一种基于BI智能分析的语音交互数据可视化处理方法与流程
- 国知局
- 2024-06-21 11:54:56
本发明涉及数据可视化,特别是涉及一种基于bi智能分析的语音交互数据可视化处理方法。
背景技术:
1、bi智能分析是一种利用ai技术实现的数据分析方式,它允许用户通过语音交互来探索和理解数据。这种方式降低了用户的数据分析门槛,无需复杂的操作,用户只需要提出自然语言的问题,即可快速获得准确的分析结果。
2、尽管bi智能分析已经广泛应用于语音交互数据可视化处理,但是随着语音数据的复杂化,当前的语音交互数据可视化处理方法无法保证语音在可视化过程中的质量,语音质量对数据可视化结果影响很大,如数据的完整性、准确性和实时性等,如果存在数据缺失或数据质量问题,将直接影响到可视化处理结果的准确性,且当前的处理方法不能同时对两种语音数据进行一致化噪音抑制处理,降低了语音交互数据可视化处理效率,同时无法对语音处理数据进行可视化展示。
3、因此,如何提供一种可以基于bi智能分析的语音交互数据可视化处理方法,是目前有待解决的技术问题。
技术实现思路
1、本发明实施例提供一种基于bi智能分析的语音交互数据可视化处理方法,用以解决现有技术中无法对语音交互数据进行智能化分析,无法提高语音交互数据可视化处理效率和可视化处理精度,无法对大模型分析结果进行可视化呈现,无法支持语音交互,无法实现bi智能分析及可视化识别及展示的技术问题。
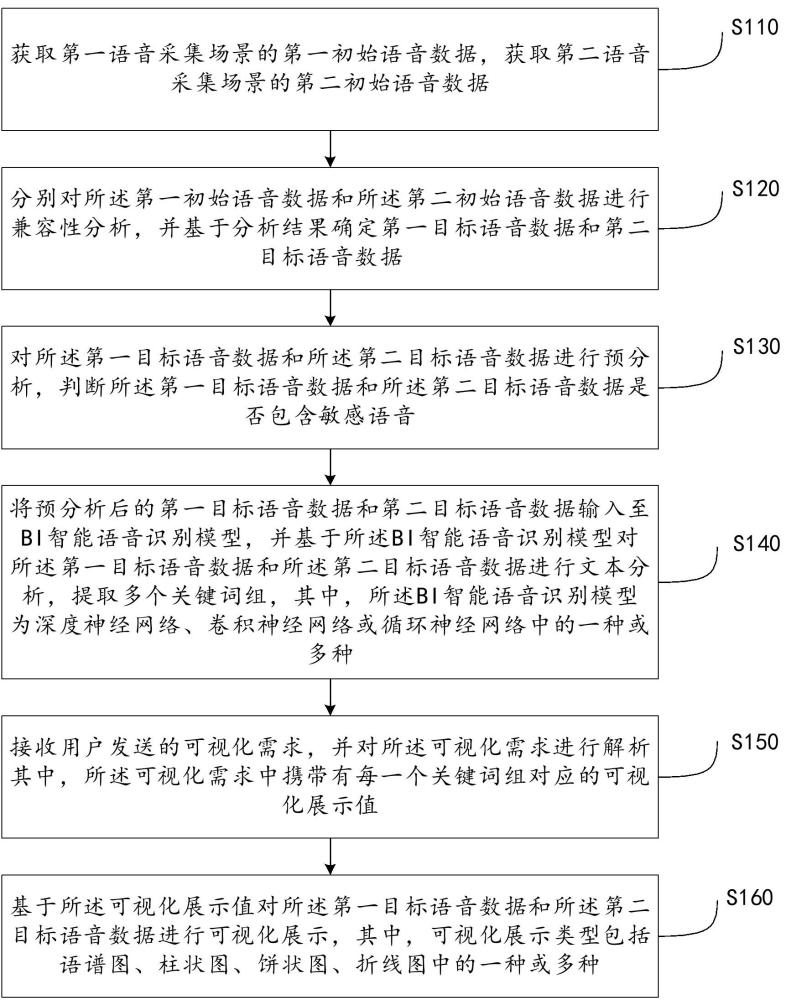
2、为了实现上述目的,本发明提供了一种基于bi智能分析的语音交互数据可视化处理方法,包括:
3、获取第一语音采集场景的第一初始语音数据,获取第二语音采集场景的第二初始语音数据;
4、分别对所述第一初始语音数据和所述第二初始语音数据进行兼容性分析,并基于分析结果确定第一目标语音数据和第二目标语音数据;
5、对所述第一目标语音数据和所述第二目标语音数据进行预分析,判断所述第一目标语音数据和所述第二目标语音数据是否包含敏感语音;
6、将预分析后的第一目标语音数据和第二目标语音数据输入至bi智能语音识别模型,并基于所述bi智能语音识别模型对所述第一目标语音数据和所述第二目标语音数据进行文本分析,提取多个关键词组,其中,所述bi智能语音识别模型为深度神经网络、卷积神经网络或循环神经网络中的一种或多种;
7、接收用户发送的可视化需求,并对所述可视化需求进行解析,其中,所述可视化需求中携带有每一个关键词组对应的可视化展示值;
8、基于所述可视化展示值对所述第一目标语音数据和所述第二目标语音数据进行可视化展示,其中,可视化展示类型包括语谱图、柱状图、饼状图、折线图中的一种或多种。
9、进一步的,在对所述第一目标语音数据和所述第二目标语音数据进行预分析,判断所述第一目标语音数据和所述第二目标语音数据是否包含敏感语音时,包括:
10、对所述第一目标语音数据和所述第二目标语音数据进行语音处理,获得多个语音特征;
11、根据预先训练的语音分析模型对所有的语音特征进行语音分析,获得每一个语音特征对应的分析语音数据;
12、根据所述分析语音数据判断所述第一目标语音数据和所述第二目标语音数据是否包含敏感语音,若是,则删除对应的目标语音数据,若否,则将预分析后的第一目标语音数据和第二目标语音数据输入至bi智能语音识别模型。
13、进一步的,在分别对所述第一初始语音数据和所述第二初始语音数据进行兼容性分析,并基于分析结果确定第一目标语音数据和第二目标语音数据时,包括:
14、分别获取所述第一初始语音数据的第一语音类型和所述第二初始语音数据的第二语音类型;
