基于多模块人脸识别的驾驶员车内接打手机检测方法和装置
- 国知局
- 2024-07-31 22:41:13
本发明涉及驾驶员车内接打手机检测方法领域,具体涉及基于人脸识别的接打手机检测方法和装置。
背景技术:
1、目前大多交通执法部门通过交叉路口门架摄像头对驾驶员接打手机进行拍摄监督,采用图像识别算法对于接打手机目标进行识别检测,但仍存在一定问题。1)车流量较大或车速较快时,手机本身体积较小,且使用者通常是手握状态,遮挡率较大,因此存在较高漏检率。2)存在部分顾客仅仅是拿取或挪动,未进行接听电话操作,存在一定误检率。3)部分算法采用手势检测方法,对于擦嘴等与接打手机抬手相似动作存在较大的误检。针对上述问题,以及面对未来智能网联汽车车内外的充裕视觉设备发展趋势,亟需一种车内接打手机检测方法,提高手机的小目标检测,以及驾驶员操作的精确匹配。
2、
技术实现思路
1、本发明要克服现有技术的上述缺点,提供车内基于多模块人脸识别的驾驶员接打手机检测方法和装置。
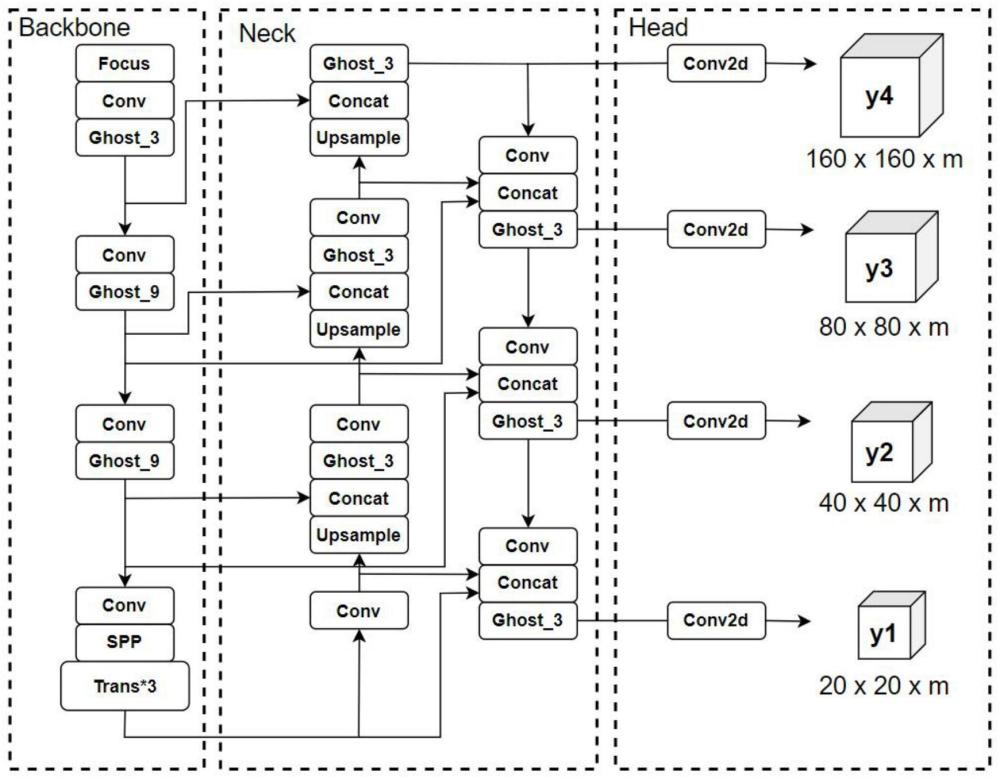
2、本发明接打电话检测方法中含目标检测算法、目标跟踪算法和人脸关键点检测算法,并针对于目标检测算法和人脸关键点检测算法两个算法进行改进,并降低整体模型参数量、计算量,更适用于嵌入式设备的应用。并在保证检测速度的前提下,达到对于手机的小目标检测,以及人脸嘴部区域与手机的重合度检测。
3、本发明的技术方案是:
4、基于人脸识别的驾驶员车内接打手机检测方法中,对于目标检测算法和人脸关键点检测算法进行改进,降低两个算法的参数量、计算量,更适合于嵌入式设备的应用,并提高对于手机的小目标检测精度,以及降低遮挡情况下漏检率。由于目标跟踪算法的作用仅是对于已检测到的目标定位追踪,因此不做改变。
5、车内基于多模块人脸识别的驾驶员接打手机检测方法,具体包括如下步骤:
6、步骤1获取图像数据集。车内摄像头或其他视觉设备实时录像,将视频流传输至嵌入式设备或传输至云端等,将接收到的视频直接作为训练后目标检测算法的输入进行实时检测,过程如下:
7、步骤1.1:将目标检测算法主干网络瓶颈层的特征提取算法更改为轻量化网络结构,本发明采用由华为提出的新型的端侧神经网络架构ghostnet组成的ghostbottle。在满足相同通道数量的前提下,特征提取能力增强,大幅度减少了整体模型的计算量和参数量,利于该检测算法在嵌入式设备中使用,提高检测速度。
8、步骤1.2:目标检测算法的主干网络末端增加注意力机制算法,通过对于各个通道赋予权重,强化特征提取。可以从不同的特征空间中学习自适应注意力分布,增强了对于遮挡目标物的特征提取能力,降低漏检率。
