基于遗忘恢复学习的增强深度神经网络公平性方法及装置
- 国知局
- 2024-07-31 22:40:53
本发明涉及一种公平性模型,具体涉及一种基于遗忘恢复学习的增强深度神经网络公平性方法及装置。
背景技术:
1、随着chatgpt等人工智能技术的飞速发展,这些技术在金融科技、生物医药等领域的交叉研究和应用日益增多。特别是深度神经网络模型,因其强大的学习能力,能够处理复杂、海量且高维的数据,从而在多个行业中发挥重要作用。这些模型通过挖掘数据中的规律和特征,促进了行业的创新和发展。
2、近年来,深度神经网络的公平性研究愈发受到研究者重视。模型的偏见问题往往源于其训练数据。在机器学习和深度学习中,数据是模型学习和形成判断的基础。如果这些数据不全面或存在偏差,比如某些群体的数据被过度代表或者被忽略,模型就可能学习并复制这些偏见。这种情况在使用历史数据训练模型时尤为常见,因为历史数据可能反映了过时或偏颇的社会观念。特别是计算机视觉模型中存在的偏见问题逐渐显露,引起了社会各界的关注。一个显著的例子是buolamwini和gebru的研究,他们发现某些机器学习模型在对特定类别的预测中存在准确性差异。例如,这些模型对于微笑情绪的个体相比于惊讶情绪的个体,预测准确率较低。这一发现揭示了现代ai技术的局限性,特别是在公平性和偏见问题上,凸显了进一步改进和监管这些技术的重要性。尽管通过使用无偏见的训练数据进行微调是消除预训练模型中偏见的常用方法,但这种方法在实践中往往效果有限。在模型微调过程中,不同种族子群体的数据可能产生相互冲突的梯度,导致微调效果不佳。这主要是因为模型在之前的训练过程中已经学习了与主导群体(高准确性群体)相关的偏见特征,通过简单的微调难以消除这些偏见。
3、现有的公平性改进方法大致可分为三类:预处理方法、处理中方法和后处理方法。这些方法在已部署的机器学习模型中改善公平性时存在显著局限性。首先,预处理方法侧重于调整训练数据以减少偏见,但其效果严重依赖于数据的质量和全面性。如果原始数据集中已经存在严重的偏见或数据样本不足,仅靠预处理难以彻底解决问题。其次,处理中方法,如修改学习算法或损失函数,试图在模型训练过程中直接减少偏见。然而,这些方法可能会在保持模型性能和减少偏见之间产生权衡,特别是在复杂或不平衡的数据集上。最后,后处理方法通过调整模型的输出来提高公平性,但这种方法可能会牺牲模型的整体准确性,尤其是在数据资源有限的情况下。
4、总体而言,这些公平性改进方法的有效性很大程度上取决于可用数据的质量和多样性。在数据质量不佳或样本不足的情况下,这些方法可能难以达到预期效果。此外,这些方法往往关注单一维度的公平性,而忽视了多维度交叉的复杂性,这可能导致在一个维度上取得进展的同时,在其他维度上产生新的偏见。因此,现有技术在数据资源有限的情况下,还无法有效地消除模型中针对某些敏感群体的偏见,并且无法保证整体模型性能的平衡。
技术实现思路
1、本发明是为了解决上述问题而进行的,目的在于提供一种基于遗忘恢复学习的增强深度神经网络公平性方法及装置。
2、本发明提供了一种基于遗忘恢复学习的增强深度神经网络公平性方法,用于根据偏见数据集和对应的预训练模型得到具有公平性的微调模型,具有这样的特征,包括以下步骤:步骤s1,将偏见训练集划分为对应不同群体的多个子训练集;步骤s2,计算预训练模型在各个子训练集上的识别准确率;步骤s3,将最高的识别准确率对应的子训练集作为主导训练集;步骤s4,从主导训练集中随机选取多个样本构建第一数据集;步骤s5,将第一数据集中的各个样本的标签进行随机更改,得到偏差数据集;步骤s6,根据偏差数据集对预训练模型进行训练,得到训练好的预训练模型作为选择性遗忘模型;步骤s7,从各个子训练集中选取多个样本构建平衡数据集;步骤s8,根据平衡数据集对选择性遗忘模型进行微调,得到微调好的选择性遗忘模型作为微调模型。
