口语问答评分方法、装置、设备、存储介质及程序产品与流程
- 国知局
- 2024-06-21 11:58:07
本技术涉及人工智能,尤其涉及一种口语问答评分方法、装置、设备、存储介质及程序产品。
背景技术:
1、现有的口语问答评分方法中,对作答音频的识别仅关注于利用语音识别技术将作答音频转化为文本,对于作答音频与作答题目之间的关系以及如何利用作答题目的先验信息来提高识别的准确性,却缺乏深入的探索和应用。尤其是开放类问答等答案不固定的题型,往往更依赖于具体的题目信息,这类题型的答案通常具有较大的自由度,不遵循固定的模式和结构,仅依靠语音识别技术来转写音频,可能会遗漏或误识别一些关键信息,比如特定的术语、细节、语境或上下文信息等,从而导致在转写音频时出现偏差或误解,降低转写音频的准确率,进而影响评分的准确性。
技术实现思路
1、有鉴于此,本技术致力于提供一种口语问答评分方法、装置、设备、存储介质及程序产品,能够提高语音识别的准确率,增加对目标作答音频的评分的准确性和可靠性。
2、根据本技术实施例的第一方面,提供了一种口语问答评分方法,包括:
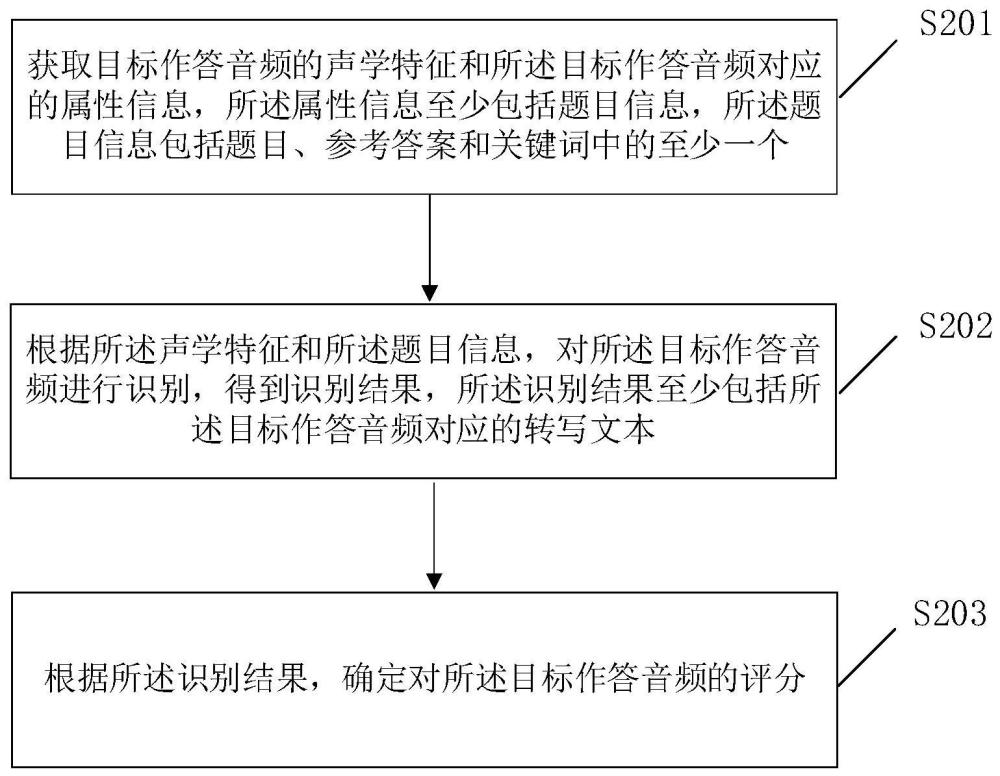
3、获取目标作答音频的声学特征和所述目标作答音频对应的属性信息,所述属性信息至少包括题目信息,所述题目信息包括题目、参考答案和关键词中的至少一个;
4、根据所述声学特征和所述题目信息,对所述目标作答音频进行识别,得到识别结果,所述识别结果至少包括所述目标作答音频对应的转写文本;
5、根据所述识别结果,确定对所述目标作答音频的评分。
6、可选的,所述根据所述识别结果,确定对所述目标作答音频的评分,包括:
7、根据所述识别结果,确定所述识别结果对应的评分特征,所述评分特征至少包括第一评分特征,所述第一评分特征包括所述转写文本与所述参考答案的匹配结果;
8、根据所述评分特征,确定对所述目标作答音频的评分。
9、可选的,所述识别结果还包括所述目标作答音频对应的发音对错评价信息;所述评分特征还包括第二评分特征,所述第二评分特征包括基于所述发音对错评价信息确定的发音评价结果。
10、可选的,所述识别结果还包括所述目标作答音频中的异常信息,所述异常信息包括非语言干扰信息和/或语言干扰信息;所述评分特征还包括第三评分特征,所述第三评分特征包括所述目标作答音频中的异常数据特征。
11、可选的,所述属性信息还包括评分员信息,所述评分员信息表征评分员的评分标准;
12、所述根据所述评分特征,确定对所述目标作答音频的评分,包括:
13、根据所述评分特征以及所述评分员信息,确定对所述目标作答音频的评分。
14、可选的,所述根据所述声学特征和所述题目信息,对所述目标作答音频进行识别,得到识别结果,包括:
15、根据所述题目信息生成任务指令,所述任务指令用于指示根据所述声学特征和所述题目信息,确定对所述目标作答音频的识别结果;
16、由预先训练的语音识别模型执行所述任务指令,以得到对所述目标作答音频的识别结果。
17、可选的,所述根据所述声学特征和所述题目信息,对所述目标作答音频进行识别,得到识别结果,根据所述识别结果,确定对所述目标作答音频的评分,包括:
18、将所述声学特征和所述属性信息输入预先训练的口语问答评分模型,确定对所述目标作答音频的评分;
19、其中,所述口语问答评分模型包括语音识别子模型和评分子模型;
20、所述语音识别子模型用于根据所述声学特征和所述题目信息,对所述目标作答音频进行识别,得到识别结果;
