一种基于人工智能的空调远程操控系统的制作方法
- 国知局
- 2024-07-30 16:51:55
本发明涉及数据处理,具体涉及一种基于人工智能的空调远程操控系统。
背景技术:
1、随着人工智能技术的发展和应用,空调操控系统成为了现代化建筑和家居领域的重要组成部分;其通过传感器对空调相关数据进行采集,通过数据处理及预测算法,实现对空调操控,从而提供更加舒适、高效且可持续的室内环境;然而空调相关数据所采集的数据量庞大且频繁密集,同时通过数据处理及预测算法实现对空调操控,需要大量历史数据来构建模型并训练,为了提高数据管理效率以及系统响应效率,需要对空调相关数据进行压缩处理,从而实现节省存储空间并达成实时系统响应。
2、现有方法中通过预测编码的压缩方式对空调相关数据进行处理,arima模型是一种常用于预测编码压缩的预测模型,结合了差分、自回归以及移动平均的操作来处理非平稳时间序列数据;但由于空调相关数据中存在多个维度的数据,不同维度的数据之间的关系较为复杂多变且互相干扰,若设置单一的差分阶数会影响到非平稳数据到平稳数据的变化,进而影响到预测模型构建的效果,使得后续的数据压缩效果较差,导致压缩效率降低并影响空调操控系统的实时相应效率。
技术实现思路
1、本发明提供一种基于人工智能的空调远程操控系统,以解决现有的对空调相关数据进行压缩时不同维度数据之间存在干扰而影响压缩效果的问题,所采用的技术方案具体如下:
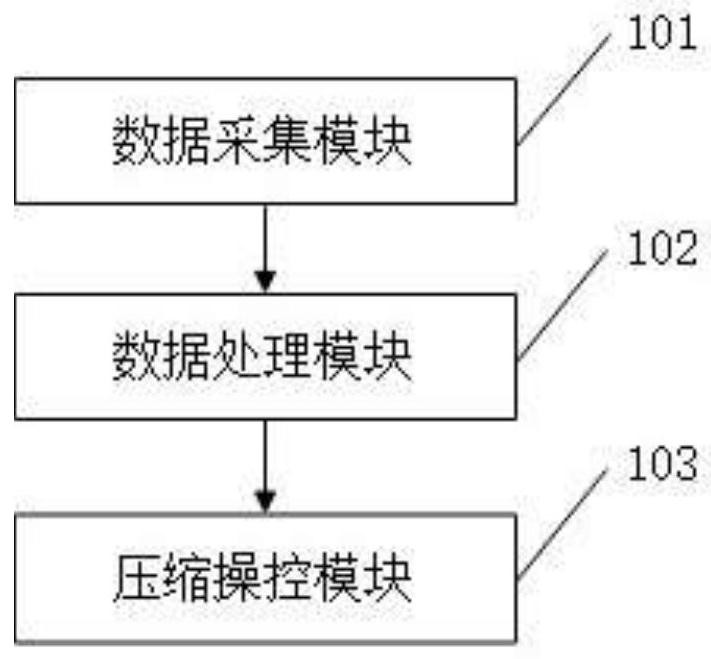
2、本发明一个实施例提供了一种基于人工智能的空调远程操控系统,该系统包括:
3、数据采集模块,采集空调操控系统的多个维度的待处理数据;
4、数据处理模块:根据每个维度的待处理数据在不同分段范围不同尺度下的初始分段数据之间的相关性,得到每个维度的最优分段范围及若干标准分段数据;
5、根据同一维度不同标准分段数据通过ica得到的分量之间的相似度,获取每个维度的若干相似分量并聚类分析得到每个维度的共同分布特征;
6、根据每个维度的待处理数据及共同分布特征,获取每个维度的若干趋势干扰数据及对应的趋势分段数据;
7、根据每个维度的趋势干扰数据与关联维度的待处理数据之间的相似性,得到每个维度每个趋势分段数据的干扰程度;获取每个趋势分段数据的初始差分阶数,结合干扰程度得到每个维度每个趋势分段数据的修正差分阶数;
8、压缩操控模块,根据每个维度每个趋势分段数据的修正差分阶数进行预测压缩编码,得到压缩后数据并存储,实现对空调系统的操控。
9、进一步的,所述得到每个维度的最优分段范围及若干标准分段数据,包括的具体方法为:
10、根据不同尺度及不同分段范围,得到每个维度每个分段范围每个尺度下的若干初始分段数据;以任意一个维度为当前维度,当前维度的第u个分段范围的优选程度αu的计算方法为:
11、
12、其中,r表示当前维度任意一个分段范围任意一个尺度下任意两个初始分段数据的皮尔逊相关系数的均值,记为当前维度任意一个分段范围任意一个尺度的相关性;表示第u个分段范围所有尺度的相关性的均值;su(r)表示第u个分段范围所有尺度的相关性的方差;smax(r)表示获取每个分段范围所有尺度的相关性的方差中的最大值;
13、获取当前维度每个分段范围的优选程度,将优选程度最大的分段范围作为当前维度的最优分段范围,通过最优分段范围对当前维度的待处理数据进行分段,得到的每个分段记为标准分段数据;
14、获取每个维度的最优分段范围,得到每个维度的若干标准分段数据。