15、判断所述第一语音类型和预设的兼容语音类型是否一致,若是,则保留所述第一初始语音数据,若否,则删除所述第一初始语音数据;
16、判断所述第二语音类型和预设的兼容语音类型是否一致,若是,则保留所述第二初始语音数据,若否,则删除所述第二初始语音数据;
17、当所述第一语音类型和所述第二语音类型均符合预设的兼容语音类型时,则将所述第一初始语音数据作为所述第一目标语音数据,将所述第二初始语音数据作为所述第二目标语音数据。
18、进一步的,在将预分析后的第一目标语音数据和第二目标语音数据输入至bi智能语音识别模型之前,还包括:
19、采集所述第一目标语音数据的第一语音元素信息和所述第二目标语音数据的第二语音元素信息,根据所述第一语音元素信息和所述第二语音元素信息判断所述第一目标语音数据和所述第二目标语音数据是否可以一致化处理,并根据判断结果计算所述第一目标语音数据和所述第二目标语音数据的关联处理因子;
20、基于所述关联处理因子设定所述第一目标语音数据和所述第二目标语音数据的噪音抑制因子,并根据所述噪音抑制因子对所述第一目标语音数据和所述第二目标语音数据进行噪音抑制处理。
21、进一步的,在根据所述第一语音元素信息和所述第二语音元素信息判断所述第一目标语音数据和所述第二目标语音数据是否可以一致化处理,并根据判断结果计算所述第一目标语音数据和所述第二目标语音数据的关联处理因子时,包括:
22、根据所述第一语音元素信息构建第一语音元素集合;
23、根据所述第二语音元素信息构建第二语音元素集合;
24、判断所述第一语音元素集合和所述第二语音元素集合之间是否存在交集语音元素,
25、若否,则判断所述第一目标语音数据和所述第二目标语音数据不可以一致化处理;
26、若是,则判断所述第一目标语音数据和所述第二目标语音数据可以一致化处理,并根据所述第一目标语音数据和所述第二目标语音数据之间存在交集的语音元素构建第三语音元素集合;
27、基于预先训练的关联度模型确定所述第一语音元素集合和标准元素集合之间的第一关联度,确定所述第二语音元素集合和所述标准元素集合之间的第二关联度,确定所述第三语音元素集合和所述标准元素集合之间的第三关联度;
28、基于预先训练的价值模型确定所述第三语音元素集合中每一个语音元素的语音元素价值;
29、根据所述第一关联度、所述第二关联度、所述第三关联度和所述第三语音元素集合中每一个语音元素的语音元素价值计算所述第一目标语音数据和所述第二目标语音数据的关联处理因子。
30、进一步的,根据下式计算所述第一目标语音数据和所述第二目标语音数据的关联处理因子:
31、;
32、其中,s为第一目标语音数据和第二目标语音数据的关联处理因子,ki为第三语音元素集合中第i个语音元素的语音元素价值,n为第三语音元素集合中语音元素的数量,f1为第一关联度,f2为第二关联度,f3为第三关联度,m1为第一语音元素集合中语音元素的数量,m2为第二语音元素集合中语音元素的数量。
33、进一步的,在基于所述关联处理因子设定所述第一目标语音数据和所述第二目标语音数据的噪音抑制因子时,包括:
34、预先设定第一预设关联处理因子和第二预设关联处理因子;
35、根据所述关联处理因子、所述第一预设关联处理因子和所述第二预设关联处理因子之间的关系设定所述第二目标语音数据的噪音抑制因子;
36、当所述关联处理因子小于所述第一预设关联处理因子时,则将所述第二目标语音数据的噪音抑制因子设定为g1;
