一种记者采访语音增强方法
- 国知局
- 2024-06-21 11:57:33
本发明属于数字音频处理,具体提供一种记者采访语音增强方法。
背景技术:
1、语音增强是从带有噪声的语音中,去除包括环境和无关人员的噪声,突显目标说话人的语音,从而改善语音的质量。语音增强可分为传统和深度学习两类方法,传统方法主要依赖于信号处理技术,包括频谱减法、维纳滤波和统计模型等;深度学习方法利用大规模数据集进行训练,学习从噪声语音到清晰语音之间复杂的非线性映射。深度学习的语音增强方法又可分为有监督和无监督方法两类,有监督方法需要纯净语音和对应的带噪语音组成的样本对,对模型进行训练,适合应用场景固定的场合;其中,个性化语音增强在训练模型时,除了使用纯净语音和对应的带噪语音的同时,还参考了目标说话人的其他纯净语音,增强了目标说话人的语音质量。相对于有监督学习方法,无监督学习方法则不需要纯净语音,而直接使用带噪语音进行训练;无监督学习方法对环境噪声有更强的鲁棒性,适合应用场景变化较大的场合,但其增强效果不如有监督方法。
2、记者采访常在多变的环境中进行,背景噪声多样,噪声类型不固定,无法提前预知;同时,采访时涉及多个说话人,除记者外,被采访人的纯净语音往往也难以获取,这些原因都限制了有监督方法的使用,而无监督方法的语音增强效果不理想。
技术实现思路
1、本发明的目的在于针对上述现有技术的不足,提供一种记者采访语音增强方法,用以改善背景噪声复杂多变的采访语音的增强效果。
2、为了达到上述目的,本发明采用的技术方案为:
3、一种记者采访语音增强方法,其特征在于,包括以下步骤:
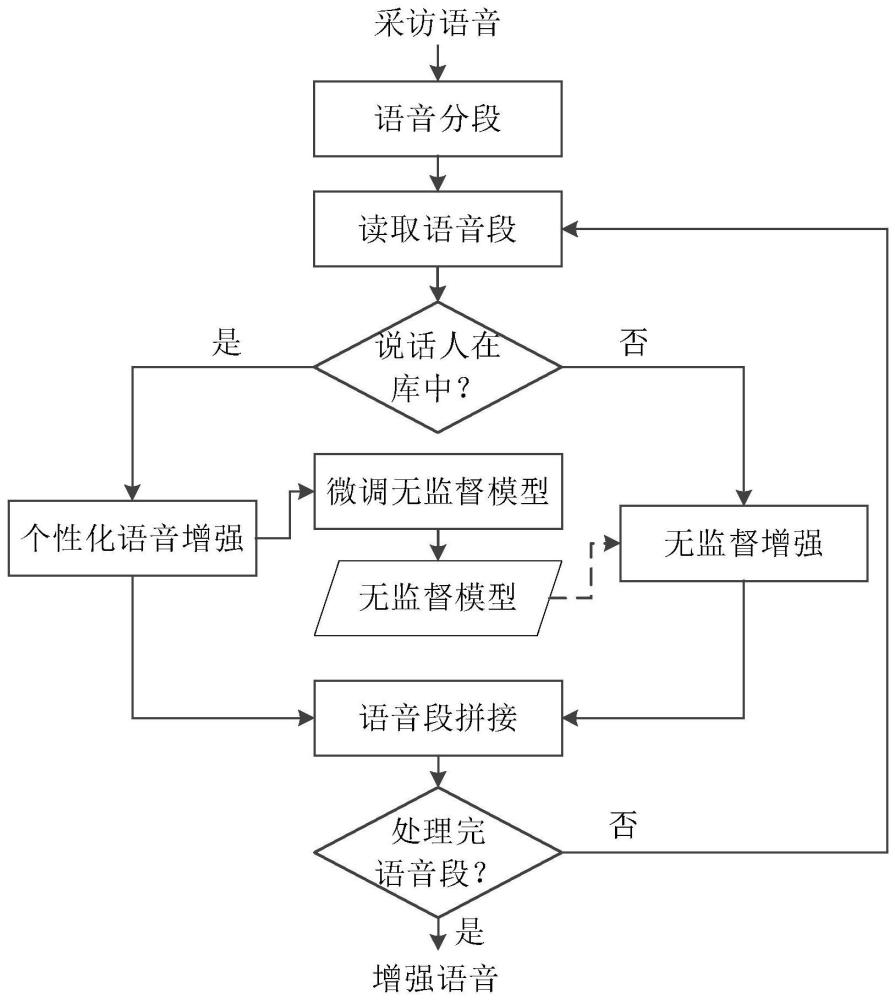
4、a1.语音分段;
5、a1-1.设语音库中包含s个说话人的多条纯净语音,每条纯净语音均为单个说话人的语音,根据语音库中的语音训练得到说话人识别模型;
6、a1-2.将输入语音按固定长度进行分段,得到k个语音段;
7、a1-3.对每一个语音段作:对第k、1≤k≤k个段,将该段的音频数据输入到说话人识别模型中进行说话人识别,得到第k个语音段对应的说话人编号sk及预测概率pk;将预测概率pk与预测阈值p作比较,若pk小于p,则更新说话人编号sk为s+1;
8、a1-4.按时间顺序依次扫描各个语音段对应的说话人编号,将说话人编号相同的连续语音段合并为一段,得到l个语音段;
9、a2.读取语音段;
10、a2-1.初始化i=1;
11、a2-2.读取第i个语音段的数据xi及其对应的说话人编号si;
12、a3.判断说话人是否在库中:若si≤s,则转到步骤a4进行语音增强,否则转到步骤a6进行语音增强;
