一种基于YOLO模型的古契约文书文字识别方法
- 国知局
- 2024-07-31 22:40:48
本发明涉及深度学习与目标检测,具体涉及一种基于yolo模型的古契约文书文字识别方法。
背景技术:
1、少样本多类别的目标检测问题属于计算机视觉领域问题,其一般定义为:在一个含有少量样本(不超过1000张图片)的数据集中,每张图片中都含有大量的目标(200个以上)待识别,且数据集中含有的类别不少于1500个;任务是训练模型,使其能够在这些少量样本的基础上学习到每个类别的特征,并能够在新的图像中准确检测和识别这些类别的目标。
2、目前,目标检测领域所包含的算法通常分为一阶段检测算法(如you only lookonce(yolo)算法,直接在网络的最后输出目标的类别和位置信息)和两阶段检测算法(如fast-r-cnn,首先生成一系列候选区域,之后再对这些候选区域进行分类和边界框回归)。一阶段检测算法相较于两阶段检测算法速度更快,但精度稍差。然而,这些模型目前在少样本、含有大量类别的数据集上表现较差。因此需要设计新的方法来提高在这些数据集上的目标识别准确率。
技术实现思路
1、为了克服现有技术在少样本、多类别的数据集上表现较差的问题,本发明提供一种基于yolo模型的古契约文书文字识别方法。
2、为达到上述目的,本发明采用以下技术方案予以实现:
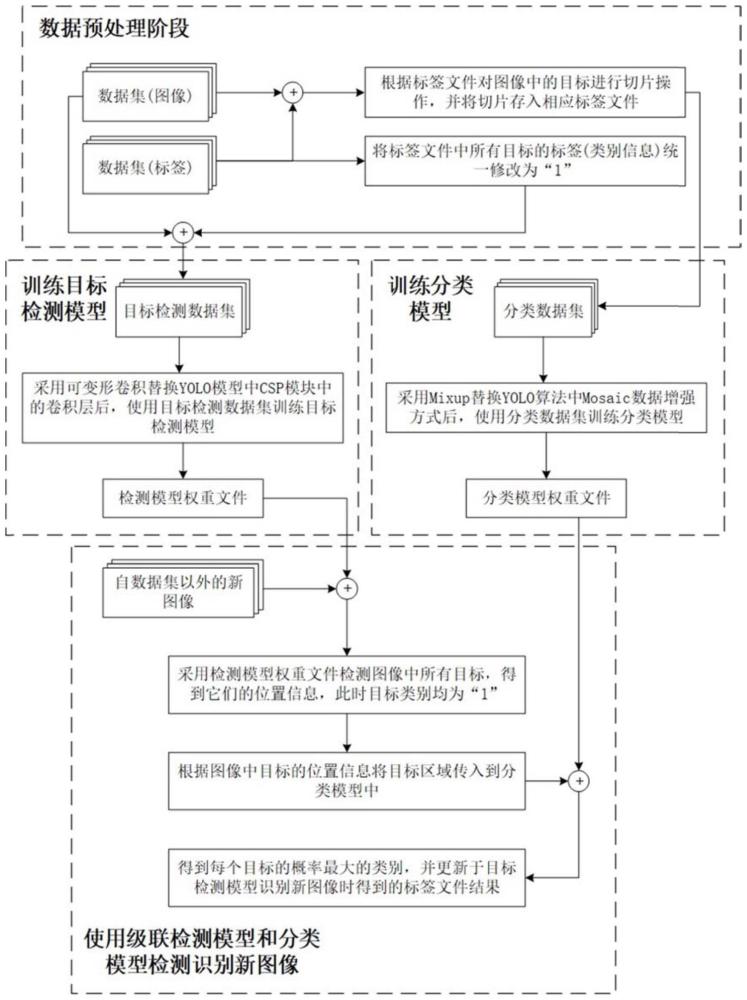
3、一种基于yolo模型的古契约文书文字识别方法,包括以下步骤:
4、步骤1,将含有多个目标,且类别不一的单张样本根据其yolo格式标签文件中的目标定位信息进行切片,并将其切片存入到其对应的yolo格式标签文件夹中,得到标签文件夹集;如果标签是中文,则将其编号,建立中文与编号的映射,并将其存入到一个词典中;
5、步骤2,将标签文件中所有的标签信息统一修改为“1”,视所有目标均为正样本;
6、步骤3,使用已修改标签文件的数据集训练yolo目标检测模型,使其能够学习到所有正样本的特征,并在新的图像中能够准确检测出所有目标并找到它们的位置信息;
7、步骤4,使用步骤1中所得到的标签文件夹集作为分类模型数据集,训练yolo分类模型,使其能够学习到所有类别的特征,并能够在新的图像中正确识别出该图像是否为一个目标,是何目标;
8、步骤5,在识别新图像时,先使用步骤3中训练好的yolo目标检测模型定位图像中所有目标,得到具有定位信息的检测结果;
9、步骤6,根据检测结果中的定位信息将目标区域图像传入到步骤4中训练好的yolo分类模型,得到其类别信息;如果该检测任务存在步骤1中所述的词典信息,则需根据该词典找到类别信息所映射的真实标签;
10、步骤7,将步骤6中最终得到的标签信息更新于步骤5中得到的检测结果中。
11、进一步,所述步骤1中yolo格式标签文件,以“.txt”为文件扩展名,且单个标签信息为<类别信息><目标中心点x坐标><目标中心点y坐标><目标的宽带><目标的高度>,其中目标的坐标信息均已归一化处理。
12、进一步,所述步骤3中所述yolo目标检测模型为采用可变形卷积csp模块替换yolo目标检测模型中的csp模块得到的可变形卷积改进yolo模型。
13、进一步,所述步骤4中yolo分类模型中数据增强方法为mixup方法,通过线性插值的方式混合两张图像及其对应的标签,生成新的训练样本;
14、具体为,给定两个图像x1和x2及其标签y1和y2,mixup按照以下公式生成新的图像和标签:
15、x=λx1+(1-λ)x2;
16、y=λy1+(1-λ)y2;
17、其中,λ为beta(10,10)分布中抽取的,使得λ大部分情况接近0.5。
18、进一步,所述步骤5中检测结果将保存到yolo格式文件,其中所有目标均被视为正样本,且能够得到它们的位置信息;此时,得到的目标标签均为“1”。
19、相对于现有技术而言,本发明具有以下有益效果:
