一种自适应深度编码的多视图稀疏查询3D目标检测方法
- 国知局
- 2024-07-31 22:55:37
本发明涉及基于图像的3d目标检测领域,具体涉及一种自适应深度编码的多视图稀疏查询3d目标检测方法。
背景技术:
1、近些年来,自动驾驶领域高速发展,由于摄像头比激光雷达造价低廉,基于图像的自动驾驶感知算法引起了学术界和工业界的广泛关注。其中基于图像实现的3d目标检测是3d场景理解中的一项基本任务,旨在定位当前场景中物体的边界框和预测物体分类。
2、早期的一些基于图像的3d目标检测方法是在单目图像上进行的,在每个图像上独立检测后聚合结果。然而,这些方法需要关注相邻图像中关注的区域,并且对每幅图像的检测结果进行融合,可能会导致性能不佳和计算开销较大。
3、近年来的一些方法通过将多视图和透视变换结合,生成鸟瞰图视角,并在鸟瞰图视角上完成3d目标检测,这有效缓解了因为遮挡产生的漏检、误检问题。但由于真实自动驾驶场景复杂多变,使得基于图像的3d目标检测任务仍面临着很多挑战。
4、目前的3d目标检测方法通常利用多个摄像机,可分为两类。其中,基于lift-spat-shoot (lss)的方法通过引入多幅图像的深度概率分布,将图像空间转换为明确的统一鸟瞰图(bev)空间。但由于显式bev特征的生成严重依赖深度图预测的准确性,可能会降低3d空间中物体的定位精度。另一种方法是基于transformer的方法,如南京大学的bevforemer,旷视科技的petr,他们都遵循端到端的方式实现3d目标检测。这些方法不涉及显式的视图变换,如投影或提升操作,而可以根据设定的查询的密度进一步分为两类:基于密集查询的方法和基于稀疏查询的方法。基于密集查询的3d目标检测器构建预定义的密集bev网格特征,并执行查询和2d图像特征之间的交互。然而,由于大量的查询和复杂的2d到3d视图转换,基于密集查询的检测器存在一些不可避免的缺点,如计算成本高和推理慢。此外,密集查询特征提取也需要额外的部署工作。基于稀疏查询的检测器消除了构造密集bev表示或采用任何投影操作的必要性。相反,它们利用3d位置编码(pe)来编码3d位置信息,以获得更好的空间感知。但是在在基于稀疏查询的检测器中,物体查询的粗糙3d pe会降低检测性能,需要进行进一步增强。
技术实现思路
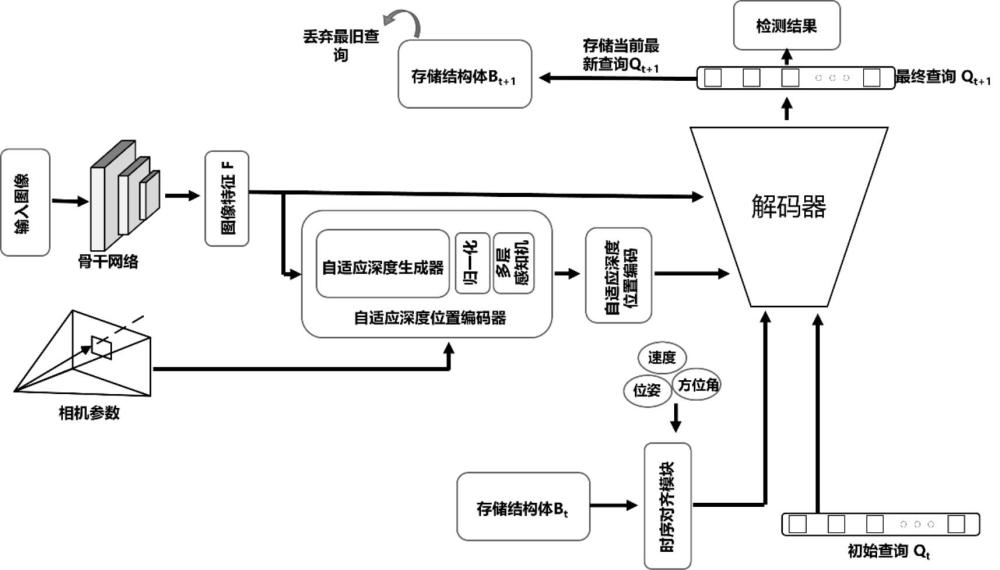
1、为解决上述技术问题,本发明提供一种自适应深度编码的多视图稀疏查询3d目标检测方法,提出一种自适应深度位置编码器,根据自适应深度图生成更细腻的位置编码,增强特征的表征与区分能力;本发明提出一种时序融合方法,利用一个遵循“先进先出”的存储结构体,存储历史帧信息,并和当前帧信息在解码器中完成时序融合;本发明还提出一种时序对齐模块,通过风格迁移策略将历史帧信息对齐到当前时刻,增强历史信息融合。
2、为达到上述目的,本发明采用如下的技术方案:
3、一种自适应深度编码的多视图稀疏查询3d目标检测方法,包括如下步骤:
4、step1:输入环绕车身的n张图像;
5、step2:对输入的n张环绕车身的图像进行特征提取,通过特征提取骨干网络进行特征提取,得到多尺度多视角特征;
6、step3:将提取到的多尺度多视角特征送入自适应深度生成器生成自适应的深度间隔和深度概率,再将深度间隔中点和深度概率相乘求和得到自适应深度图,具体计算如下:
7、;
8、其中,代表在像素平面坐标为位置下的深度值,,是第j个深度间隔中点,为在像素平面坐标为位置下的第j个深度间隔的深度概率,r代表实数域,l代表预定义的深度间隔数量;
9、step4:将自适应深度图结合相机内、外参数,结合图像平面坐标,转换到3d空间坐标系,生成三维坐标,并利用多层感知机生成自适应的位置编码嵌入向量;
10、step5:将位置编码嵌入向量与step2中获得的多尺度多视角特征结合,送入解码器得到稀疏的查询结果;
11、step6:将稀疏的查询结果送入定位检测头和分类检测头,定位出3d物体边界框,并预测出物体类别;
12、step7:利用遵循先进先出原则的存储结构体存储历史帧信息,减少计算消耗的同时融合信息;
13、step8:对step7中的存储结构体采用风格迁移策略,建立时序对齐模块,将存储的历史信息对齐到当前时刻,实现时序融合。
14、有益效果:
15、1)本发明提出一种自适应深度位置编码方法,通过精细的深度图生成更细腻的位置编码,增强场景特征理解,使得检测结果更加优异。
16、2)本发明提出一种时序融合方法,利用“先进先出”的规则保存固定合适长度的历史信息,减少计算消耗的同时可以融合信息,得到更稳定的效果。
17、3)本发明提出一种时序对齐模块,本模块利用风格迁移,将历史帧的信息结合当前帧的车辆姿态、速度等参考量,在高维空间对齐到当前时刻特征,有利于时序融合。
技术特征:1.一种自适应深度编码的多视图稀疏查询3d目标检测方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的一种自适应深度编码的多视图稀疏查询3d目标检测方法,其特征在于,所述step3包括:
3.根据权利要求2所述的一种自适应深度编码的多视图稀疏查询3d目标检测方法,其特征在于,得到自适应深度图后,再结合图像平面坐标与相机内、外参数,转换到3d空间得到具体的点,表示如下:
4.根据权利要求1所述的一种自适应深度编码的多视图稀疏查询3d目标检测方法,其特征在于,所述step7包括:
5.根据权利要求4所述的一种自适应深度编码的多视图稀疏查询3d目标检测方法,其特征在于,所述step8包括:
技术总结本发明提供一种自适应深度编码的多视图稀疏查询3D目标检测方法,属于基于图像的3D目标检测领域,输入环绕车身的N张图像,通过特征提取骨干网络进行特征提取,得到多尺度多视角特征。将提取到的特征送入自适应深度生成器生成自适应的深度间隔和深度概率,并计算每个深度间隔对应的中点,再将深度间隔中点和深度概率相乘求和得到自适应深度图。将自适应深度图结合相机内、外参数转换到3D空间坐标系,利用多层感知机生成自适应的位置编码嵌入向量。将嵌入向量与之前提取到的图像特征相加,送入解码器得到稀疏的查询结果。将查询结果送入定位检测头和分类检测头,分别定位出3D物体边界框和预测出物体类别。本发明使得检测结果更加优异。技术研发人员:凌强,令狐俊杰受保护的技术使用者:中国科学技术大学技术研发日:技术公布日:2024/7/29本文地址:https://www.jishuxx.com/zhuanli/20240730/195354.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。