13、a4.个性化语音增强:从语音库中取出编号为si的说话人的任意一条纯净语音ri,将语音段xi和纯净语音ri输入到个性化语音增强模型中进行增强,得到增强语音段ei;
14、a5.微调无监督模型;
15、a5-1.构造微调训练样本:计算噪声yi:yi=xi-ei,从语音库中随机抽取m条纯净语音,将每一条语音与噪声yi相加,生成m条加噪语音,将每条纯净语音与其加噪语音组成一个微调训练样本,共得到m个微调训练样本;
16、a5-2.用微调训练样本对无监督语音增强预训练模型进行微调,得到微调后的无监督语音增强模型,转到步骤a7;
17、a6.无监督增强:将语音段xi输入到无监督语音增强模型中进行增强,得到增强语音段ei;
18、a7.语音段拼接:将增强语音段ei追加到语音序列w中;
19、a8.判断是否处理完语音段:若i小于语音段数目l,则更新i为i+1,转到a2-2,否则输出语音序列w。
20、基于上述技术方案,本发明的有益效果在于:
21、本发明提供一种记者采访语音增强方法,该方法通过说话人识别将输入语音按说话人类别进行分段,在此基础上,对属于语音库中说话人的语音采用个性化语音增强方法进行增强,对不属于语音库中说话人的语音采用无监督语音增强方法进行增强,从而结合了有监督和无监督两类语音增强方法的优点,达到了更好的语音增强效果;同时,在个性化语音增强处理后,利用提取的背景噪声信息对无监督语音增强预训练模型进行微调,提高了无监督语音增强模型的性能,增强了该方法对复杂噪声环境的适应性。
技术特征:1.一种记者采访语音增强方法,其特征在于,包括以下步骤:
技术总结本发明属于数字音频处理技术领域,具体提供一种记者采访语音增强方法,用以改善背景噪声复杂多变的采访语音的增强效果。本发明提供的记者采访语音增强方法中,通过说话人识别将输入语音按说话人类别进行分段,在此基础上,对属于语音库中说话人的语音采用个性化语音增强方法进行增强,对不属于语音库中说话人的语音采用无监督语音增强方法进行增强,从而结合了有监督和无监督两类语音增强方法的优点,达到了更好的语音增强效果;同时,在个性化语音增强处理后,利用提取的背景噪声信息对无监督语音增强预训练模型进行微调,提高了无监督语音增强模型的性能,增强了该方法对复杂噪声环境的适应性。技术研发人员:甘涛,吴嘉鑫,罗瑜,何艳敏受保护的技术使用者:电子科技大学技术研发日:技术公布日:2024/6/11本文地址:https://www.jishuxx.com/zhuanli/20240618/24726.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表