15、进一步的,所述得到每个维度每个分段范围每个尺度下的若干初始分段数据,包括的具体方法为:
16、以任意一个维度为当前维度,通过不同尺度对当前维度的待处理数据进行平均,得到当前维度在每个尺度下的平均后数据;
17、通过预设迭代的分段范围得到若干分段范围,通过每个分段范围对当前维度每个尺度下的平均后数据进行分段,得到当前维度每个分段范围每个尺度下的若干分段数据,记为初始分段数据;
18、获取每个维度每个分段范围每个尺度下的若干初始分段数据。
19、进一步的,所述获取每个维度的若干相似分量并聚类分析得到每个维度的共同分布特征,包括的具体方法为:
20、对同一维度不同标准分段数据通过ica得到的分量进行相似度计算,通过对相似度进行阈值筛选,获取每个维度的若干相似分量;
21、以任意一个维度为当前维度,对当前维度的若干相似分量进行dbscan聚类,聚类距离采用相似分量之间相似度的倒数,得到若干聚簇;获取相似分量数量最多的聚簇,对该聚簇中所有相似分量求平均得到平均分量,将平均分量作为当前维度的共同分布特征;获取每个维度的共同分布特征。
22、进一步的,所述对同一维度不同标准分段数据通过ica得到的分量进行相似度计算,包括的具体方法为:
23、以任意一个维度为当前维度,对当前维度的每个标准分段数据进行ica独立成分分析,得到每个标准分段数据的若干分量;第i个标准分段数据的第c个分量与第j个标准分段数据的第x个分量的相似度β(ic,jx)的计算方法为:
24、
25、其中,n表示分量中数据点的数量,δfn表示两个分量中第n个数据点的数值差值绝对值,softmax表示对两个分量中所有数据点的数值差值绝对值进行softmax归一化,fn(ic)表示第i个标准分段数据的第c个分量中第n个数据点的数据值,fn(jx)表示第j个标准分段数据的第x个分量中第n个数据点的数据值,||表示求绝对值,exp()表示以自然常数为底的指数函数;
26、获取每个维度中任意两个标准分段数据的任意两个分量之间的相似度。
27、进一步的,所述每个维度的若干趋势干扰数据及对应的趋势分段数据,具体的获取方法为:
28、以任意一个维度为当前维度,获取当前维度的若干标准分段数据及共同分布特征,将每个标准分段数据减去共同分布特征得到的一段数据,记为每个标准分段数据的受干扰分段数据;按照标准分段数据的顺序对受干扰分段数据进行排序拼接,得到的一段数据记为当前维度的受干扰数据;
29、对当前维度的受干扰数据进行stl时间序列分解,得到受干扰数据的趋势项,根据趋势项中数据点斜率的变化获取若干趋势分段点;通过趋势分段点对当前维度的受干扰数据进行分段,得到的每个分段数据记为趋势干扰数据;通过趋势分段点对当前维度的待处理数据进行分段,得到的每个分段数据记为趋势分段数据;
30、获取每个维度的若干趋势干扰数据及对应的趋势分段数据。
31、进一步的,所述得到每个维度每个趋势分段数据的干扰程度,包括的具体方法为:
32、根据不同维度的标准分段数据获取任意两个维度的关联性,得到每个维度的若干关联维度;以任意一个维度为当前维度,对于当前维度的任意一个趋势干扰数据进行emd分解,得到若干imf分量;获取该趋势干扰数据对应的趋势分段数据及趋势分段数据的分段起始点与分段终止点,根据分段起始点及分段终止点的次序在第p个关联维度的待处理数据中获取对应的分段数据,对每个imf分量与对应的分段数据计算皮尔逊相关系数,通过获取皮尔逊相关系数的最大值并与相似性阈值进行比较,得到第p个关联维度对于该趋势干扰数据对应趋势分段数据的干扰程度;
