一种基于零和博弈的事件触发多无人车编队控制方法
- 国知局
- 2024-07-30 09:20:59
本发明属于工业控制,具体是涉及一种基于零和博弈的事件触发多无人车编队控制方法。
背景技术:
1、近年来,多智能体系统(mas)的协同控制与编队控制因其广泛的应用前景,如无人机(uav)、无人陆地车(ugv)编队以及多传感器网络过滤等,受到了广泛关注。通过高效的网络信息共享机制,mas能够比单一系统更高效地完成复杂任务。例如,无人机和无人陆地车等采用领导者-跟随者结构实现编队作业,极大地提升了在目标搜索和协同作业等任务中的效率。因此,mas的编队控制已成为当前研究的热点。
2、最优控制旨在通过最小化性能指标实现控制目标,以达成性能与资源的最佳平衡。最优控制理论上可以通过求解复杂的hamilton-jacobi-bellman(hjb)方程来获得最优的控制策略,但由于方程的高度非线性和求解难度,其解析解往往难以获得。为了突破这一限制,基于神经网络的强化学习(rl)被提出作为一种有效方案。近年来,已有许多学者开发了针对连续时间非线性系统、离散时间非线性系统、针对严格输出反馈等多种基于rl的最优控制器,通过rl识别神经网络来处理未知的动态问题,并通过执行网和评价网来学习最优控制输入与性能指标函数;但这种rl的计算复杂度与更新频率都较高,会给系统通信与计算资源带来一定的负担。
3、为了减轻通信负担和资源消耗,许多研究会引入事件触发机制,通过将事件触发机制与rl方法相结合,许多研究人员成功地将事件触发机制引用并应用于具有不确定性的非线性系统。进一步地,在约束输入控制的背景下,对于未知的非线性mas,有学者创新性地提出了事件触发的一致跟踪控制策略,将事件触发机制拓展到mas领域中,为这些复杂系统提供了更为灵活和高效的控制手段;但事件触发机制的引入会使系统更难以达到最优性能,导致性能损失。
4、如何设计有效的控制策略以平衡系统整体的优化和通信资源的利用,成为了一个亟待解决的问题。
技术实现思路
1、为解决上述技术问题,本发明提供了一种基于零和博弈的事件触发多无人车编队控制方法,设计了基于简化强化学习的控制方法,使控制输入复杂度更低更适合ugv的单片机的简单运算;引入事件触发机制,设计了基于事件触发的简化强化学习控制策略,能够有效降低系统信号更新频率;引入了零和博弈策略来设计控制器,在事件触发机制产生的误差与系统最优性之间进行博弈,取得事件触发误差与系统性能的均衡点,获得更适合ugv的编队的控制目标。
2、本发明所述的一种基于零和博弈的事件触发多无人车编队控制方法,包括以下步骤:
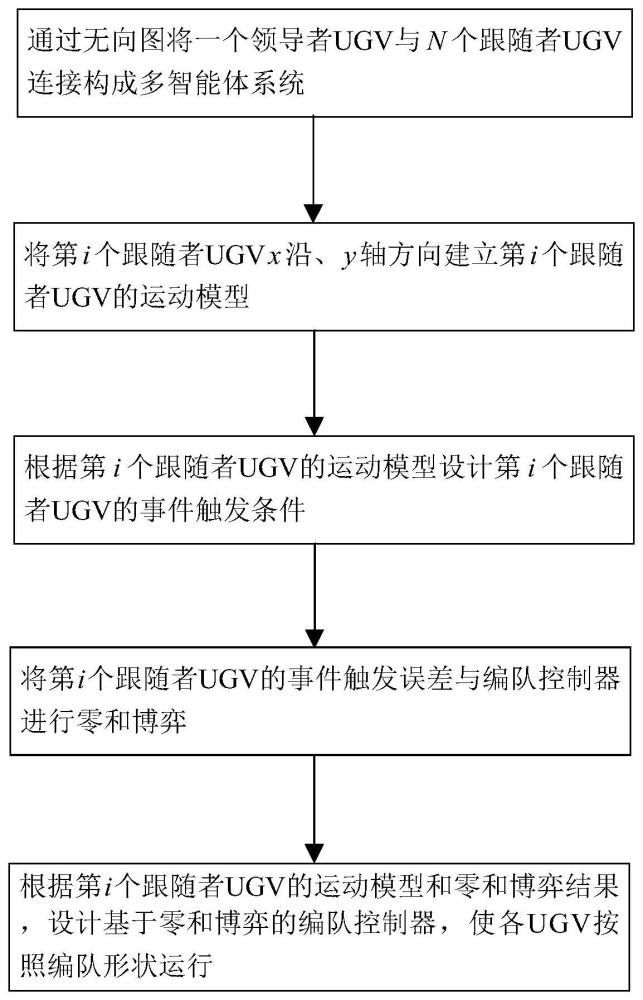
3、步骤1、通过无向图将一个领导者ugv与n个跟随者ugv连接构成多智能体系统;每个跟随者ugv的输入端均通过一个基于零和博弈编队控制器控制器与无向图连接;
4、步骤2、将第i个跟随者ugv沿x、y轴方向建立第i个跟随者ugv的运动模型,i=1,2,…,n;
5、步骤3、根据第i个跟随者ugv的运动模型设计第i个跟随者ugv的事件触发条件;
