgt=pt/(pt+qt);
27、wbt=qt/(pt+qt);
28、式中,wgt为第t个声音识别时序处的目标声纹识别模型的融合权重,wbt为第t个声音识别时序处的噪声声纹识别模型的融合权重,pt为第1个至第t个声音识别时序处的目标声纹特征信息量总和,qt为第1个至第t个声音识别时序处的噪声声纹特征信息量总和,t为时序计数变量;
29、基于所述融合权重对所述目标声纹识别模型和噪声声纹识别模型进行融合得到所述目标声纹动态识别模型,所述目标声纹动态识别模型的函数表达式为:
30、labelt=wgt*goal_labelt+wbt*background_labelt;
31、式中,labelt为第t个声音识别时序处的声纹标签,goal_labelt为第t个声音识别时序处的目标声纹识别模型,background_labelt为第t个声音识别时序处的噪声声纹识别模型;
32、其中,goal_labelt=cnn(goal_st);
33、式中,goal_labelt为第t个声音识别时序处的目标声纹标签,goal_st为第t个声音识别时序处的目标声纹特征;
34、background_labelt=cnn(background_st);
35、式中,background_labelt为第t个声音识别时序处的噪声声纹标签,background_st为第t个声音识别时序处的噪声声纹特征。
36、作为本发明的一种优选方案,所述可采集区域范围内的同频段内的各个声音的待识别声纹特征在运算前进行特征归一化处理,以消除量纲误差。
37、作为本发明的一种优选方案,所述神经网络包括多层感知网络、径向基函数中的至少一种。
38、作为本发明的一种优选方案,所述声音识别时序与声音识别阶段呈正相关性。
39、本发明与现有技术相比较具有如下有益效果:
40、本发明对目标声纹特征进行深度学习得到目标声纹识别模型,对噪声声纹特征进行深度学习得到噪声声纹识别模型,基于目标声纹特征和噪声声纹特征的信息量进行目标声纹识别模型和噪声声纹识别模型的融合得到目标声纹动态识别模型,实现目标声纹的精准性与声音识别阶段的动态适配,目标声纹动态识别模型伴随指定对象声音样本数变化的情况会提升指定对象声音的识别适配性,进而保证声音识别的精度效果。
技术特征:1.一种基于多模态的声音动态识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于多模态的声音动态识别方法,其特征在于:分别利用lpcc特征提取算法和mfcc特征提取算法提取可采集区域范围内的同频段内的各个声音的lpcc特征和mfcc特征作为可采集区域范围内的同频段内的各个声音的待识别声纹特征。
3.根据权利要求1所述的一种基于多模态的声音动态识别方法,其特征在于:所述在待识别声纹特征中标记出属于指定对象声音的目标声纹特征和不属于指定对象声音的噪声声纹特征,包括:
4.根据权利要求1所述的一种基于多模态的声音动态识别方法,其特征在于:所述分别统计目标声纹特征和噪声声纹特征的信息量,包括:
5.根据权利要求4所述的一种基于多模态的声音动态识别方法,其特征在于:所述对目标声纹特征进行深度学习得到目标声纹识别模型,包括:
6.根据权利要求5所述的一种基于多模态的声音动态识别方法,其特征在于:所述对噪声声纹特征进行深度学习得到噪声声纹识别模型,包括:
7.根据权利要求6所述的一种基于多模态的声音动态识别方法,其特征在于:所述基于目标声纹特征和噪声声纹特征的信息量进行目标声纹识别模型和噪声声纹识别模型的融合得到目标声纹动态识别模型,包括:
8.根据权利要求7所述的一种基于多模态的声音动态识别方法,其特征在于,所述融合权重的计算公式为:
9.根据权利要求7所述的一种基于多模态的声音动态识别方法,其特征在于,所述融合权重的计算公式为:
10.根据权利要求9所述的一种基于多模态的声音动态识别方法,其特征在于,所述可采集区域范围内的同频段内的各个声音的待识别声纹特征在运算前进行特征归一化处理,以消除量纲误差;所述神经网络包括多层感知网络、径向基函数中的至少一种;所述声音识别时序与声音识别阶段呈正相关性。
技术总结本发明公开了一种基于多模态的声音动态识别方法,包括以下步骤:在待识别声纹特征中标记出属于指定对象声音的目标声纹特征和不属于指定对象声音的噪声声纹特征,分别统计目标声纹特征和噪声声纹特征的信息量;对目标声纹特征进行深度学习得到目标声纹识别模型,对噪声声纹特征进行深度学习得到噪声声纹识别模型,基于目标声纹特征和噪声声纹特征的信息量进行目标声纹识别模型和噪声声纹识别模型的融合得到目标声纹动态识别模型。本发明实现目标声纹的精准性与声音识别阶段的动态适配,目标声纹动态识别模型伴随指定对象声音样本数变化的情况会提升指定对象声音的识别适配性,进而保证声音识别的精度效果。技术研发人员:陈佳炜,董伟,曹琪,魏志豪,陈凯磊,叶聿中,周袁成受保护的技术使用者:华中科技大学同济医学院附属协和医院技术研发日:技术公布日:2024/5/29本文地址:https://www.jishuxx.com/zhuanli/20240618/24433.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。