9、步骤1.3:多次下采样会导致图像中小目标特征消失,导致模型网络无法学习到相应的特征,对于手机等小目标物易出现漏检。目标检测算法保留原始检测维度,不降低原有尺度特征学习能力,增加连接层、卷积层、瓶颈层,并再次进行上采样和下采样,将主干网络中保留较多小目标特征信息的同尺度特征层输入连接层,进行特征融合操作。新增检测层对于小目标特征更为敏感,利于对于手机小目标的检测。由于增加了检测层检测尺度多样性,采用遗传算法对于自定义数据集进行分析计算,获得该数据集各尺度所需预测锚框。
10、步骤1.4:采用concat连接层对于不同层级但尺度相同的特征层进行融合,减少特征丢失,将目标检测算法的主干网络多层计算结果一次或多次输入加强特征提取网络。加强特征提取网络分为两个部分,自下而上结构和自上而下结构。自下而上的部分对于两个同尺度特征进行融合;到自上而下结构时,对于三个同尺度特征利用跳跃连接的方式进行融合,并在经过瓶颈层后输出,对于多个不同尺度目标进行预测。利用双向特征金字塔网络结构,使得预测网络对于不同大小的目标更为敏感,提升整体模型检测能力,并降低了漏检率与误检率。
11、步骤2:目标检测算法对于手机以及驾驶员进行实时检测。目标跟踪算法将目标检测算法识别后的预测框作为输入,对于目标物进行实时跟踪。本发明采用孪生全连接神经网络siamesefc(siamese fully-connected neural network)目标跟踪算法,利用目标跟踪算法对手机进行计数和追踪,过程如下:
12、步骤2.1:当检测到手机后,首先利用目标跟踪算法对手机进行标记计数并区别,例如手机-1,同时截取首次标记目标物的单帧图像作为全景图片留存,便于后续人工判别。
13、步骤2.2:输出实时跟踪后获得手机的标记值以及检测框实时参数(xc,yc,wc,hc),xc,yc表示手机检测框的中心点,wc,hc表示手机检测框的宽与高。
14、步骤2.3:若手机检测框实时参数在一定时间内不发生改变,则认定该目标物被抛弃或未被使用,保留该手机检测框标记值,但不作为步骤3.2与步骤5比对目标,直至该目标物的实时参数发生改变。
15、步骤3驾驶员检测及技术,过程如下:
16、步骤3.1:目标检测算法同时对驾驶员进行标记并实时跟踪,输出实时跟踪后获得驾驶员的标记值以及检测框实时参数(xr,yr,wr,hr),xr,yr表示驾驶员检测框的中心点,wr,hr表示驾驶员检测框的宽与高。
17、步骤3.2:当手机检测框与驾驶员检测框存在重叠时,对于重叠的驾驶员检测框标记计数进行区别,例如驾驶员-1。
18、步骤3.3:同时回传驾驶员标记值与驾驶员检测框实时参数(xr,yr,wr,hr)。当标记的手机检测框结束与驾驶员检测框重叠时,舍弃该驾驶员检测框标记,同时停止回传实时参数。
19、步骤4人脸关键点检测识别,过程如下:
20、步骤4.1:将人脸关键点检测算法主干网络瓶颈层的特征提取算法更改为轻量化网络结构,本发明采用ghostbottle网络结构,并对于每个层的特征数量进行调整。调整后模型整体计算量与参数量更小,更利于该检测算法在嵌入式设备中使用,提高检测速度。人脸面部关键点算法较于图像识别算法,对于人脸识别更为精准,驾驶员脸部存在部分遮挡或驾驶员侧脸、抬头、低头等行为均可以进行高精度关键点检测,更利用与后续手机识别后检测框的重合度比对。