6、步骤4、根据所述事件触发条件,将第i个跟随者ugv的事件触发误差与第i个跟随者ugv的编队控制器进行零和博弈,得到基于零和博弈的性能指标函数;
7、步骤5、根据第i个跟随者ugv的运动模型和基于零和博弈的性能指标函数,更新所述基于零和博弈的编队控制器,并将满足触发条件的基于零和博弈编队控制器代入第i个跟随者ugv的运动模型中,使跟随者ugv按照编队形状运行。
8、进一步的,所述基于零和博弈编队控制器包括编队误差计算单元,识别神经网络单元,执行神经网络单元,评价神经网络单元,控制输入计算单元,触发误差估计单元,触发条件设计单元;
9、编队误差计算单元的输入端分别是无向图中的第j个跟随者的系统状态输出xj、领导者的邻接通信aij,领导者的邻接通信bi,第i个跟随者的系统状态输出xi,领导者的输出信息xd;
10、所述识别神经网络的输入端为第i个跟随者的系统状态输出xi,基于图论的编队误差ei;
11、所述评价神经网络输入端分别为第i个跟随者的系统状态输出xi与基于图论的编队误差ei;
12、所述执行神经网络单元的输入端分别为第i个跟随者的系统状态输出xi,基于图论的编队误差ei,评价神经网络的输出wcnn,i;
13、所述控制输入计算单元的输入端分别均为识别神经网络的输出基于图论的编队误差ei与执行神经网络的输出wann,i;
14、所述触发误差估计单元的输入端分别均为识别神经网络的输出基于图论的编队误差ei与执行神经网络的输出wann,i;
15、所述触发条件计算单元输入端分别为触发误差估计单元输出和由连续控制输入ui与基于触发的控制输入ui,p计算得到的触发误差zi,p;
16、i、j均为所述跟随者的编号,1≤i≤n,1≤j≤n,且i≠j。
17、进一步的,步骤2中,跟随者中第i个ugv的运动模型为:
18、
19、
20、
21、其中,与分别表示第i个ugv的横坐标位置pxi与纵坐标位置pyi的导数,vi表示线性速度,表示第i个跟随ugv的角方向θi的导数,ωi表示第i个跟随ugv的角速度;将(pxi,pyi)作为参考点,(pxi,pyi)表示第i个ugv的惯性位置,考虑(pxi,pyi)的控制问题,得到新的表述方程如下:
22、pxi=pxi+li cosθi
23、pyi=pyi+li sinθi
24、其中li为参考点到惯性点之间的距离;于是对上式求二阶导数,得到:
25、
26、然后,令
27、
28、
29、因此,第i个跟随ugv的动态模型重写为:
30、
31、其中,uxi与uyi为关于参考点的新的控制输入,fi1与fi2是有界扰动的非线性函数;那么,第i个跟随ugv的模型重新表述为以下表达式:
32、
33、
34、其中δi2=-ρiui+δi+fi+di,xi代表第i个跟随ugv的位置,vi代表第i个跟随ugv的速度,ui代表第i个跟随ugv的控制输入;δi1代表了不匹配扰动;ρi为一个连续函数,代表ugv的有效性故障损失严重程度;δi代表偏执故障;fi为非线性函数,di为第i个跟随ugv收到的外部扰动。
35、进一步的,仅在事件触发条件设计单元所设计的触发条件被违背时进行更新,触发后的系统状态记为xi(δk,i),其中δk,i表示第k个触发采样时刻;触发误差设计为:
