一种基于认知智能的连铸行业混合大模型在线数据处理方法与流程
- 国知局
- 2024-07-31 22:46:31
本发明属于连铸领域,具体涉及基于数据的连铸行业混合大模型数据处理方法,使用大模型进行在线数据处理。
背景技术:
1、申请号为cn202080084734.6的中国专利,提供了一种处理数据的方法,包括:接收针对多个机器学习模型的全局参数集合;根据该全局参数集合用该多个机器学习模型来处理本地地本地地存储在处理设备上的数据以生成机器学习模型输出;在该处理设备处接收关于针对该多个机器学习模型的机器学习模型输出的用户反馈;基于机器学习输出和用户反馈来执行对该多个机器学习模型的优化以生成经本地更新的机器学习模型参数;将经本地更新的机器学习模型参数发送到远程处理设备;以及接收针对多个机器学习模型的经全局更新的机器学习模型参数集合。该混合模型的技术特点主要采用机器学习的模型进行参数融合,通过机器学习的模型进行参数优化,并非采用人工智能的模型进行融合。
2、申请号为cn201510447779.6的中国专利,提供了一种混合模型及基于混合模型的连铸漏钢预报方法,属于冶金连铸中监控技术领域。混合模型包括:基于ga-bp神经网络的单偶时序模型和基于逻辑判断的组偶空间模型。该预报方法的步骤为:1)监控结晶器温度并存储数据;2)将数据输入单偶时序模型,判断每个热电偶温度随时间变化是否符合粘结时温度变化波形,将判断结果保存到数组y(i,j,t)中;3)当y(i,j,t)在阀值范围[θmin,θmax]内时,标记该热电偶异常,计算第i行、i-1行异常热电偶数目分别为m、n;4)利用m+n与粘结报警和粘结警告热电偶数目阀值比较进行粘结判断。本发明实现了提高粘结性漏钢识别精度的目标。该技术特点是通过ga-bp神经网络进行模型的耦合,通过神经网络监控来进行漏钢识别,并不适用于连铸在线数据处理。
技术实现思路
1、目前在连铸行业生产线中数据主要通过底层的plc进行采集到上层数据处理平台中,目前数据的基本处理方法还是基于已有的规则形式进行处理,并不具备智能化的数据处理方法,本发明主要阐述了一种基于认知智能的数据处理混合大模型的方法,进行模型的训练与分析,通过该方法可以实现大模型的训练及推理,可以实现大模型的持续训练及运用。
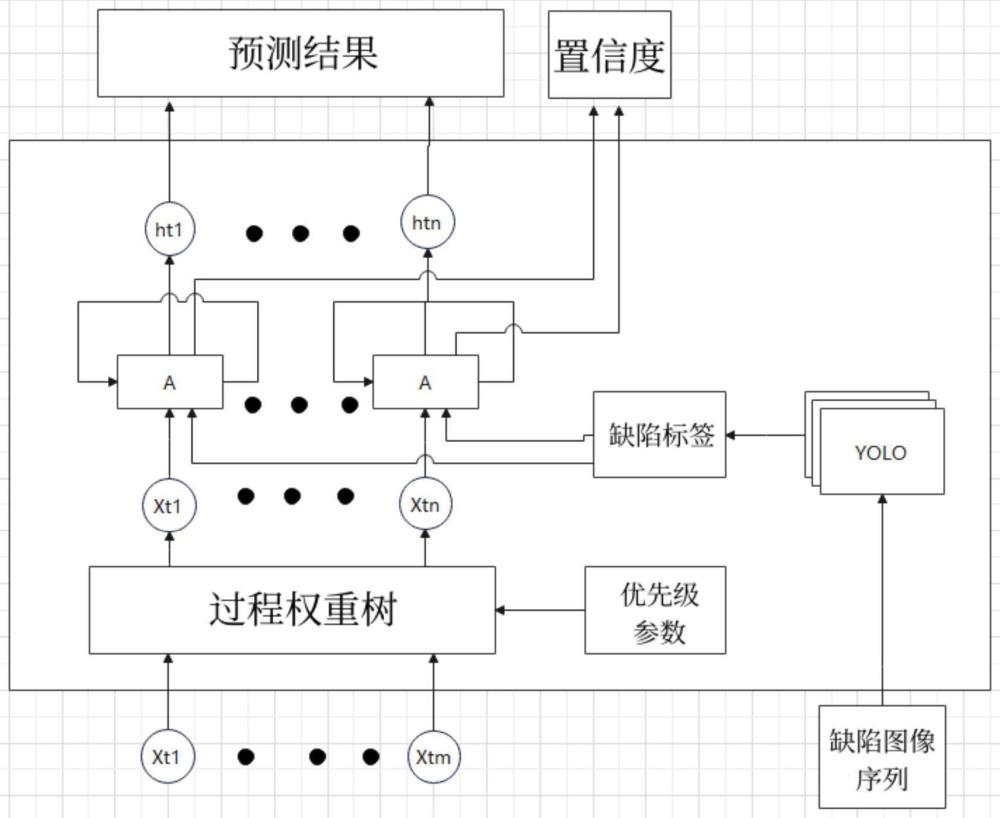
2、本发明提供一种基于认知智能的连铸行业混合大模型在线数据处理方法,具体包括:
3、在现有数据资源基础上,通过网络实现连铸数据的全面贯通,利用底层的通信协议进行对接,从而确保连铸数据的准确收集。随后,将连铸数据统一上传至数据平台。
4、在生产过程中,利用质量判定系统对生产线数据进行实时定位,从而精准获取当前生产状态下的过程实时参数数据。
5、在生产现场,使用表面缺陷检测装置对连铸坯质量进行对应的检测。这些实时检测到的表面缺陷数据,作为大模型系统的打标数据;大模型系统的打标数据在生产线的持续运行中不断地获取。这些打标数据反馈至连铸行业混合大模型,作为连铸行业混合大模型修正和优化的重要依据,从而不断提升连铸行业混合大模型的预测准确性和可靠性。
6、优选的,连铸行业混合大模型由数据预测大模型和视觉识别大模型这两类模型共同混合形成,二者是耦合形成的。
7、优选的,数据预测大模型,基于现场生产线过程中会产生大量的训练数据,故将现有生产线的训练数据作为数据预测大模型训练的养料。通过该数据训练和优化大模型的检测和认知评判能力,以持续优化和提升其预测性能。
8、优选的,数据预测大模型的主体结构为多维长短时神经网络,由于普通的lstm(长短时记忆网络)只具备1维的向量,并不适用于多参数下连铸行业混合大模型,因此需要通过拓展维度来进行神经网络拓展。