20、1.考虑到单张契约文书中所包含的古汉字通常在200个以上,且目前已标注的数据集较少,本发明主要采用了以yolo模型为基础的目标检测算法。因yolo算法在处理含有大量类别且图片样张较少的数据集的表现较差,因此本发明将契约文书中古汉字的识别任务拆分为了两个阶段,即古汉字的定位和分类。通过级联两个模型(目标检测模型和分类模型)可以单独训练和优化,提供较高的灵活性。
21、通过使用少样本、多类别数据集分别训练一个目标检测模型和一个分类模型,再通过级联的方式检测新的图像。其中目标检测模型仅检测图像中的所有目标,并找到它们的位置信息,并不会直接识别出它们的类别;分类模型仅识别所有目标区域中的目标类别。
22、级联方式是指首先使用目标检测模型对图像中的目标文字进行定位,再通过定位信息将图像中的目标区域传入分类模型中得到它们的类别,完成新图像的检测识别任务。相比传统的依赖单模型完成少样本、多类别数据集的检测识别方法,级联方式能够更好的定位目标、并识别其类别,具有更强的灵活性、泛用性及准确率。
23、2、本发明所使用的检测模型和分类模型均源于yolo模型,在特定情况可以替换为更适用于不同任务的模型。在调试过程中,可以单独评估每个模型的性能,更容易定位问题所在。并在不同阶段对yolo的检测模型和分类模型进行了适当改进,最后通过模型级联的方式识别新的契约文书中的古汉字。
24、本发明通过引入可变形卷积算法改进yolo的骨干网络,采用可变形卷积技术对yolo目标检测模型中的csp模块进行改进,使模型的感受野得到极大的提升,使得模型在训练时能够观察到更多的上下文信息,便于区分汉字与背景信息;并引入额外的可学习的偏移量来增加卷积核的空间采样位置的灵活性,这使得卷积核可以自适应地调整其形状以更好地适配图像中的目标形状和尺寸。
25、3.本发明采用mixup替换yolo模型中的mosaic数据增强方式,使得该方法能够适用于包含文字、数字的数据集,提高了模型的泛用性。
26、本发明将以上三个机制相结合,可以有效提升级联模型在少样本、多类别数据集上的准确率。通过级联检测模型和分类模型的方式,在检测新图像时进行特殊的后处理,在仅有500张古文地契数据集的情况下,最终的识别精度仍然能够达到90%以上。
技术特征:1.一种基于yolo模型的古契约文书文字识别方法,其特征在于包括以下步骤:
2.如权利要求1所述的基于yolo模型的古契约文书文字识别方法,其特征在于:所述步骤1中yolo格式标签文件,以“.txt”为文件扩展名,且单个标签信息为<类别信息><目标中心点x坐标><目标中心点y坐标><目标的宽带><目标的高度>,其中目标的坐标信息均已归一化处理。
3.如权利要求1所述的基于yolo模型的古契约文书文字识别方法,其特征在于:所述步骤3中所述yolo目标检测模型为采用可变形卷积csp模块替换yolo目标检测模型中的csp模块得到的可变形卷积改进yolo模型。
4.如权利要求1所述的基于yolo模型的古契约文书文字识别方法,其特征在于:所述步骤4中yolo分类模型中数据增强方法为mixup方法,通过线性插值的方式混合两张图像及其对应的标签,生成新的训练样本;
5.如权利要求1所述的基于yolo模型的古契约文书文字识别方法,其特征在于:所述步骤5中检测结果将保存到yolo格式文件,其中所有目标均被视为正样本,且能够得到它们的位置信息;此时,得到的目标标签均为“1”。
技术总结本发明公开了一种基于YOLO模型的古契约文书文字识别方法,通过使用少样本、多类别数据集分别训练一个目标检测模型和一个分类模型,级联两个模型可以单独训练和优化,提供较高的灵活性,目标检测模型仅检测图像中的所有目标,并找到它们的位置信息,并不会直接识别出它们的类别;分类模型仅识别所有目标区域中的目标类别;相比传统的依赖单模型完成少样本、多类别数据集的检测识别方法,级联方式能够更好的定位目标、并识别其类别,具有更强的灵活性、泛用性及准确率。技术研发人员:陈莉,何前宝,郝星星,张瑞帮,马亮,韩志周受保护的技术使用者:西北大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/194104.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。