36、zi,p=ui,p-ui
37、其中ui,p表示触发后的控制输入,设计触发误差估计值从以下式计算得到:
38、
39、触发条件设计为:
40、
41、进一步的,所述编队误差运算单元的输出ei表达式为:
42、
43、其中,ηi为第i个跟随者ugv与领导者之间的编队间隔,ηj为第j个跟随者ugv与领导者之间的编队间隔;
44、所述识别神经网络的输出信号计算公式为:
45、
46、其中,为识别神经网络的权值估计值,为激活函数;激活函数通过以下计算方式得到:
47、
48、其中,τi为识别神经网络的中心函数,μi为识别神经网络的宽度;
49、识别神经网络的权值估计值的更新律通过以下得到:
50、
51、其中,γi为待设计的识别神经网络控制参数,σi为调节神经网络近似误差的参数;
52、所述评价神经网络单元的输出计算公式为:
53、
54、其中,ωci为评价神经网络的权值的估计值,为激活函数;激活函数通过以下计算方式得到:
55、
56、其中,τi为神经网络的中心函数,μi为神经网络的宽度;其权值估计值的更新律通过以下得到:
57、
58、其中,κc,i为待设计的控制参数,为评价神经网络的权值估计值;
59、所述执行神经网络单元的输出计算公式为:
60、
61、其中,为执行神经网络的权值的估计值,执行神经网络的权值估计值的更新律通过以下得到:
62、
63、其中κa,i与κc,i为待设计的控制参数;
64、第i个跟随者的控制输入ui:
65、
66、其中,υi为基于图论的编队误差ei的控制参数;因为事件触发机制的引入,最终与第i个跟随者ugv输入端相连的控制输入为ui,p;当且仅当事件触发条件被违背时,控制输入信号更新,
67、
68、其中,δk表示第k个触发时刻。
69、本发明所述的有益效果为:
70、1)本发明构建了由多个ugv组成的多智能体系统的基于零和博弈的事件触发编队控制器,针对ugv编队控制问题设计了基于事件触发的控制策略,控制输入仅在事件触发条件被违背时更新,降低了跟随者ugv在控制器输出到ugv输入之间的更新频率,减少了ugv在编队控制中需要频繁更新所带来的计算负担;
71、2)本发明提出一种零和博弈框架,考虑事件触发产生的误差与编队控制的最优性二者进行博弈,实现局部最优编队控制;通过将触发误差zi,p=ui,p-ui与控制输入ui分别作为玩家参与零和博弈,在引入事件触发所导致的性能损耗与最优控制输入的最优性能之间通过零和博弈获得均衡点,从而实现对触发间隔与系统性能的平衡;
72、3)对于使用现有传统强化学习方法,设计的评价神经网络权值更新律应为其中αci是一个权值更新系数;而本发明基于简化强化学习方法,评价神经网络的权值更新律仅由hjb方程负梯度导出,为避免了hjb方程中残差平方的复杂计算;另外,本发明所述方法避免了求解偏微分方程和构造归一化项,降低了评价神经网络权值更新律的复杂度,减少了ugv编队控制的计算负担。
本文地址:https://www.jishuxx.com/zhuanli/20240730/149134.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。