3、在本发明提供的基于遗忘恢复学习的增强深度神经网络公平性方法中,还可以具有这样的特征:其中,在步骤s5中,根据偏见训练集中各个样本对应的所有标签的范围,对第一数据集中的各个样本的标签进行随机更改。
4、在本发明提供的基于遗忘恢复学习的增强深度神经网络公平性方法中,还可以具有这样的特征:其中,在步骤s6中,通过最小化第一损失函数lforget对预训练模型进行训练,第一损失函数lforget的表达式为:lforget=-σi∈dflogp(yrandom|xi;θ),式中df为偏差数据集,xi为偏差数据集中的样本,yrandom为样本xi对应的随机更改后的标签,p(yrandom|xi;θ)为预训练模型对输入的样本xi的预测输出,θ为预训练模型的参数。
5、在本发明提供的基于遗忘恢复学习的增强深度神经网络公平性方法中,还可以具有这样的特征:其中,在步骤s7中,根据偏见训练集中各个样本对应的所有标签的标签类型,从每个子训练集中选取对应各个标签类型的n个样本,构建得到平衡数据集。
6、在本发明提供的基于遗忘恢复学习的增强深度神经网络公平性方法中,还可以具有这样的特征:其中,在步骤s8中,通过最小化第二损失函数lrecovery对选择性遗忘模型进行微调,第二损失函数lrecovery的表达式为:lrecovery=-∑i∈dlogp(yi|xi;θ),式中d为平衡数据集,xi为平衡数据集中的样本,yi为样本xi对应的标签,p(yi|xi;θ)为选择性遗忘模型对输入的样本xi的预测输出,θ为选择性遗忘模型的参数。
7、在本发明提供的基于遗忘恢复学习的增强深度神经网络公平性方法中,还可以具有这样的特征:其中,偏差数据集和平衡数据集中的样本总数量均为a*b,a为子训练集的个数,b为样本总数最小的子训练集中c%个样本对应的数量。
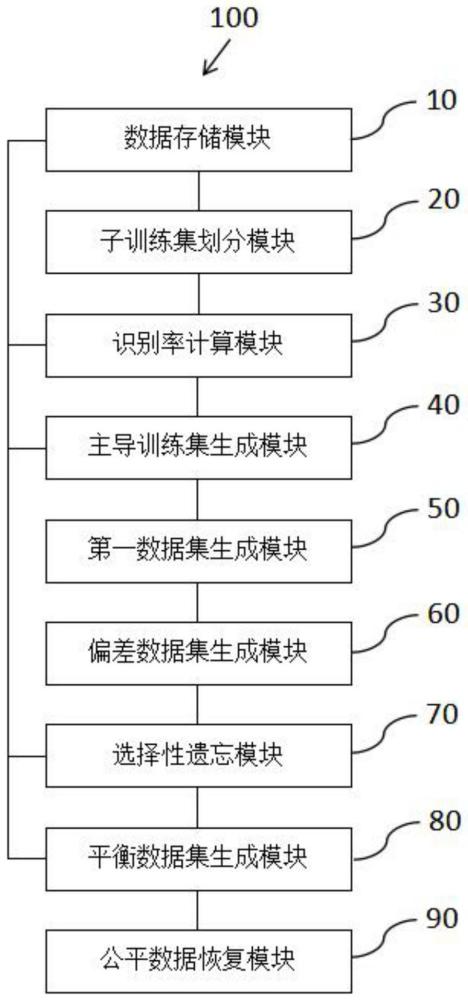
8、本发明还提供了一种基于遗忘恢复学习的增强深度神经网络公平性装置,用于根据偏见数据集和对应的预训练模型得到具有公平性的微调模型,具有这样的特征,包括:数据存储模块,用于存储偏见数据集和预训练模型;子训练集划分模块,用于将偏见训练集划分为对应不同群体的多个子训练集;识别率计算模块,用于计算预训练模型在各个子训练集上的识别准确率;主导训练集生成模块,用于将最高的识别准确率对应的子训练集作为主导训练集;第一数据集生成模块,用于从主导训练集中随机选取多个样本构建第一数据集;偏差数据集生成模块,用于将第一数据集中的各个样本的标签进行随机更改,得到偏差数据集;选择性遗忘模块,用于根据偏差数据集对预训练模型进行训练,得到训练好的预训练模型作为选择性遗忘模型;平衡数据集生成模块,用于从各个子训练集中选取多个样本构建平衡数据集;公平数据恢复模块,用于根据平衡数据集对选择性遗忘模型进行微调,得到微调好的选择性遗忘模型作为微调模型。
9、发明的作用与效果
10、根据本发明所涉及的基于遗忘恢复学习的增强深度神经网络公平性方法及装置,因为,一方面,通过从主导训练数据集中选取多个样本并随机更改对应的标签构建的偏差数据集对预训练模型进行训练,从而使预训练模型遗忘主导特征得到选择性遗忘模型;另一方面,通过群体和标签都均衡的平衡数据集对选择性遗忘模型进行微调,得到恢复预测能力且无偏见的微调模型。所以,本发明的基于遗忘恢复学习的增强深度神经网络公平性方法及装置能够提升公平性的同时保持模型预测准确率。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194111.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表