一种视频骨骼动作识别模型的训练方法及计算机设备
- 国知局
- 2024-07-31 22:53:13
本发明涉及计算机,具体是涉及一种视频骨骼动作识别模型的训练方法及计算机设备。
背景技术:
1、随着技术的发展,基于视觉的人类动作识别技术已经从利用单模态转变为利用多种模态来提高识别的准确性和鲁棒性,这些模态包括rgb图像、深度图像、骨骼信息、红外图像和点云数据等等,rgb图像能够提供丰富场景细节,包括物体的形状、颜色和纹理等,这些细节对于理解动作的语义内容至关重要,而骨骼信息能够有效排除背景干扰、专注捕捉动作的运动特征。
2、在处理视频数据时,时间信息的编码对于区分各种动作来说尤其关键,但时间维度的加入也给人类动作识别技术带来挑战,对此已有学者提出采用包括三维卷积神经网络、循环神经网络和长短期记忆网络在内的多种深度学习架构来编码视频数据中的时间信息,但是通常在处理复杂动作时面临局限性。后来有学者提出将transformer模型引入到人类动作识别领域以更好的处理序列数据,但因transformer模型的结构复杂,通常需要大量的计算资源来进行训练,导致高昂的计算成本和资源消耗,寻找更高效的训练方法和模型优化技术成为当前研究的重点内容。
技术实现思路
1、本发明提供一种视频骨骼动作识别模型的训练方法及计算机设备,以解决现有技术中存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
2、第一方面,提供一种视频骨骼动作识别模型的训练方法,所述视频骨骼动作识别模型包括块编码器、自注意力变换器和动作分类器,在所述自注意力变换器中引入由添加时间归纳偏置的自注意力机制、专家模态适配器和跨模态适配器搭建的参数高效微调框架,所述方法包括:
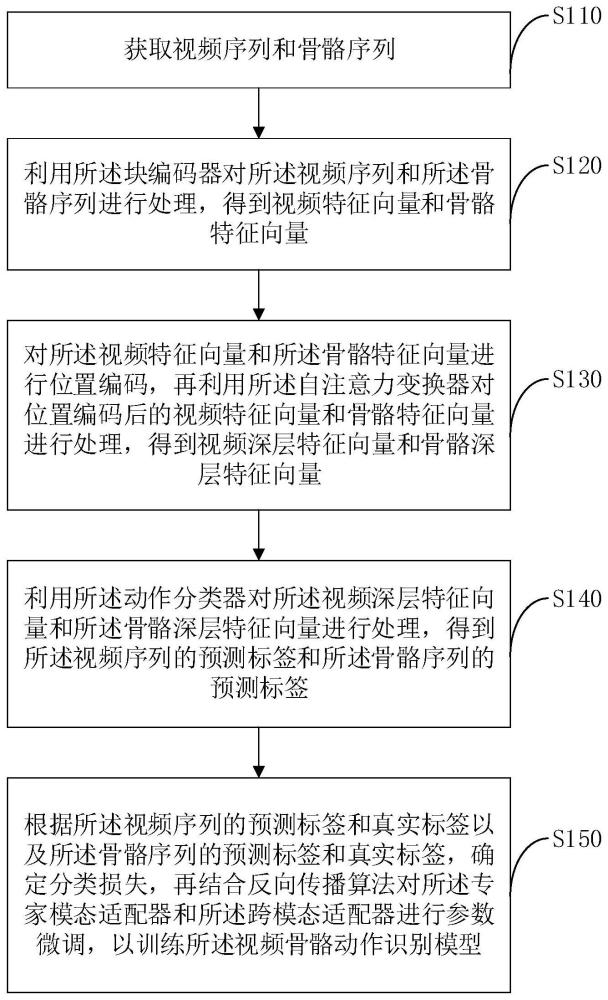
3、获取视频序列和骨骼序列;
4、利用所述块编码器对所述视频序列和所述骨骼序列进行处理,得到视频特征向量和骨骼特征向量;
5、对所述视频特征向量和所述骨骼特征向量进行位置编码,再利用所述自注意力变换器对位置编码后的视频特征向量和骨骼特征向量进行处理,得到视频深层特征向量和骨骼深层特征向量;
6、利用所述动作分类器对所述视频深层特征向量和所述骨骼深层特征向量进行处理,得到所述视频序列的预测标签和所述骨骼序列的预测标签;
7、根据所述视频序列的预测标签和真实标签以及所述骨骼序列的预测标签和真实标签,确定分类损失,再结合反向传播算法对所述专家模态适配器和所述跨模态适配器进行参数微调,以训练所述视频骨骼动作识别模型。
8、进一步地,所述获取视频序列和骨骼序列包括:
9、获取原始视频序列和原始骨骼序列;
10、对所述原始视频序列进行采样和数据增广,得到所述视频序列;
11、对所述原始骨骼序列进行采样和数据增广,得到所述骨骼序列。
12、进一步地,所述自注意力变换器包括顺次连接的若干个自注意力变换模块,每个自注意力变换模块包括视频特征提取模块、骨骼特征提取模块和跨模态适配器;
13、所述视频特征提取模块包括第一多层感知器、第一模态适配器以及由卷积模态适配器和基于部分时间感知的第一自注意力网络形成的第一注意力模块,所述骨骼特征提取模块包括第二多层感知器、第二模态适配器以及由图卷积模态适配器和基于部分时间感知的第二自注意力网络形成的第二注意力模块;
14、将输入视频特征向量进行层归一化之后依次通过所述第一注意力模块和所述第一模态适配器进行处理得到第一视频特征向量,将所述输入视频特征向量和所述第一视频特征向量进行相加得到第二视频特征向量,将所述第二视频特征向量进行层归一化得到第三视频特征向量,通过所述第一多层感知器对所述第三视频特征向量进行处理得到第四视频特征向量;
15、将输入骨骼特征向量进行层归一化之后依次通过所述第二注意力模块和所述第二模态适配器进行处理得到第一骨骼特征向量,将所述输入骨骼特征向量和所述第一骨骼特征向量进行相加得到第二骨骼特征向量,将所述第二骨骼特征向量进行层归一化得到第三骨骼特征向量,通过所述第二多层感知器对所述第三骨骼特征向量进行处理得到第四骨骼特征向量;