37、当所述关联处理因子大于或等于所述第一预设关联处理因子,且所述关联处理因子小于所述第二预设关联处理因子时,则将所述第二目标语音数据的噪音抑制因子设定为g2;
38、当所述关联处理因子大于或等于所述第二预设关联处理因子时,则将所述第二目标语音数据的噪音抑制因子设定为g3;
39、其中,g1<g2<g3。
40、进一步的,在基于所述关联处理因子设定所述第一目标语音数据和所述第二目标语音数据的噪音抑制因子之后,还包括:
41、在将所述第二目标语音数据的噪音抑制因子设定为gi时,i=1,2,3,对所述噪音抑制因子gi进行相关性评估,得到对应的相关性评估值;
42、根据所述相关性评估值和相关性评估阈值之间的关系判断所述噪音抑制因子gi是否满足噪音抑制需求;
43、当所述相关性评估值小于所述相关性评估阈值时,则判断所述噪音抑制因子gi不满足噪音抑制需求;
44、当所述相关性评估值大于或等于所述相关性评估阈值时,则判断所述噪音抑制因子gi满足噪音抑制需求。
45、进一步的,在判断所述噪音抑制因子gi不满足噪音抑制需求时,包括:
46、预先设定第一预设相关性评估值和第二预设相关性评估值;
47、根据所述相关性评估值、所述第一预设相关性评估值和所述第二预设相关性评估值之间的关系对所述噪音抑制因子gi进行补偿;
48、当所述相关性评估值小于所述第一预设相关性评估值时,则选定第一预设补偿系数y1对所述噪音抑制因子gi进行补偿,补偿后的噪音抑制因子为y1*gi;
49、当所述相关性评估值大于或等于所述第一预设相关性评估值,且所述相关性评估值小于所述第二预设相关性评估值时,则选定第二预设补偿系数y2对所述噪音抑制因子gi进行补偿,补偿后的噪音抑制因子为y2*gi;
50、当所述相关性评估值大于或等于所述第二预设相关性评估值时,则选定第三预设补偿系数y3对所述噪音抑制因子gi进行补偿,补偿后的噪音抑制因子为y3*gi;
51、其中,y1<y2<y3。
52、进一步的,在基于所述可视化展示值对噪音处理后的第一目标语音数据和第二目标语音数据进行可视化展示时,包括:
53、根据所述可视化需求确定需要可视化展示包括的可视化展示值和语音数据可视化类型;
54、从可视化展示数据库中,确定与所述可视化展示值对应的第一展示列,并确定与所述语音数据可视化类型对应的第二展示列;
55、建立所述第一展示列和所述第二展示列之间的多维索引,其中,每个多维索引用于将可视化展示值和语音数据可视化类型进行关联;
56、基于所述多维索引对噪音处理后的第一目标语音数据和第二目标语音数据进行可视化展示。
57、本发明提供了一种基于bi智能分析的语音交互数据可视化处理方法,相较现有技术,具有以下有益效果:
58、本发明公开了一种基于bi智能分析的语音交互数据可视化处理方法,不局限于数字驾驶舱等的应用,基于机器学习的语音数据分析、识别、调用大量数据对语音识别结果进行可视化分析阐释,特别的对大模型分析结果的可视化呈现,支持语音交互,实现bi智能分析及可视化识别及展示。确定第一目标语音数据和第二目标语音数据,并进行预分析,判断是否包含敏感语音;将第一目标语音数据和第二目标语音数据输入至bi智能语音识别模型,提取多个关键词组,对第一目标语音数据和第二目标语音数据进行可视化展示,实现了对语音数据的智能化分析,提高语音交互数据可视化处理精度和处理效率,使语音数据可视化展示更加直观和易于理解。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24451.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。