9、当前连铸机生产线当中工艺参数的重要程度来划分预测大模型,结构如下:xt1……xtm为连铸机生产线中的工艺参数总数m;通过过程权重树进行工艺参数调节,筛选重要的工艺参数;其中,筛选原则为:根据重要程度的优先级来进行相应的参数划分,优先级部分以参数设定的方式进行设置,并作用于过程权重树,通过权重的调整对工艺参数排序,进而筛选出重要的工艺参数输入xt1~xtn。其中,权重树计算方式下:
10、[xt1........xtn]=sort[w1,w2........wn][xt1,xt2,........xtm]t
11、优选的,在循环神经网络结构下,原有1维的神经网络拓展到n维,每个网络的预测模块均可以输入两种类型的数据,在筛选后的工艺参数变量被输入的同时,还将缺陷标签数据加入其中。随后,这些数据经过视觉识别大模型的处理,生成相应的缺陷信号数据,这些缺陷信号数据将被用作打标的缺陷数据。
12、优选的,采用循环神经网络及经过改进的lstm网络,输出得到ht1至htn的预测数据。这些数据不仅包含输入的工艺参数,还融合了相关的视觉模型图像信息。连铸行业混合大模型的结构为混合的数据及视觉大模型结构,在输出预测结果的同时,模型内部还会输出置信度信息,对预测数据进行置信度打分,便对输出结果进行评判。
13、优选的,基于预测数据的短时记忆特性,在短时记忆环节特别设置了一个记忆时长。该记忆时长能够有效限定预测数据的宽度,超出该时长的记忆将被退出模型。上述做法可以确保预测数据在特定时间段内具备相应的预测能力,同时避免模型因尺寸过大而导致预测时间过长,出现系统卡死等情况。
14、优选的,在连铸行业混合大模型中,针对defect label设计了缺陷认知功能。具体而言,利用yolo模型进行初步评判后,该功能能够识别出具有缺陷特征的普通图片。通过对这些缺陷进行详细的识别,识别出缺陷对应的类别以及缺陷对应的位置坐标,映射到相应的板坯上作为标签反馈数据进入混合大模型。
15、优选的,为提升认知功能,选用基本的连铸板坯缺陷数据集来进行数据相关的认知知识识别训练,通过加入缺陷知识来进行缺陷认知能力的提高。
16、优选的,整体的认知功能主要采用认知推理引擎方式进行驱动,在认知推理引擎中加入缺陷等知识信息,形成针对连铸缺陷相应的认知模块,对表面视觉数据来产生缺陷标签的效果。
17、有益效果:
18、首先,本发明通过全面贯通连铸数据,实现了数据的高效收集与整合;利用数据预测大模型和视觉识别大模型的混合,有效提升了模型对连铸过程的多维度认知,进一步增强了模型的预测准确性和可靠性。其次,本发明将现有生产线的训练数据作为数据预测大模型训练的养料,并经持续的数据训练和优化,提升了模型的检测和认知评判能力。此外,本发明通过拓展神经网络的维度,使之适用于多参数下的连铸行业混合大模型,提高了模型的适用性和预测精度。本发明亦利用循环神经网络及改进的lstm网络,结合筛选后的工艺参数和缺陷标签数据,生成了准确的缺陷信号数据。本发明针对预测数据的短时记忆特性,设置了记忆时长,有效避免了模型预测时间过长和系统卡死等问题,保证了模型的稳定性和实时性。最后,本发明利用yolo模型和认知推理引擎,实现了对连铸板坯缺陷的准确识别和定位,进一步提升了模型对连铸缺陷的认知和处理能力。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194529.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表