21、步骤4.2:将步骤3.3中含有驾驶员检测框标记的目标图像作为人脸关键点检测算法的输入,进行驾驶员脸部关键点检测,并保留嘴部关键点,将关键点进行连接,形成精准的嘴部区域。当检测时关键点缺失时,例如驾驶员侧脸时,将形成的嘴部区域以其中心点为放缩原点,将区域放大。
22、步骤5接打手机操作判定。将步骤4.2中检测到的嘴部区域与带有标记的手机检测框实时参数进行比对,若发生重叠且重叠时间超过设定阈值,则判定该驾驶员为接打手机者,并截取判定时的检测框图像,利用人工判定。以及截取该驾驶员人脸图像,便于后续结合其他设备,进驾驶员脸比对。
23、本发明的第二个方面涉及车内基于多模块人脸识别的驾驶员接打手机检测装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现本发明的车内基于多模块人脸识别的驾驶员接打手机检测方法。
24、本发明的第三个方面涉及一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现本发明的车内基于多模块人脸识别的驾驶员接打手机检测方法。
25、该驾驶员接打手机检测算法截取的全景图像、驾驶员接打手机图像、驾驶员人脸图像均可以传至监控平台,代替人工进行24小时不间断检测,人工仅需要根据检测到的图像进行二次判断,及时定位接打电话者,进行处罚或劝导。
26、本发明的工作原理:目标检测算法、目标跟踪算法、人脸关键点检测算法三者协同配合。目标检测算法完成手机、驾驶员人脸检测;目标跟踪算法对于检测到的目标物进行实时跟踪。当检测到手机时进行标记计数区别,并且对于与该检测框存在重叠的驾驶员检测框进行标记计数区别,缩小接打手机确认范围。人脸关键点检测算法对于含有标记计数的驾驶员检测框进驾驶员脸关键点检测,确定嘴部区域,与手机检测框进行重合度比对,完成重合且重合时间超过设定阈值时确定为接打手机者。在保证检测速度的前提下,完成对于像手机小目标的检测,以及人脸嘴部区域与手机的重合度检测,大幅度减少了人工成本,仅需对于检测到的图像内容进行二次判断。
27、本发明的优点是:对于初始的目标检测算法、人脸关键点检测算法提出了改进方法,降低整体检测算法参数量、计算量,同时提高对于驾驶员与手机重叠、遮挡时的检测性能,和手机小目标检测性能;通过对于驾驶员接打手机时嘴部区域的识别与手机目标重合度的计算,完成对于驾驶员接打手机动作的确认,提高对接打手机者检测准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194122.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。