21、所述评分子模型用于根据所述识别结果,确定对所述目标作答音频的评分。
22、可选的,所述语音识别模型的训练过程包括:
23、获取第一训练样本,所述第一训练样本包括第一样本音频对应的第一样本声学特征、样本题目信息以及标注识别结果,所述标注识别结果至少包括所述第一样本音频对应的第一标注转写文本,所述第一样本音频包括口语问答音频;
24、使用所述第一训练样本对待训练的语音识别模型进行语音识别训练。
25、可选的,所述标注识别结果还包括所述第一样本音频对应的标注发音对错评价信息和标注异常信息,所述语音识别模型对所述第一样本音频的识别结果还包括所述第一样本音频对应的发音对错评价信息和异常信息;
26、所述使用所述第一训练样本对待训练的语音识别模型进行语音识别训练之前,所述方法还包括:
27、获取第二训练样本和第三训练样本,所述第二训练样本包括第二样本音频对应的第二样本声学特征以及第二标注转写文本,所述第三训练样本包括第三样本音频对应的第三样本声学特征、第三标注转写文本以及所述第三样本音频对应的标注发音对错评价信息;
28、使用所述第二训练样本对初始语音识别模型进行第一语音识别训练;
29、使用第三训练样本对经过所述第一语音识别训练得到的语音识别模型进行第二语音识别训练。
30、根据本技术实施例的第二方面,提供了一种口语问答评分装置,包括:
31、第一单元,用于获取目标作答音频的声学特征和所述目标作答音频对应的属性信息,所述属性信息至少包括题目信息,所述题目信息包括题目、参考答案和关键词中的至少一个;
32、第二单元,用于根据所述声学特征和所述题目信息,对所述目标作答音频进行识别,得到识别结果,所述识别结果至少包括所述目标作答音频对应的转写文本;
33、第三单元,用于根据所述识别结果,确定对所述目标作答音频的评分。
34、根据本技术实施例的第三方面,提供了一种电子设备,包括存储器和处理器;
35、所述存储器与所述处理器连接,用于存储程序;
36、所述处理器用于通过运行所述存储器中的程序,实现如本技术实施例的第一方面中任意一项所述的口语问答评分方法。
37、根据本技术实施例的第四方面,提供了一种存储介质,所述存储介质上存储有计算机程序,所述计算机程序被处理器运行时,实现如本技术实施例的第一方面中任意一项所述的口语问答评分方法。
38、根据本技术实施例的第五方面,提供了一种计算机程序产品,包括计算机程序指令,所述计算机程序指令在被处理器运行时使得所述处理器实现如本技术实施例的第一方面中任意一项所述的口语问答评分方法。
39、本技术提出的口语问答评分方法,首先获取目标作答音频的声学特征和所述目标作答音频对应的属性信息,所述属性信息至少包括题目信息,所述题目信息包括题目、参考答案和关键词中的至少一个;然后根据所述声学特征和所述题目信息,对所述目标作答音频进行识别,得到识别结果,所述识别结果至少包括所述目标作答音频对应的转写文本;最后根据所述识别结果,确定对所述目标作答音频的评分。
40、本技术提出的技术方案,在对目标作答音频进行语音识别时,通过对目标作答音频对应的声学特征和题目信息进行分析,生成目标作答音频对应的语音识别结果,充分利用了作答题目的先验信息,提高了音频转写的准确率,进而增加了对目标作答音频的评分的准确性和可靠性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24779.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。