33、获取每个关联维度对于该趋势干扰数据对应趋势分段数据的干扰程度,将所有干扰程度的均值作为该趋势干扰数据对应趋势分段数据的干扰程度,获取当前维度每个趋势分段数据的干扰程度;获取每个维度每个趋势分段数据的干扰程度。
34、进一步的,所述根据不同维度的标准分段数据获取任意两个维度的关联性,包括的具体方法为:
35、以任意一个维度为当前维度,对于除当前维度之外的第m个维度,获取当前维度每个标准分段数据在第m个维度的对照分段数据、每个标准分段数据的起始分段点在第m个维度的对照起始点,以及每个标准分段数据的终止分段点在第m个维度的对照终止点;
36、当前维度与第m个维度的关联性γm的计算方法为:
37、
38、其中,tm,max表示当前维度的最优分段范围与第m个维度的最优分段范围中的最大值,表示当前维度的每个起始分段点与在第m个维度的对照起始点的次序值的差值绝对值的均值,表示当前维度的每个终止分段点与在第m个维度的对照终止点的次序值的差值绝对值的均值,表示当前维度每个标准分段数据与在第m个维度的对照分段数据的dtw距离的均值,exp()表示以自然常数为底的指数函数;
39、获取当前维度与其他每个维度的关联性,获取任意两个维度的关联性。
40、进一步的,所述当前维度每个标准分段数据在第m个维度的对照分段数据、每个标准分段数据的起始分段点在第m个维度的对照起始点,以及每个标准分段数据的终止分段点在第m个维度的对照终止点,具体的获取方法为:
41、以任意一个维度为当前维度,对于除当前维度之外的第m个维度,获取当前维度的每个标准分段数据的起始分段点与终止分段点,对每个起始分段点获取在第m个维度的若干标准分段数据中位置距离最小的起始分段点,作为每个起始分段点在第m个维度的对照起始点,所述位置距离表示起始分段点在待处理数据中的次序值之间的差异;
42、对于当前维度任意一个起始分段点,将该起始分段点的对照起始点对应的标准分段数据,作为当前维度该起始分段点对应的标准分段数据的对照分段数据,将对照分段数据的终止分段点作为该起始分段点对应的终止分段点的对照分段点;
43、获取当前维度每个标准分段数据在第m个维度的对照分段数据,以及每个终止分段点在第m个维度的对照终止点。
44、本发明的有益效果是:本发明通过对大量空调相关数据进行压缩处理,从而减小空调相关数据占用的存储空间,并提高空调操控系统的实时相应效率;通过对不同类型的空调相关数据进行自适应的预测编码压缩,避免不同维度数据之间存在干扰而影响压缩效果;其中在获取预测模型的过程中,根据当前维度的数据分布特征,通过待处理数据的周期性变化,结合分量之间的相似度来获取当前维度的共同分布特征,通过共同分布特征来提出当前维度的待处理数据中受干扰的部分;然后获取所有维度的数据中,与当前维度具有较强相关性的关联维度,并根据其他维度的数据与受干扰数据之间的相似性,通过emd分解得到的imf分量量化每个趋势分段数据的干扰程度,进而完成对差分阶数的修正,而每个趋势分段数据中数据变化趋势相同,实现对相同变化趋势的分段数据的自适应预测模型的获取,提高压缩效果,实现空调系统的操控。
本文地址:https://www.jishuxx.com/zhuanli/20240724/174543.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表