16、通过所述跨模态适配器对所述第三视频特征向量和所述第三骨骼特征向量进行交叉处理得到第五视频特征向量和第五骨骼特征向量,将所述第二视频特征向量、所述第四视频特征向量和所述第五骨骼特征向量进行相加得到视频深层特征向量,将所述第二骨骼特征向量、所述第四骨骼特征向量和所述第五视频特征向量进行相加得到骨骼深层特征向量。
17、进一步地,所述第一自注意力网络和所述第二自注意力网络的结构相同,任一自注意力网络包括多头自注意力层;
18、根据第一输入特征向量确定键矩阵、值矩阵和查询矩阵,通过所述多头自注意力层引入不同的时间掩码对所述键矩阵、所述值矩阵和所述查询矩阵进行处理得到多个注意力向量,再对所述多个注意力向量进行拼接和线性映射得到第一输出特征向量。
19、进一步地,所述卷积模态适配器包括第一激活函数、深度可分离卷积层、用于压缩特征维度的第一全连接层和用于扩展特征维度的第二全连接层;
20、将第一输入视频特征向量依次通过所述第一全连接层、所述第一激活函数、所述深度可分离卷积层和所述第二全连接层进行处理得到第六视频特征向量,将所述第一输入视频特征向量和所述第六视频特征向量进行相加得到第一输出视频特征向量。
21、进一步地,所述图卷积模态适配器包括第二激活函数、图卷积网络层、用于压缩特征维度的第三全连接层和用于扩展特征维度的第四全连接层;
22、将第一输入骨骼特征向量依次通过所述第三全连接层、所述第二激活函数、所述图卷积网络层和所述第四全连接层进行处理得到第六骨骼特征向量,将所述第一输入骨骼特征向量和所述第六骨骼特征向量进行相加得到第一输出骨骼特征向量。
23、进一步地,所述跨模态适配器包括第一交叉注意力层、第二交叉注意力层、第三交叉注意力层、第四交叉注意力层、第三模态适配器和第四模态适配器;
24、通过所述第一交叉注意力层对第二输入骨骼特征向量和可学习的第一变量进行处理得到第一交叉特征向量,所述第一变量表示视频模态的潜在空间特征,通过所述第二交叉注意力层对第二输入视频特征向量和所述第一交叉特征向量进行处理得到第七骨骼特征向量,通过所述第三模态适配器对所述第七骨骼特征向量进行处理得到第二输出骨骼特征向量;
25、通过所述第三交叉注意力层对所述第二输入视频特征向量和可学习的第二变量进行处理得到第二交叉特征向量,所述第二变量表示骨骼模态的潜在空间特征,通过所述第四交叉注意力层对所述第二输入骨骼特征向量和所述第二交叉特征向量进行处理得到第七视频特征向量,通过所述第四模态适配器对所述第七视频特征向量进行处理得到第二输出视频特征。
26、进一步地,所述第一模态适配器、所述第二模态适配器、所述第三模态适配器和所述第四模态适配器的结构相同,任一模态适配器包括第三激活函数、用于压缩特征维度的第五全连接层和用于扩展特征维度的第六全连接层;
27、将第二输入特征向量依次通过所述第五全连接层、所述第三激活函数和所述第六全连接层进行处理得到中间特征向量,将所述第二输入特征向量和所述中间特征向量进行相加得到第二输出特征向量。
28、进一步地,所述方法还包括:
29、获取用户在运动过程中对应的待测视频序列和待测骨骼序列;
30、利用训练好的视频骨骼动作识别模型对所述待测视频序列和所述待测骨骼序列进行处理,得到所述用户的动作类别信息。
31、第二方面,提供一种计算机设备,包括存储器和处理器,所述存储器上存储计算机程序,所述处理器执行所述计算机程序以实现如第一方面所述的视频骨骼动作识别模型的训练方法。
32、本发明至少具有以下有益效果:通过在模型的原有空间自注意力中添加时间归纳偏置以构建基于部分时间感知的自注意力网络,可以有效提高原有空间自注意力提取时间信息的能力;通过在模型中设置不同的专家模态适配器以对不同模态进行特征提取,以及在模型中设置跨模态适配器来实现视频模态和骨骼模态之间的特征迁移学习,可以提高模型识别动作的准确性和鲁棒性;通过在模型中引入由添加时间归纳偏置的自注意力机制、专家模态适配器和跨模态适配器所构建的参数高效微调框架,可以减少在模型训练时的资源消耗。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195181.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表